You will get AWS SageMaker Cost Audit — Find & Fix Overspending
Project details
Most ML teams overspend on SageMaker by 40–60% —
idle endpoints, over-provisioned instance families,
and unmonitored training jobs silently drain budgets
every month. I find exactly where your money is going
and tell you how to get it back.
What you get:
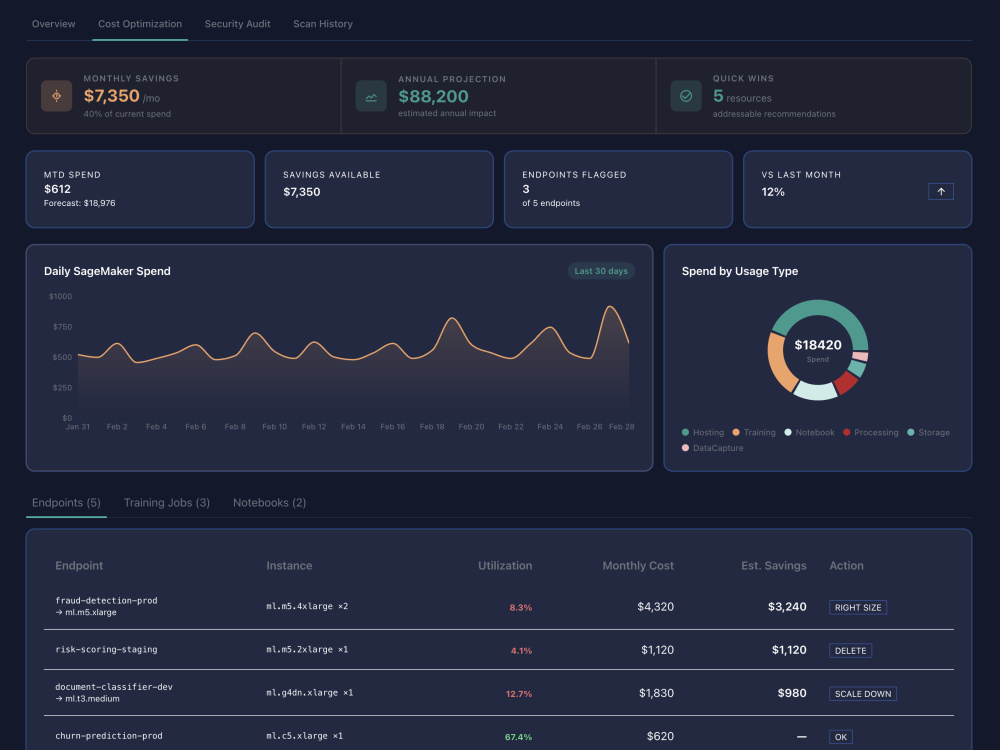
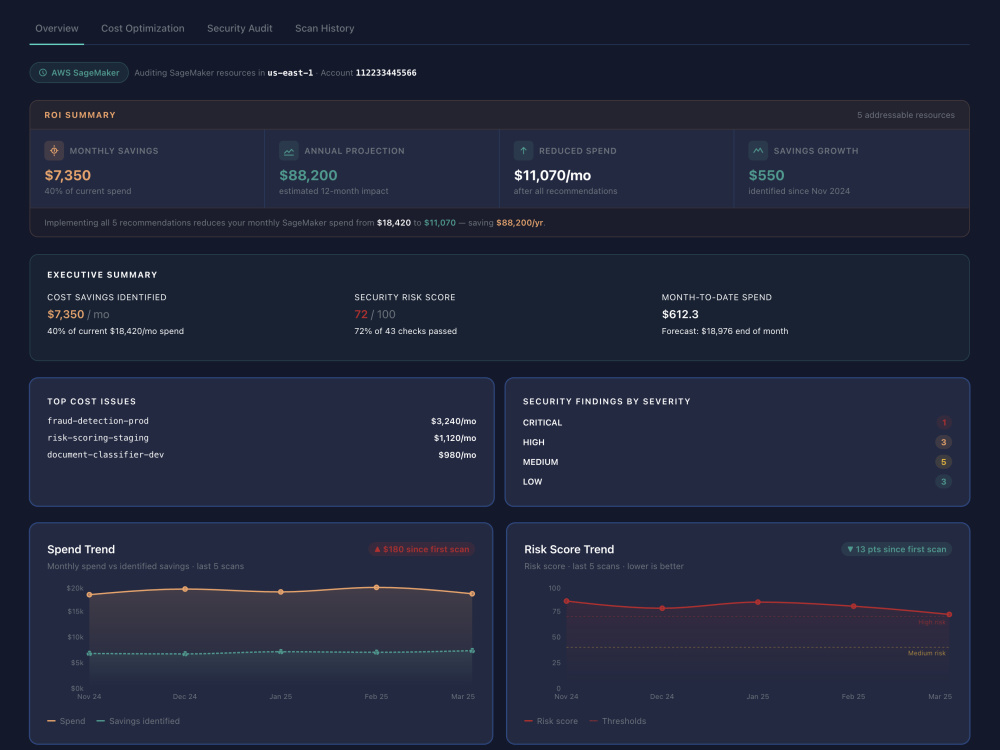
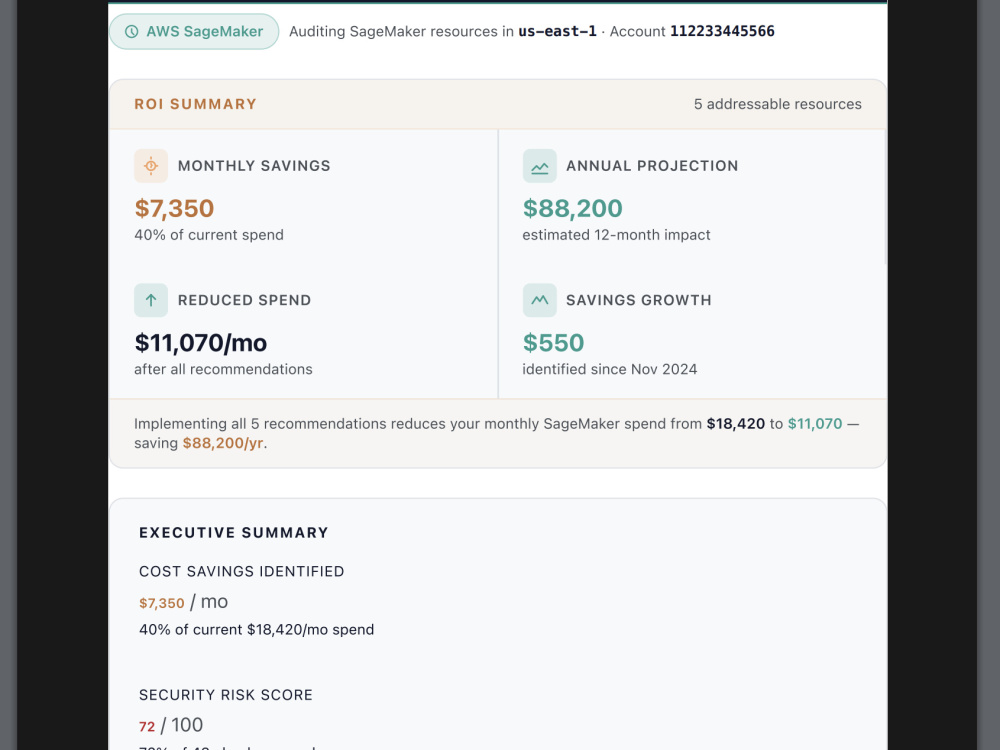
• Live cost dashboard with endpoint utilization,
training job analysis, and notebook waste findings
• Exportable PDF findings report with severity
rankings and savings estimates
• Single AWS account review (additional accounts available)
• 30-minute findings walkthrough call
Delivered in 5 business days (Optional Add-ons may require more time)
idle endpoints, over-provisioned instance families,
and unmonitored training jobs silently drain budgets
every month. I find exactly where your money is going
and tell you how to get it back.
What you get:
• Live cost dashboard with endpoint utilization,
training job analysis, and notebook waste findings
• Exportable PDF findings report with severity
rankings and savings estimates
• Single AWS account review (additional accounts available)
• 30-minute findings walkthrough call
Delivered in 5 business days (Optional Add-ons may require more time)
AI Development Type
Model Tuning, Software MaintenanceAI Tools
Amazon SageMaker, MLflowAI Development Language
PythonWhat's included $2,500
These options are included with the project scope.
$2,500
- Delivery Time 5 days
- Number of Revisions 1
- Model Documentation
Optional add-ons
You can add these on the next page.
Fast 2 Days Delivery
+$500
Findings presentation
(+ 1 Day)
+$250
Second AWS account
(+ 2 Days)
+$500
Remediation support
(+ 2 Days)
+$750Frequently asked questions
About Jose
AI Engineer | LLM Apps, AWS, MLOps | Scalable & Cost-Efficient Systems
Las Vegas, United States - 10:17 am local time
I help companies build and scale AI systems that are reliable, secure, and cost-efficient from day one.
Whether you're building an LLM-powered app, deploying models on AWS, or fixing a system that isn’t performing as expected — I focus on making sure it actually works in real-world conditions.
What I can help you with:
• AI / LLM applications (RAG systems, chatbots, APIs)
• Backend development for AI systems (FastAPI, Django)
• Deploying and scaling models on AWS (SageMaker, ECS, EKS)
• MLOps pipelines (CI/CD, automation, monitoring)
• Performance optimization and cost control
• Securing AI systems (VPC, IAM, encryption)
Recent outcomes:
• Built and deployed scalable AI backends for production use
• Reduced infrastructure costs by 30–50%
• Reduced inference endpoint costs by 40% through autoscaling + right-sizing
• Improved performance and reliability of deployed systems
Tech stack:
Python, pandas, FastAPI, Django, AWS (SageMaker, Lambda, ECS, EKS, Bedrock), Terraform, Docker, PostgreSQL
If you're building an AI product and want it to actually scale and perform — I can help.
Happy to review your current setup and point out quick wins before any engagement.
Steps for completing your project
After purchasing the project, send requirements so Jose can start the project.
Delivery time starts when Jose receives requirements from you.
Jose works on your project following the steps below.
Revisions may occur after the delivery date.
Kickoff (Day 1)
30-minute call to confirm scope, priorities, and access requirements. You grant read-only IAM access using our setup guide — takes under 10 minutes to configure.
Environment Inventory (Day 1–2)
We inventory all SageMaker resources in your account — endpoints, training jobs, notebook instances, pipelines, and supporting compute. CloudWatch utilization data is pulled for the preceding 30 days.