You will get Azure End-to-End ETL Pipeline using ADF & Databricks
Project details
I am a professional Azure Data Engineer with 4+ years of enterprise experience, delivering scalable and reliable ETL solutions for banking and healthcare domains.
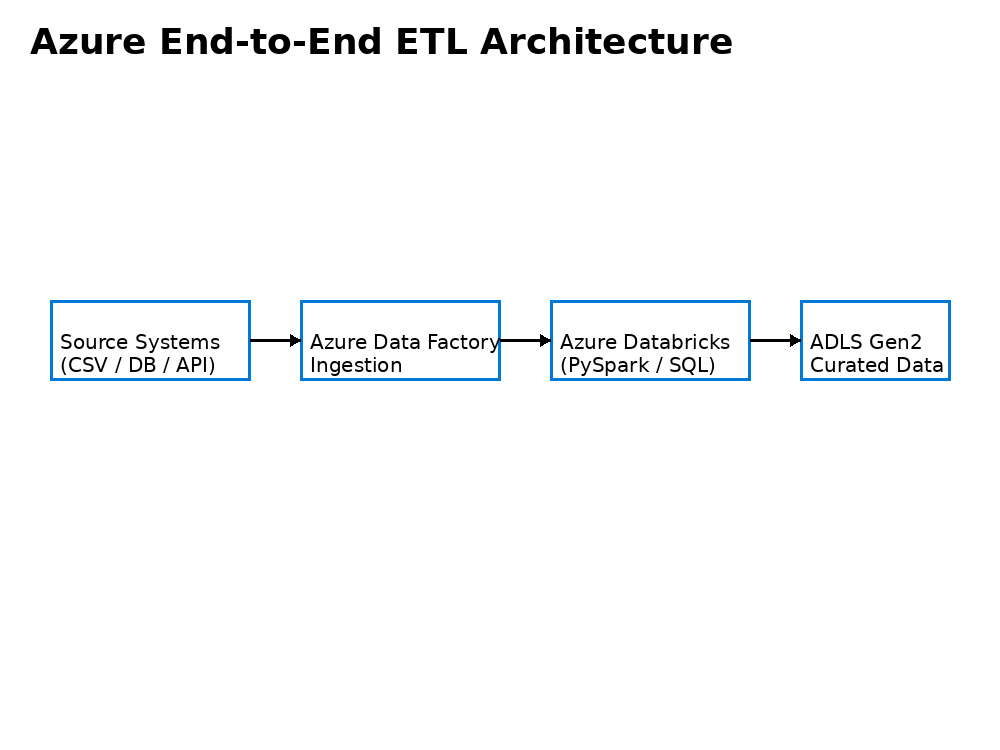
In this project, you will get a complete end-to-end Azure ETL pipeline designed using Azure Data Factory, Azure Databricks (PySpark/SQL), and Azure Data Lake Storage. The solution is built with a strong focus on data quality, performance, scalability, and long-term maintainability.
I follow industry best practices to ensure:
Clean and modular pipeline design
Efficient data ingestion from multiple sources
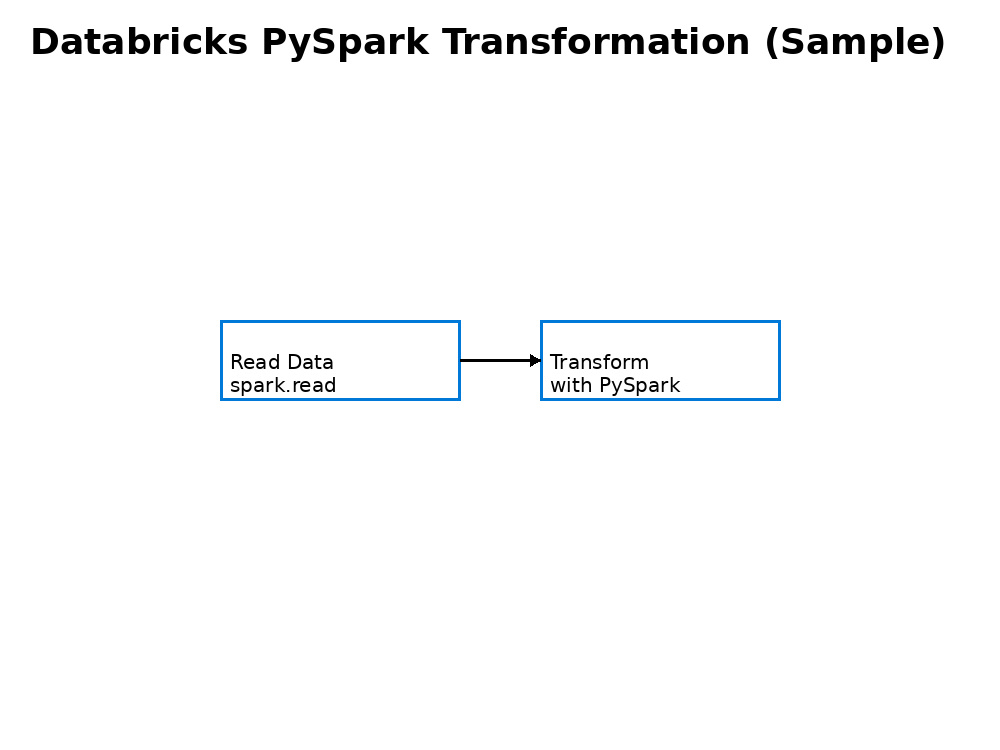
Optimized transformations using PySpark and SQL
Robust error handling and logging
Analytics-ready datasets for reporting and BI
I have worked on large enterprise platforms at Accenture and EY, where reliability, compliance, and performance are critical. The same standards are applied to every project I deliver on Upwork.
Whether you are a startup, growing business, or enterprise, this service helps you turn raw data into trusted, actionable insights using Azure’s modern data stack.
In this project, you will get a complete end-to-end Azure ETL pipeline designed using Azure Data Factory, Azure Databricks (PySpark/SQL), and Azure Data Lake Storage. The solution is built with a strong focus on data quality, performance, scalability, and long-term maintainability.
I follow industry best practices to ensure:
Clean and modular pipeline design
Efficient data ingestion from multiple sources
Optimized transformations using PySpark and SQL
Robust error handling and logging
Analytics-ready datasets for reporting and BI
I have worked on large enterprise platforms at Accenture and EY, where reliability, compliance, and performance are critical. The same standards are applied to every project I deliver on Upwork.
Whether you are a startup, growing business, or enterprise, this service helps you turn raw data into trusted, actionable insights using Azure’s modern data stack.
Database Type
PostgreSQL, Azure Cosmos DBWhat's included
| Service Tiers |
Starter
$75
|
Standard
$150
|
Advanced
$300
|
|---|---|---|---|
| Delivery Time | 3 days | 5 days | 7 days |
Number of Revisions | 1 | 2 | 3 |
Number of Tables Added | 1 | 3 | 5 |
Schema Diagram | - | ||
Permissions Setup | - | - | |
Import/Export Data | |||
Admin Panel Setup | - | - | - |
Optional add-ons
You can add these on the next page.
Additional Revision
+$50
Additional Table Added
+$50
Schema Diagram
+$50
Performance Optimization
+$50Frequently asked questions
About Pratap
Azure Data Engineer | Databricks | Synapse | Microsoft Fabric|Power BI
Noida, India - 1:17 pm local time
I specialize in Azure Data Factory, Azure Databricks (PySpark & SQL), Azure Synapse, Data Lake, and Microsoft Fabric (Lakehouse, Dataflow Gen2). I have delivered end-to-end ETL solutions—from data ingestion and transformation to analytics-ready datasets and Power BI dashboards.
At Accenture and EY, I worked on large-scale enterprise data platforms, integrating data from multiple heterogeneous sources, improving pipeline performance by up to 35–50%, and implementing CI/CD using Azure DevOps and GitHub Actions.
What I can help you with:
End-to-end ETL & ELT pipelines in Azure
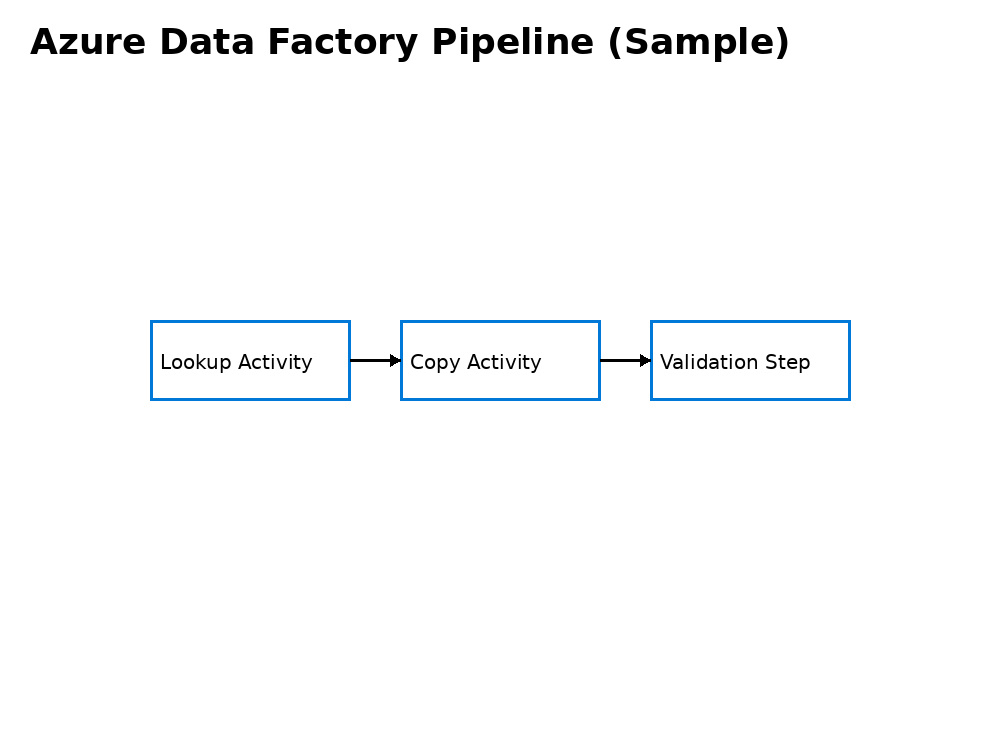
Azure Data Factory (ADF) pipeline design & optimization
Databricks (PySpark / SQL) transformations
Azure Synapse & Data Lake architecture
Microsoft Fabric (Lakehouse, Dataflow Gen2)
Data validation, error handling & monitoring
Power BI data models & dashboards
Migration from on-prem or legacy systems to Azure
I focus on clean architecture, performance, data quality, and clear communication. My goal is not just to build pipelines, but to deliver reliable, business-ready data solutions.
Let’s discuss how I can help you turn your data into actionable insights.
Steps for completing your project
After purchasing the project, send requirements so Pratap can start the project.
Delivery time starts when Pratap receives requirements from you.
Pratap works on your project following the steps below.
Revisions may occur after the delivery date.
Requirement Analysis & Planning
Review data sources, understand business requirements, and design the Azure ETL architecture.
Data Ingestion using Azure Data Factory
Build ADF pipelines to ingest data from source systems into Azure Data Lake with proper monitoring.