You will get Hybrid RAG Pipeline — Private Internal Document Q&A (No Data Leaks)

Project details
Most RAG systems fail in production — not in demos. They retrieve wrong chunks, hallucinate when context is weak, and can't explain why they got the answer wrong.
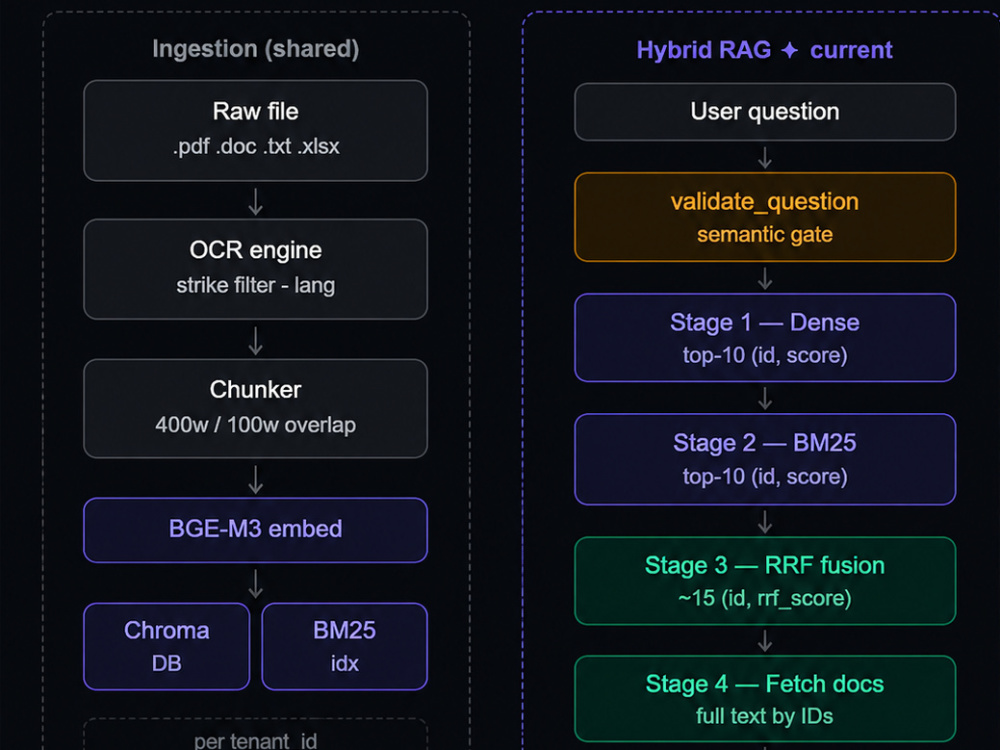
I build a different kind of RAG system: one that combines semantic search + keyword search, fuses them with RRF, reranks with a cross-encoder, manages token budgets, and scores confidence before generating — all running locally via Ollama. No data leaves your server.
What you get:
Accurate Q&A over your internal PDFs, DOCX, and XLSX files
Hybrid retrieval (BGE-M3 dense + BM25 sparse) for higher recall than vector-only search
Cross-encoder reranking — cuts irrelevant chunks before the LLM ever sees them
Confidence scoring — the system knows when it doesn't know
Semantic question validation — filters noise before retrieval starts
REST API endpoint ready to integrate into your stack
Full source code + Docker setup + documentation
Perfect for: Teams with sensitive internal docs who can't send data to OpenAI. Legal, healthcare, finance, or any on-premise requirement.
Not a prototype. Not a tutorial clone. A pipeline built for production.
I build a different kind of RAG system: one that combines semantic search + keyword search, fuses them with RRF, reranks with a cross-encoder, manages token budgets, and scores confidence before generating — all running locally via Ollama. No data leaves your server.
What you get:
Accurate Q&A over your internal PDFs, DOCX, and XLSX files
Hybrid retrieval (BGE-M3 dense + BM25 sparse) for higher recall than vector-only search
Cross-encoder reranking — cuts irrelevant chunks before the LLM ever sees them
Confidence scoring — the system knows when it doesn't know
Semantic question validation — filters noise before retrieval starts
REST API endpoint ready to integrate into your stack
Full source code + Docker setup + documentation
Perfect for: Teams with sensitive internal docs who can't send data to OpenAI. Legal, healthcare, finance, or any on-premise requirement.
Not a prototype. Not a tutorial clone. A pipeline built for production.
AI Algorithms
Large Language Model, Transformer ModelAI Applications
AI Chatbot, Conversational AIAI Development Language
PythonAI Tools
Hugging FaceAI Models
BERT, ChatGPT, LLaMAWhat's included
| Service Tiers |
Starter
$299
|
Standard
$499
|
Advanced
$799
|
|---|---|---|---|
| Delivery Time | 5 days | 7 days | 10 days |
Number of Revisions | 1 | 2 | 3 |
AI Model Integration | |||
Batch Normalization | - | - | - |
Database Integration | - | ||
Detailed Code Comments | - | - | - |
Image Upscaling | - | - | - |
MLOps | - | - | - |
Model Deployment | - | - | |
Model Documentation | |||
Model Monitoring | - | - | - |
Model Testing & Optimization | - | ||
Model Tuning | - | - | - |
Natural Language Processing | |||
NLP Tokenization | - | ||
Pre-Training | - | - | - |
Prompt Engineering | - | - | |
Setup File | |||
Source Code |
Optional add-ons
You can add these on the next page.
Fast Delivery
+$50
Multilingual Support (EN/VN/JP)
(+ 2 Days)
+$149
30-min Walkthrough & Q&A Call
+$99Frequently asked questions
About Hai
AI Apps & Integration | AI Integration APIs & Tools, OpenAI API
Ho Chi Minh City, Vietnam - 11:34 pm local time
Whether you require chatbots to streamline workflows, or robust dashboards to visualize your data, I design systems that are clean, efficient, and production-ready from day one. My goal is to eliminate repetitive tasks and connect fragmented platforms, giving you clarity and control over your operations. If you’re looking for a partner who can translate your challenges into actionable solutions, let's discuss how I can help elevate your project.
Steps for completing your project
After purchasing the project, send requirements so Hai can start the project.
Delivery time starts when Hai receives requirements from you.
Hai works on your project following the steps below.
Revisions may occur after the delivery date.
Requirements & Document Collection
Gather your documents (PDF/DOCX) and clarify the use case — what questions users will ask, expected response format, and deployment environment.
Pipeline Setup & Document Ingestion
Set up the RAG pipeline: chunk documents, generate embeddings (BGE-M3), index into ChromaDB, and configure BM25 for hybrid search.