You will get clean CSV or Excel data from PDFs, APIs, or websites
Rising Talent
Rising Talent
Project details
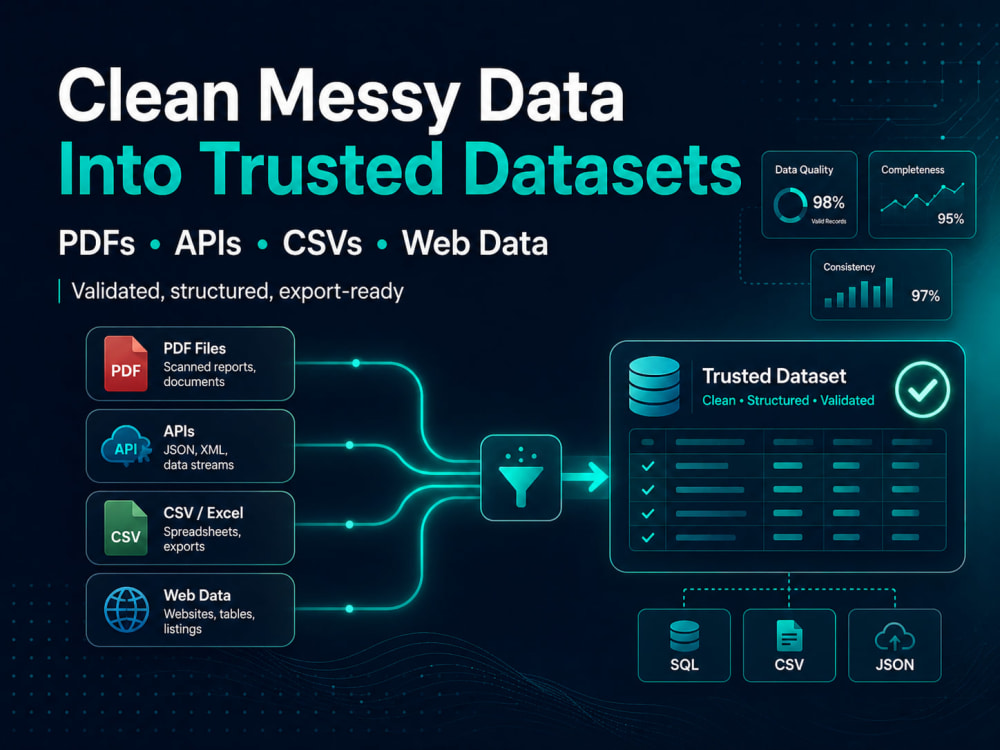
Messy data slows down reporting, sales, research, analytics, and AI work.
If your data is stuck in PDFs, websites, APIs, CSV files, Excel sheets, or business documents, I can turn it into a clean and usable dataset.
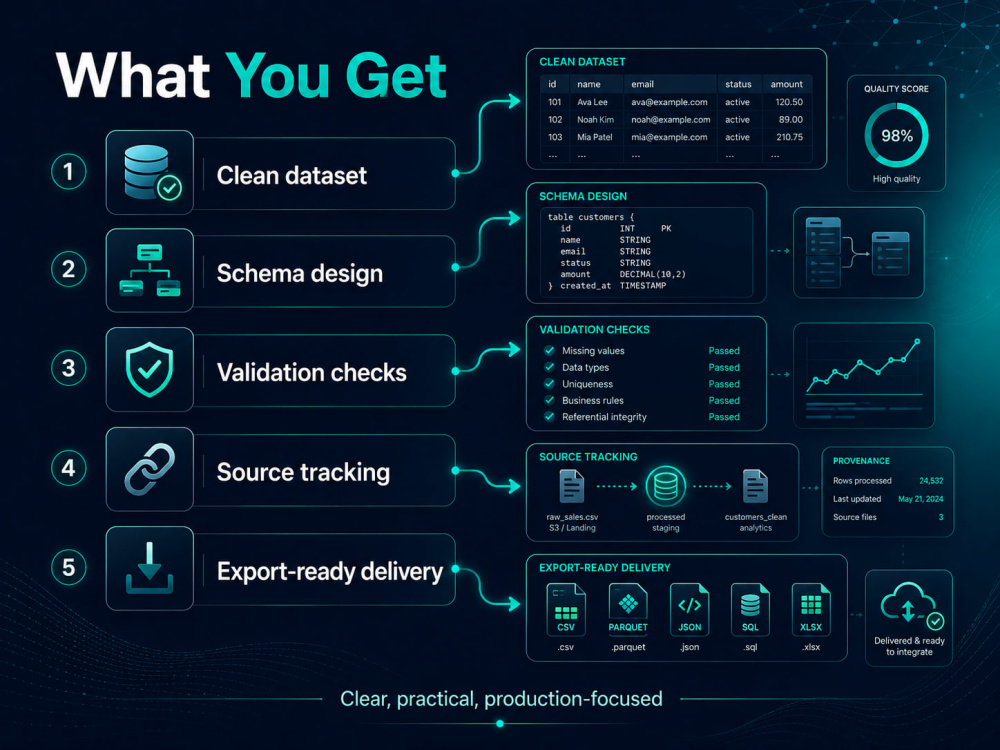
I focus on clean structure, duplicate removal, validation checks, source tracking where possible, and delivery in a format your team can use immediately.
This is useful for business reporting, market research, lead lists, product data, analytics, AI dataset preparation, and internal operations.
You will receive a clean dataset with clear columns, organized records, and notes on any uncertain or missing fields.
If your data is stuck in PDFs, websites, APIs, CSV files, Excel sheets, or business documents, I can turn it into a clean and usable dataset.
I focus on clean structure, duplicate removal, validation checks, source tracking where possible, and delivery in a format your team can use immediately.
This is useful for business reporting, market research, lead lists, product data, analytics, AI dataset preparation, and internal operations.
You will receive a clean dataset with clear columns, organized records, and notes on any uncertain or missing fields.
Data Tool
PythonWhat's included
| Service Tiers |
Starter
$150
|
Standard
$450
|
Advanced
$950
|
|---|---|---|---|
| Delivery Time | 2 days | 5 days | 10 days |
Number of Revisions | 1 | 2 | 3 |
Frequently asked questions
About Shitanshu
Expert Data Platform Engineer | Airflow, Spark, AWS, ETL, MLOps
New Delhi, India - 5:41 am local time
🏅 DeepLearning.AI Data Engineering Professional Certificate, AWS
🏅 IBM Data Engineering Professional Certificate
🏅 PyTorch for Deep Learning Professional Certificate
I help businesses turn messy data into reliable, tested, and production-ready data systems.
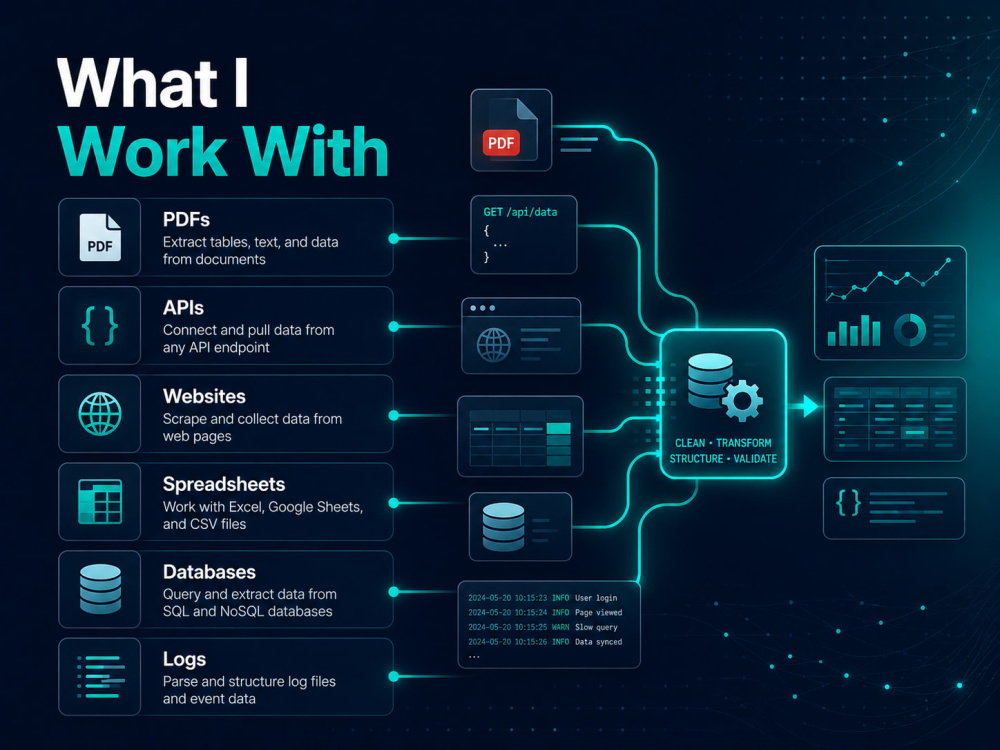
If your data is scattered across APIs, databases, files, PDFs, cloud storage, dashboards, or ML workflows, I can help you build pipelines and datasets your team can trust.
My focus is simple:
🎯 Reliable data pipelines
🎯 Clean and validated datasets
🎯 Airflow and Spark workflows
🎯 Cloud data jobs on AWS and Azure
🎯 Data quality checks and documentation
🎯 Monitoring, reliability, and handover
🎯 ML-ready datasets and MLOps support when needed
I work with Python, SQL, Apache Airflow, Apache Spark, Kafka, dbt, Docker, Terraform, Snowflake, AWS, Azure, Databricks, PostgreSQL, MySQL, MongoDB, MLflow, and PyTorch.
How I can help:
🚀 Build ETL and ELT data pipelines
🚀 Create Airflow DAGs and workflow orchestration
🚀 Build Spark, AWS Glue, and cloud data jobs
🚀 Clean, transform, and validate messy data
🚀 Create analytics-ready datasets
🚀 Design data lake and lakehouse workflows
🚀 Add data quality checks and testing
🚀 Improve failed or fragile pipelines
🚀 Prepare ML-ready datasets
🚀 Support MLflow, FastAPI, and model monitoring workflows
What makes my work different:
I do not just write scripts. I build data systems that are clean, repeatable, documented, and easier for your team to operate.
My goal is to help you reduce manual fixes, avoid bad-data surprises, improve trust in reports, and make better business or ML decisions from reliable data.
Good first projects:
✅ Audit and improve an existing data pipeline
✅ Clean messy PDFs, APIs, CSVs, or web data into a trusted dataset
✅ Set up MLflow, FastAPI, and monitoring for an ML workflow
✅ Build a small production-ready data pipeline MVP
If you need a reliable Data Platform Engineer who can turn messy data into clean, tested, and usable systems, I would be happy to help!
Steps for completing your project
After purchasing the project, send requirements so Shitanshu can start the project.
Delivery time starts when Shitanshu receives requirements from you.
Shitanshu works on your project following the steps below.
Revisions may occur after the delivery date.
Review data sources
I review your files, APIs, websites, sample records, required fields, and final dataset goal.
Design the structure
I define the dataset schema, cleaning rules, validation checks, and expected export format.