You will get Custom RAG System with FastAPI & Vector Database for AI Search



Project details
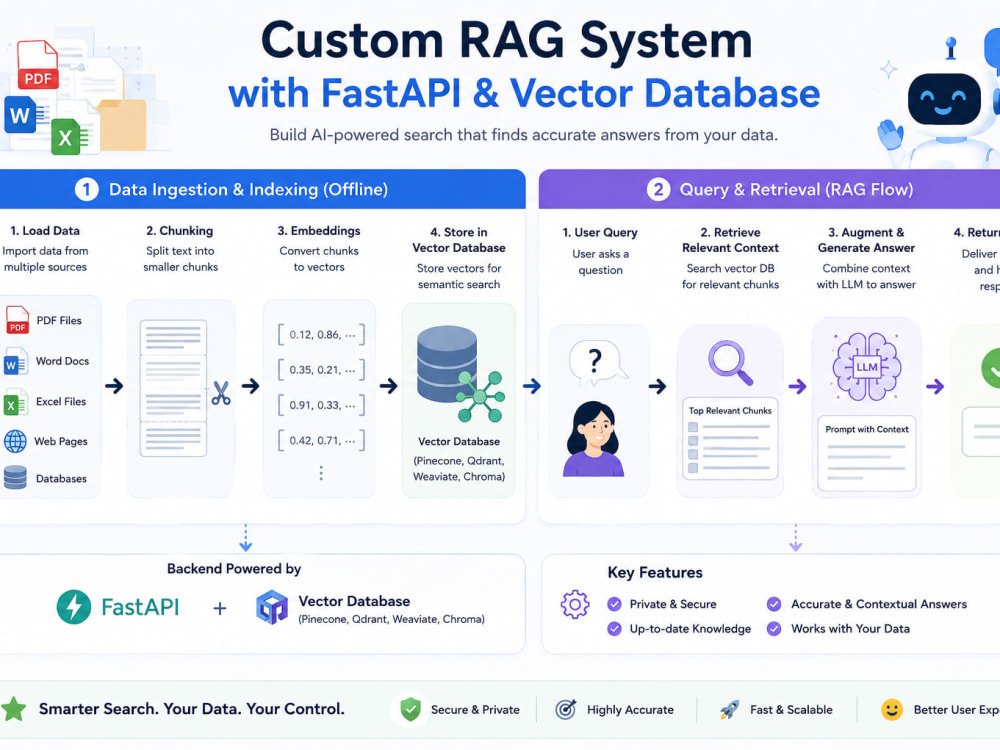
You will get a production-ready Retrieval-Augmented Generation (RAG) system that allows you to query your documents and data using modern Large Language Models.
I design and build custom RAG pipelines using FastAPI, vector databases, and state-of-the-art LLMs to deliver accurate, explainable, and scalable AI search solutions. This is not a demo or prototype — it is a clean, well-structured backend suitable for real-world use.
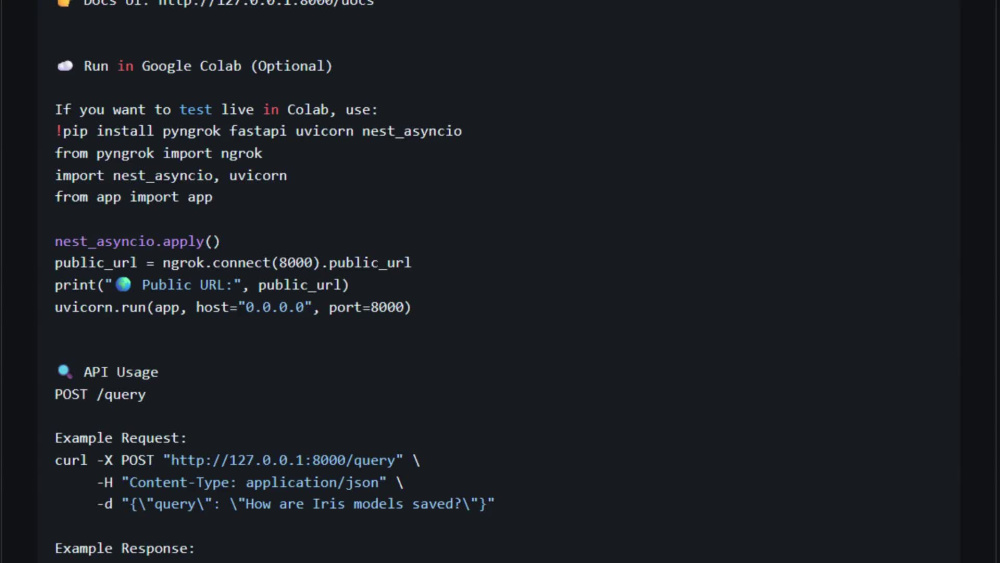
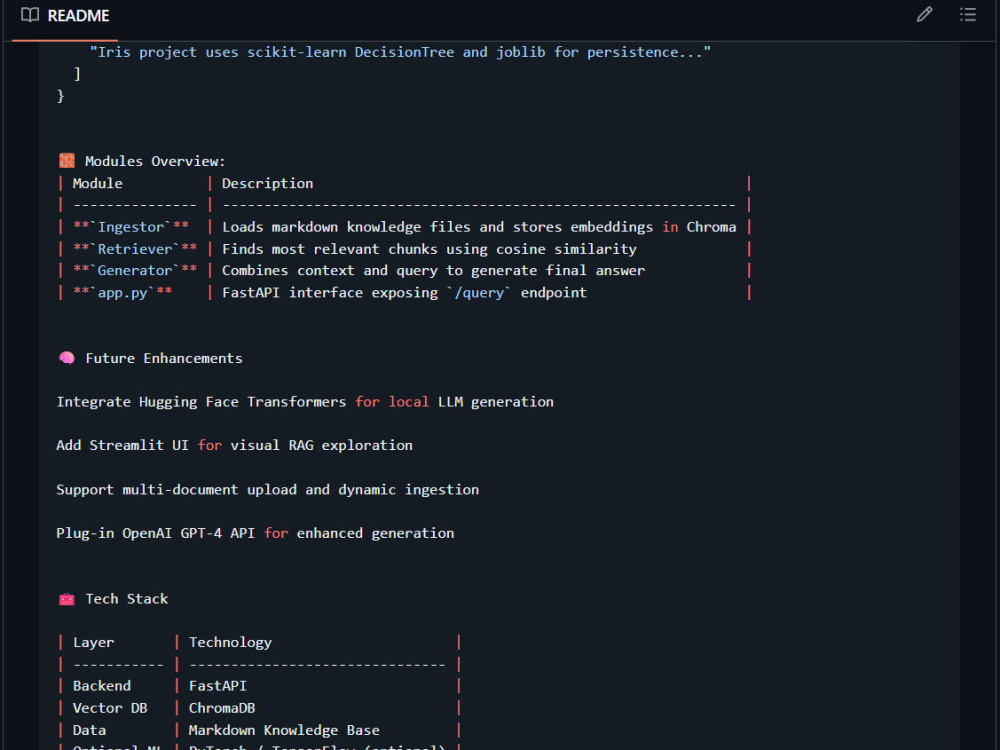
The system supports document ingestion, embedding generation, vector indexing, and intelligent retrieval combined with LLM responses. It can be delivered as an API, local setup, or cloud-ready service with clear documentation.
My focus is on reliability, clean architecture, and measurable retrieval quality — ensuring your AI system produces relevant answers instead of hallucinations.
This service is ideal for startups, internal tools, knowledge bases, customer support systems, and AI-powered search applications.
I design and build custom RAG pipelines using FastAPI, vector databases, and state-of-the-art LLMs to deliver accurate, explainable, and scalable AI search solutions. This is not a demo or prototype — it is a clean, well-structured backend suitable for real-world use.
The system supports document ingestion, embedding generation, vector indexing, and intelligent retrieval combined with LLM responses. It can be delivered as an API, local setup, or cloud-ready service with clear documentation.
My focus is on reliability, clean architecture, and measurable retrieval quality — ensuring your AI system produces relevant answers instead of hallucinations.
This service is ideal for startups, internal tools, knowledge bases, customer support systems, and AI-powered search applications.
AI Algorithms
Large Language Model, Multimodal Large Language Model, Transformer ModelAI Applications
AI Chatbot, AI Content Creation, AI-Generated Code, Conversational AIAI Development Language
PythonAI Tools
Azure OpenAI, Gradio, Hugging Face, NVIDIA AI Platform, PyTorch, Streamlit, TensorFlowAI Models
BERT, BLOOM, ChatGPT, Dolly, GPT-4What's included
| Service Tiers |
Starter
$199
|
Standard
$399
|
Advanced
$749
|
|---|---|---|---|
| Delivery Time | 5 days | 7 days | 10 days |
Number of Revisions | 2 | 3 | 4 |
AI Model Integration | |||
Batch Normalization | - | - | - |
Database Integration | |||
Detailed Code Comments | - | ||
Image Upscaling | - | - | - |
MLOps | - | - | |
Model Deployment | - | - | |
Model Documentation | - | - | |
Model Monitoring | - | - | |
Model Testing & Optimization | - | ||
Model Tuning | - | - | - |
Natural Language Processing | - | ||
NLP Tokenization | - | - | - |
Pre-Training | - | - | - |
Prompt Engineering | - | ||
Setup File | |||
Source Code |
Frequently asked questions
About Shankar
Full-Stack AI Engineer | AI Agents | LLM, RAG & FastAPI | AI Systems
Delhi, India - 12:20 am local time
I work across the complete AI stack: frontend, backend, AI orchestration, APIs, databases, vector search, deployment, monitoring, and scalable infrastructure. Whether you need a simple automation tool or a complex multi-agent AI platform, I can design, build, optimize, and deploy the entire system end-to-end.
I specialize in creating reliable AI products that are scalable, maintainable, and ready for real-world business usage, not just prototypes.
What I can build
• Custom AI Agents & Autonomous Workflows
• LLM Applications using OpenAI, Claude, Gemini, Llama, Mistral
• RAG Systems with Vector Databases
• AI Chatbots with Memory & Context Management
• Voice AI Agents & Real-Time AI Systems
• FastAPI / Flask / Django Backend Development
• Full-Stack Web Applications (React, Next.js)
• AI Automation & Workflow Systems
• Multi-Agent Architectures
• AI Evaluation & Hallucination Detection Systems
• LangChain / LangGraph / CrewAI / AutoGen Workflows
• WhatsApp, Telegram & CRM AI Integrations
• Docker, CI/CD & Cloud Deployment
• PostgreSQL, MongoDB, Redis & Vector DB Integration
• Async Python & High-Performance APIs
• ML Model Deployment & Inference Pipelines
• AI Monitoring, Logging & Observability Systems
• Custom Dashboards & Admin Panels
• Data Processing, Scraping & ETL Pipelines
Why clients work with me
• End-to-end ownership from planning to deployment
• Clean, scalable, production-quality architecture
• Strong communication and realistic project scoping
• Focus on business-ready AI systems
• Fast iteration and structured delivery process
• Ability to handle both simple and highly complex AI projects
AI / ML
Python, OpenAI API, LangChain, LangGraph, CrewAI, AutoGen, HuggingFace, Transformers, PyTorch, Scikit-learn
Backend
FastAPI, Flask, Django, Node.js, Express.js
Frontend
React, Next.js, TypeScript, Tailwind CSS
Databases
PostgreSQL, MongoDB, Redis, Pinecone, ChromaDB, Weaviate, FAISS
DevOps & Deployment
Docker, GitHub Actions, CI/CD, Linux, Nginx, AWS, GCP, Azure
Automation
Zapier, Make com, Webhooks, API integrations, Async workflows
Strong Experience In
• Full-Stack AI SaaS Platforms
• AI Agent Systems
• Enterprise RAG Applications
• AI Workflow Automation
• LLM Evaluation Frameworks
• AI-Powered CRM & Support Systems
• Document Intelligence Systems
• AI Search Engines
• Multi-Modal AI Applications
• AI APIs & Scalable Backend Infrastructure
Steps for completing your project
After purchasing the project, send requirements so Shankar can start the project.
Delivery time starts when Shankar receives requirements from you.
Shankar works on your project following the steps below.
Revisions may occur after the delivery date.
Requirement Analysis & Architecture
Understand use case, data sources, and define RAG architecture, tools, and integration approach.
Data Processing & Vector Indexing
Clean documents, generate embeddings, and store them in a vector database for efficient retrieval.