You will get Custom Web Scraping in Python (Static, Dynamic, Login-Protected Sites)


Project details
Tired of copy-pasting from websites or exporting data manually every day?
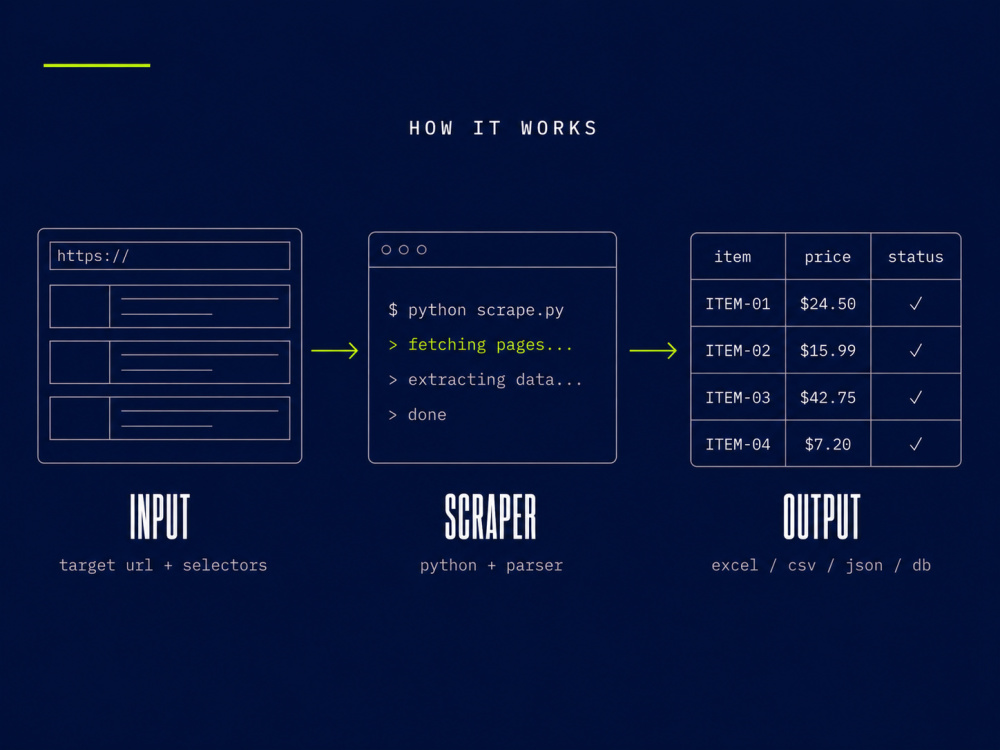
I build custom Python scrapers that turn web pages into structured data — Excel, CSV, JSON, or a database — automatically.
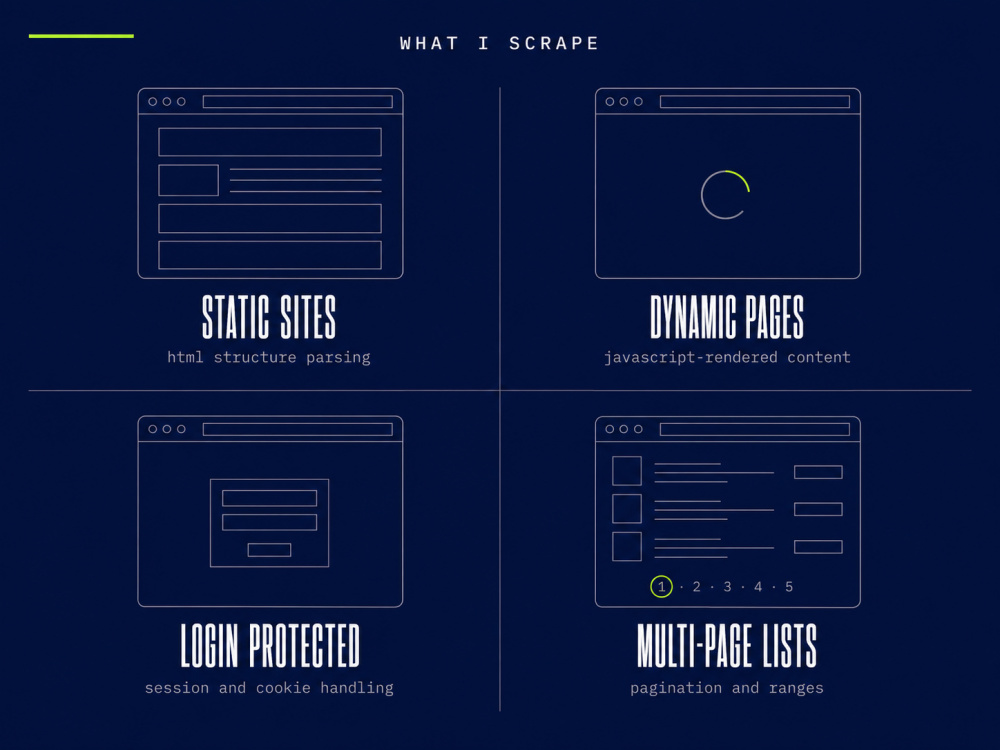
What I scrape:
• Static and JavaScript-rendered websites
• Login-protected and member-only pages
• Multi-page lists with pagination
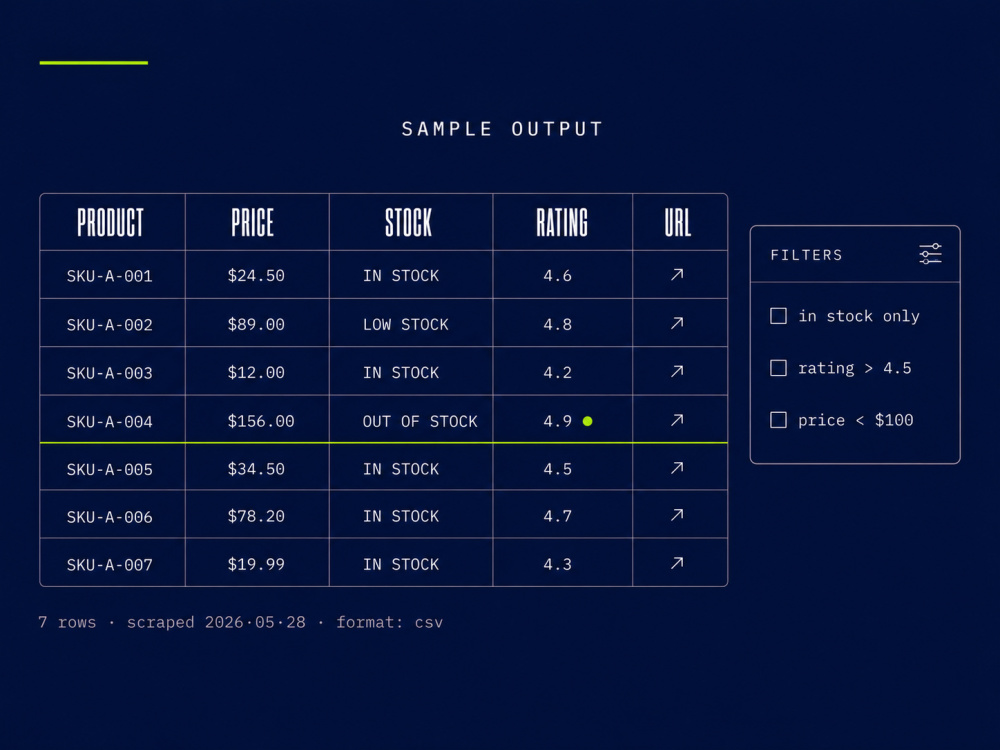
• Tables, images, structured data
Tools: Python, BeautifulSoup, Scrapy, Selenium, Playwright.
How I work:
• Free pre-consultation — I confirm feasibility before you pay
• Source code + setup guide delivered together
• 7 days of free corrections after delivery
• Sample run video for Standard and Advanced tiers
About me:
8+ years full-stack engineering at Lotte Innovate (Korea). Currently running my own production apps, so reliability and edge-case handling come naturally.
Languages: Korean (native), Mandarin Chinese (fluent, 7 years in China), English (conversational). KST timezone — overlaps with APAC mornings and European afternoons.
If the data is publicly viewable in a browser, I can probably scrape it. Send me the URL and I'll tell you what's feasible.
I build custom Python scrapers that turn web pages into structured data — Excel, CSV, JSON, or a database — automatically.
What I scrape:
• Static and JavaScript-rendered websites
• Login-protected and member-only pages
• Multi-page lists with pagination
• Tables, images, structured data
Tools: Python, BeautifulSoup, Scrapy, Selenium, Playwright.
How I work:
• Free pre-consultation — I confirm feasibility before you pay
• Source code + setup guide delivered together
• 7 days of free corrections after delivery
• Sample run video for Standard and Advanced tiers
About me:
8+ years full-stack engineering at Lotte Innovate (Korea). Currently running my own production apps, so reliability and edge-case handling come naturally.
Languages: Korean (native), Mandarin Chinese (fluent, 7 years in China), English (conversational). KST timezone — overlaps with APAC mornings and European afternoons.
If the data is publicly viewable in a browser, I can probably scrape it. Send me the URL and I'll tell you what's feasible.
Data Tool
PythonWhat's included
| Service Tiers |
Starter
$50
|
Standard
$150
|
Advanced
$400
|
|---|---|---|---|
| Delivery Time | 3 days | 5 days | 10 days |
Number of Pages Mined/Scraped | 50 | 200 | 500 |
Number of Sources Mined/Scraped | 1 | 2 | 3 |
Number of Revisions | 1 | 2 | 3 |
Optional add-ons
You can add these on the next page.
Additional Page Mined/Scraped
+$1
Additional Source Mined/Scraped
(+ 1 Day)
+$50
Additional Revision
+$25Frequently asked questions
About JunChang
Full-Stack Developer (KR/CN/EN) | Web Scraping & Automation | 8 Years
Seoul, South Korea - 7:45 am local time
I spent 8 years at Lotte Innovate (Korea), working on:
- Web scraping & browser automation pipelines
- Backend APIs and partner integrations (Java, Spring Boot, Node.js)
- React/Next.js front-end and Flutter mobile apps
- AWS infrastructure + Datadog observability
Now independent under RIN Lab.
Problems I've solved:
- Migrating millions of user records across systems with zero downtime
- Cutting batch processing time by 4× via parallel scheduling
- Bypassing anti-bot detection on Korean e-commerce sites
- Shipping a Flutter mobile app to international users (still in production)
What I do for clients:
- Web scraping (Python, Playwright, BeautifulSoup) including anti-bot strategies
- Data cleaning, schema mapping, bulk Excel/CSV processing
- REST API design, integration, and bulk uploads
- Full-stack web apps (Next.js + Spring Boot / Node.js)
Working style:
- Fixed-price preferred for clear-scope projects
- Daily progress updates
- KST (UTC+9) — overlaps with Asia Pacific business hours and European afternoons
Open to small test projects to start. Comfortable working with messy data and figuring things out logically.
Steps for completing your project
After purchasing the project, send requirements so JunChang can start the project.
Delivery time starts when JunChang receives requirements from you.
JunChang works on your project following the steps below.
Revisions may occur after the delivery date.
Kickoff & Feasibility Check
I review the target URL(s), confirm data fields, and check feasibility. Any blockers (anti-bot, access issues) are flagged upfront before development starts.
Development & Sample Run
I build the Python scraper based on agreed scope, run it end-to-end, and send a sample output for your review. Standard and Advanced tiers include a short demo video.