You will get customer churn prediction model using machine learning

Project details
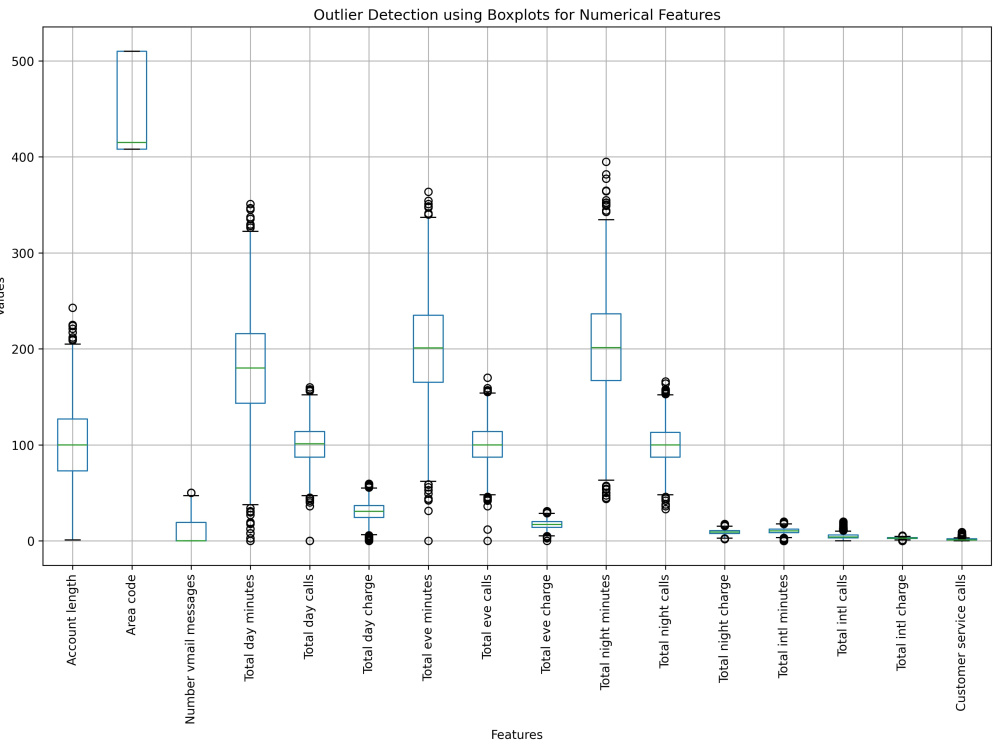
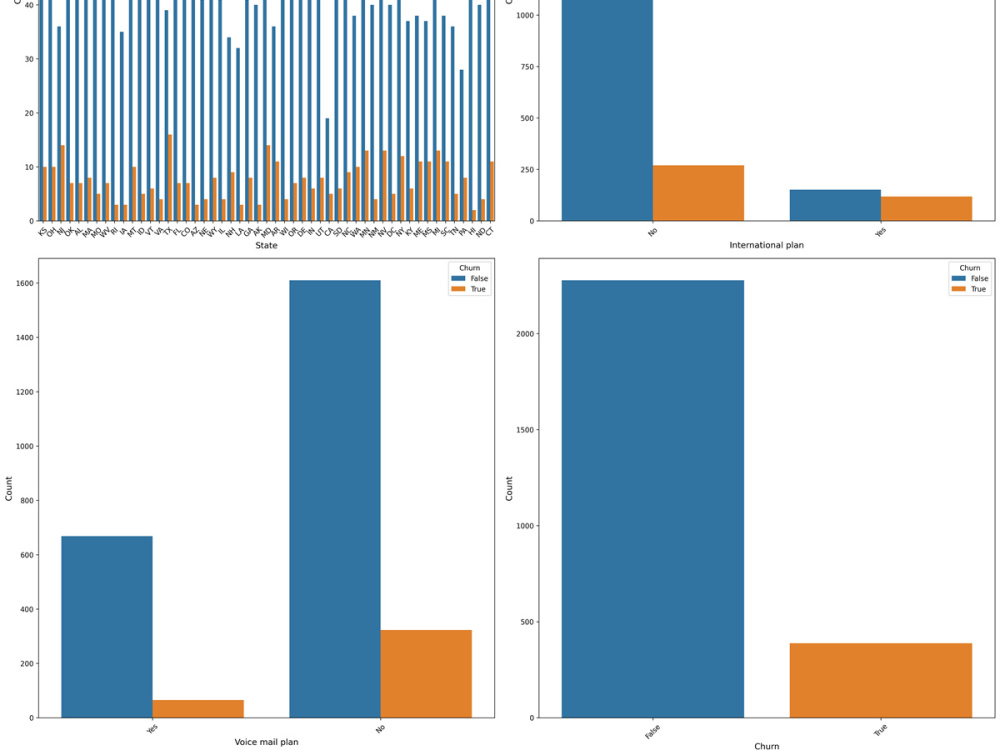
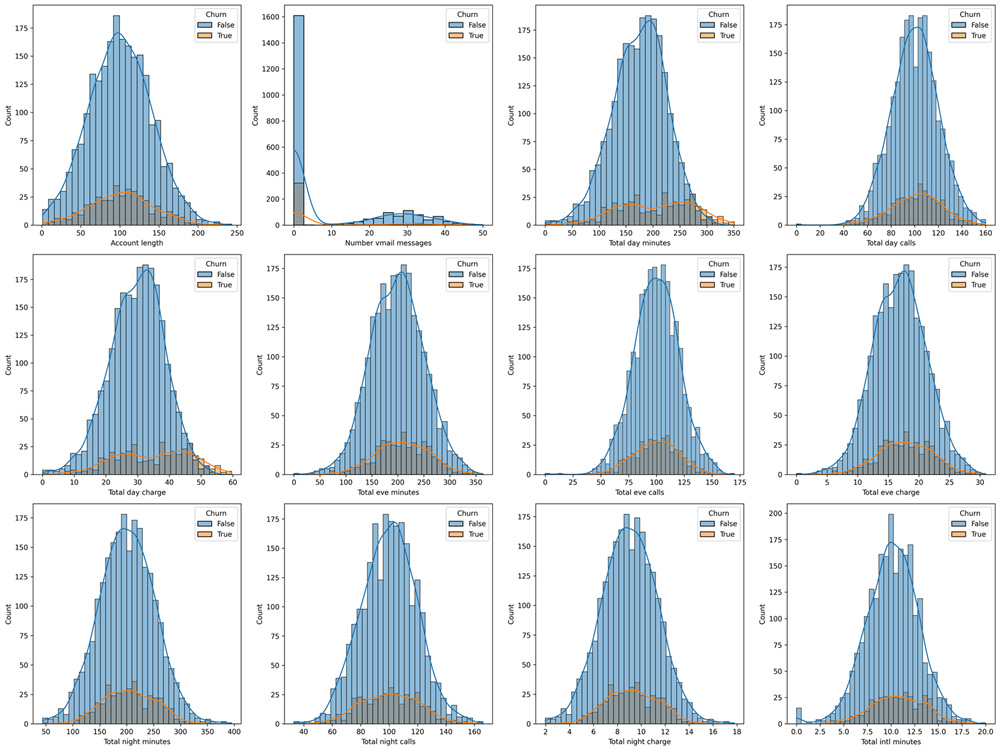
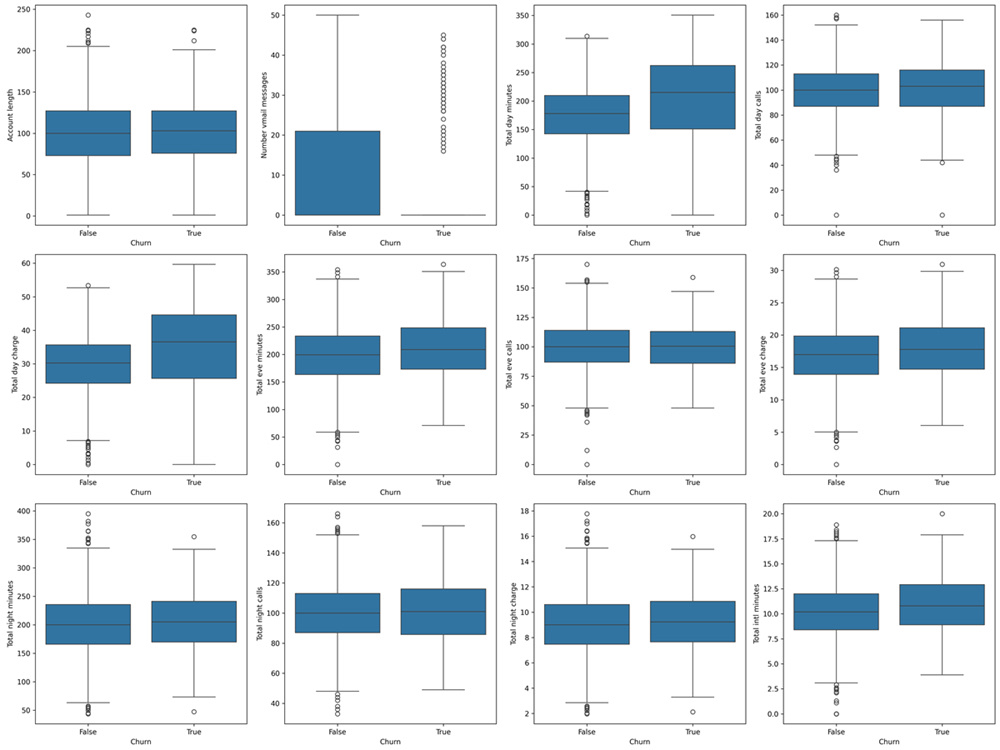
I will develop a machine learning-based Customer Churn Prediction solution to help you identify customers who are likely to leave your business. This project includes data cleaning, exploratory data analysis (EDA), feature engineering, and building predictive models such as Logistic Regression, Decision Tree, or Random Forest.
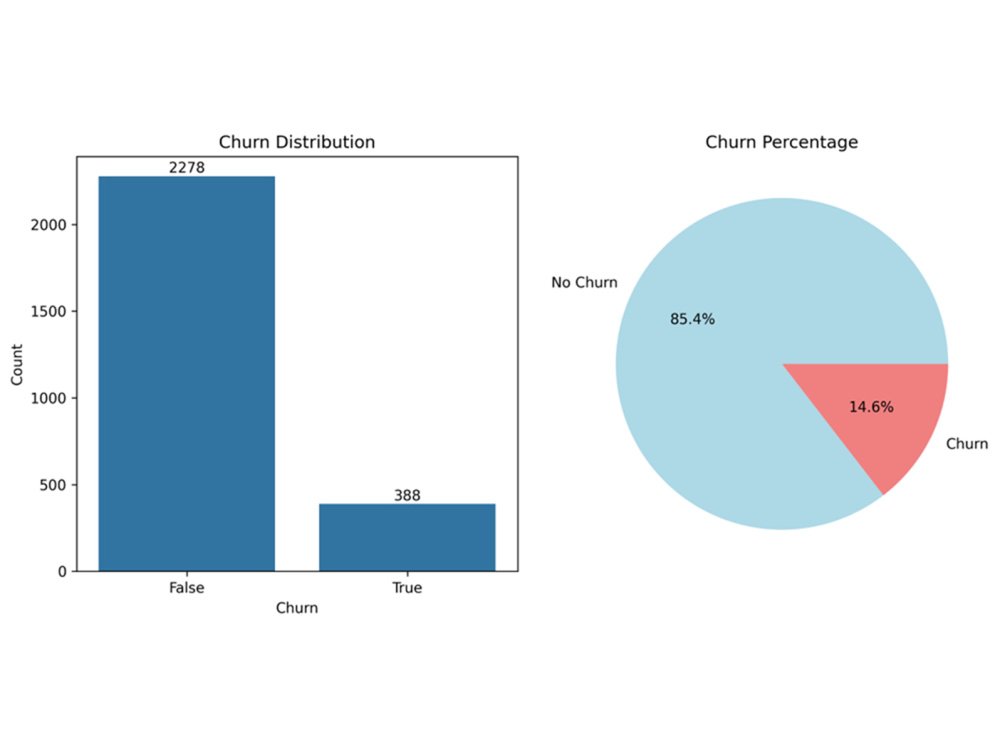
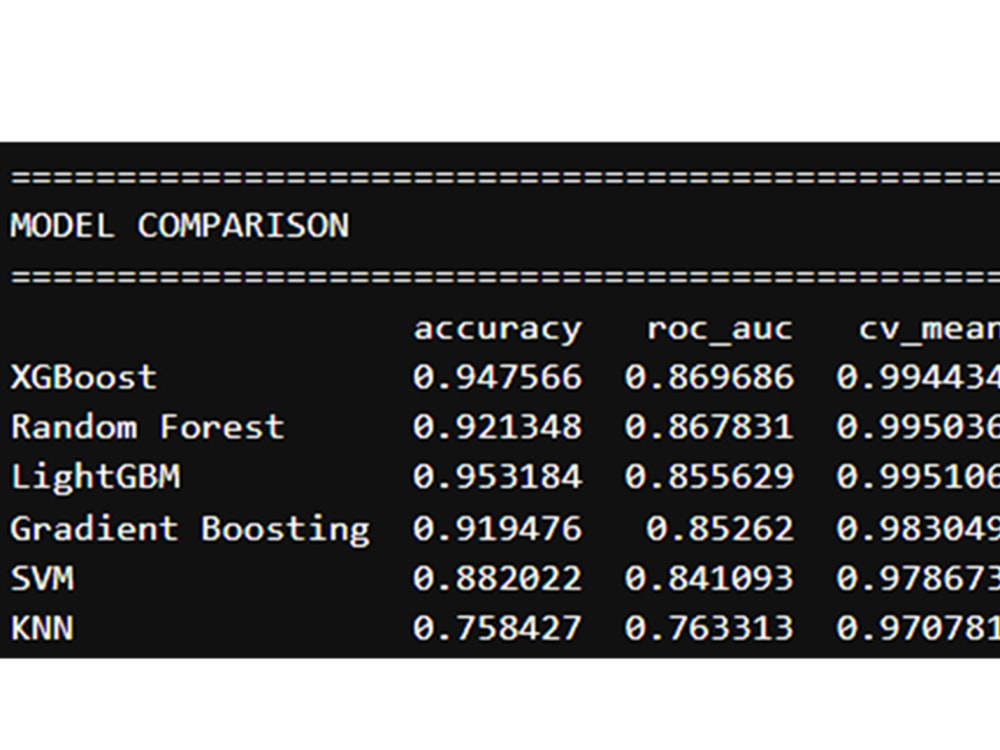
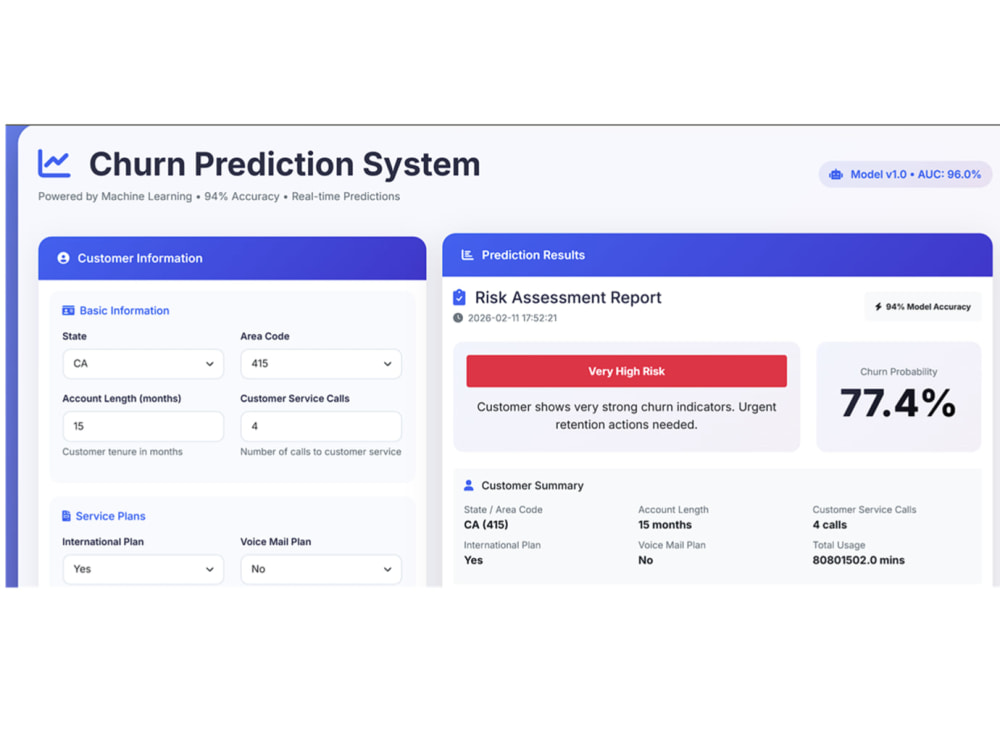
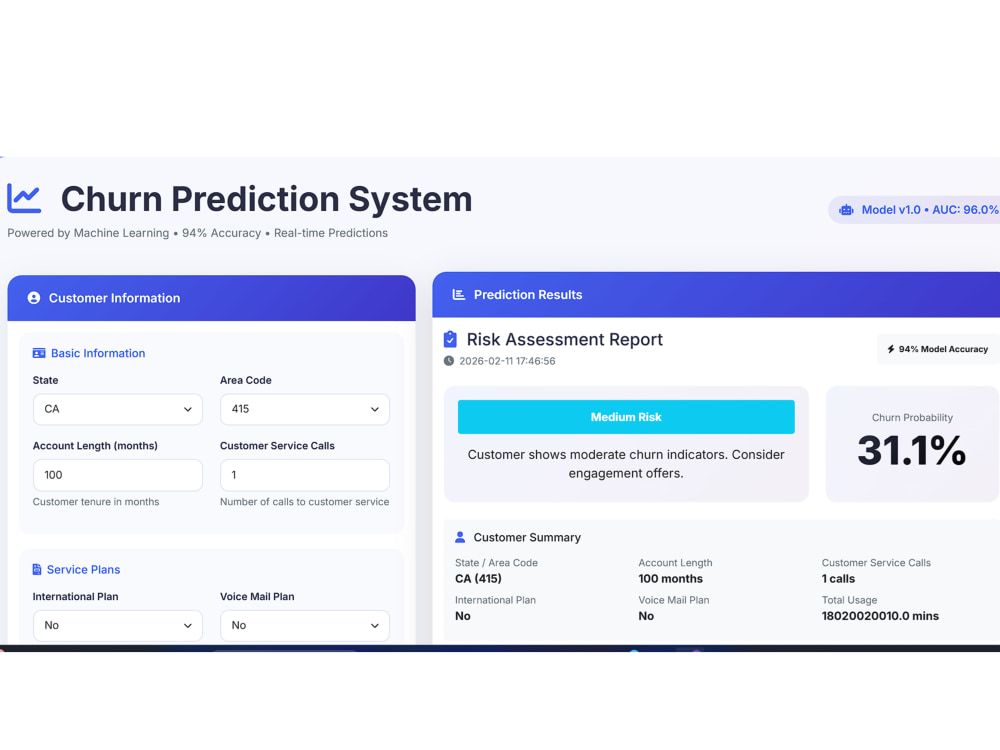
You will receive churn probability predictions, model performance metrics (Accuracy, Precision, Recall, ROC-AUC), and visual insights to understand the key factors influencing customer churn. I also provide a clear report with actionable recommendations to improve customer retention and reduce revenue loss.
The final deliverables can include a Jupyter Notebook, trained model, prediction results, and visual dashboards (Excel or Power BI) based on your requirements.
This solution is ideal for telecom, banking, SaaS, e-commerce, and subscription-based businesses looking to make data-driven retention decisions.
You will receive churn probability predictions, model performance metrics (Accuracy, Precision, Recall, ROC-AUC), and visual insights to understand the key factors influencing customer churn. I also provide a clear report with actionable recommendations to improve customer retention and reduce revenue loss.
The final deliverables can include a Jupyter Notebook, trained model, prediction results, and visual dashboards (Excel or Power BI) based on your requirements.
This solution is ideal for telecom, banking, SaaS, e-commerce, and subscription-based businesses looking to make data-driven retention decisions.
Machine Learning Tools
Google Sheets, Keras, Microsoft Excel, Microsoft Power BI, NumPy, OpenCV, pandas, Python, R, scikit-learn, SciPy, SQL, Tableau, TensorFlow, Tesseract OCR, XGBoostWhat's included
| Service Tiers |
Starter
$22
|
Standard
$45
|
Advanced
$80
|
|---|---|---|---|
| Delivery Time | 3 days | 4 days | 7 days |
Number of Revisions | 1 | 2 | 3 |
Number of Model Variations | 1 | 2 | 3 |
Number of Scenarios | 1 | 2 | 2 |
Number of Graphs/Charts | 3 | 6 | 10 |
Model Validation/Testing | - | - | |
Model Documentation | - | - | |
Data Source Connectivity | - | ||
Source Code |
Optional add-ons
You can add these on the next page.
Additional Revision
+$5
Model Validation/Testing
(+ 2 Days)
+$10
Model Documentation
(+ 2 Days)
+$10
Data Source Connectivity
(+ 1 Day)
+$5Frequently asked questions
About Harshitha
Data Scientist | AI & ML | Cloud Computing & Data Analytics
Bengaluru, India - 10:56 am local time
I specialize in classification, regression, clustering, and forecasting tasks, and I can design machine learning pipelines that include hyperparameter tuning, cross-validation, performance benchmarking, and result visualization. For advanced use cases, I also support model deployment through cloud environments and REST API integration. I follow clean, well-structured, and documented coding practices to ensure reproducibility and clarity.
I am comfortable working with structured and semi-structured data and can assist with academic, commercial, or prototype-oriented projects involving analytics, machine learning, and cloud-based solutions. I enjoy collaborating with clients, gathering requirements clearly, and delivering measurable outputs aligned with expectations. I am open to internship, freelance, and research-based opportunities in data science, machine learning, data analytics, and cloud engineering domains.
Technical Skills:
Python (NumPy, Pandas, Scikit-learn, Matplotlib, Seaborn), SQL, Excel, Machine Learning, Feature Engineering, Data Cleaning, EDA, Business Analytics, Data Visualization (Power BI/Tableau), Cloud Computing (AWS/Azure/GCP).
Steps for completing your project
After purchasing the project, send requirements so Harshitha can start the project.
Delivery time starts when Harshitha receives requirements from you.
Harshitha works on your project following the steps below.
Revisions may occur after the delivery date.
Data Understanding, Data Preparation, Model Building, Insights & Delivery
Analyze dataset structure and business requirements. Perform data cleaning, feature engineering, and EDA. Train machine learning models and evaluate performance. Provide predictions, performance metrics, and business insights.