You will get Data Cleaning and ETL Pipelines
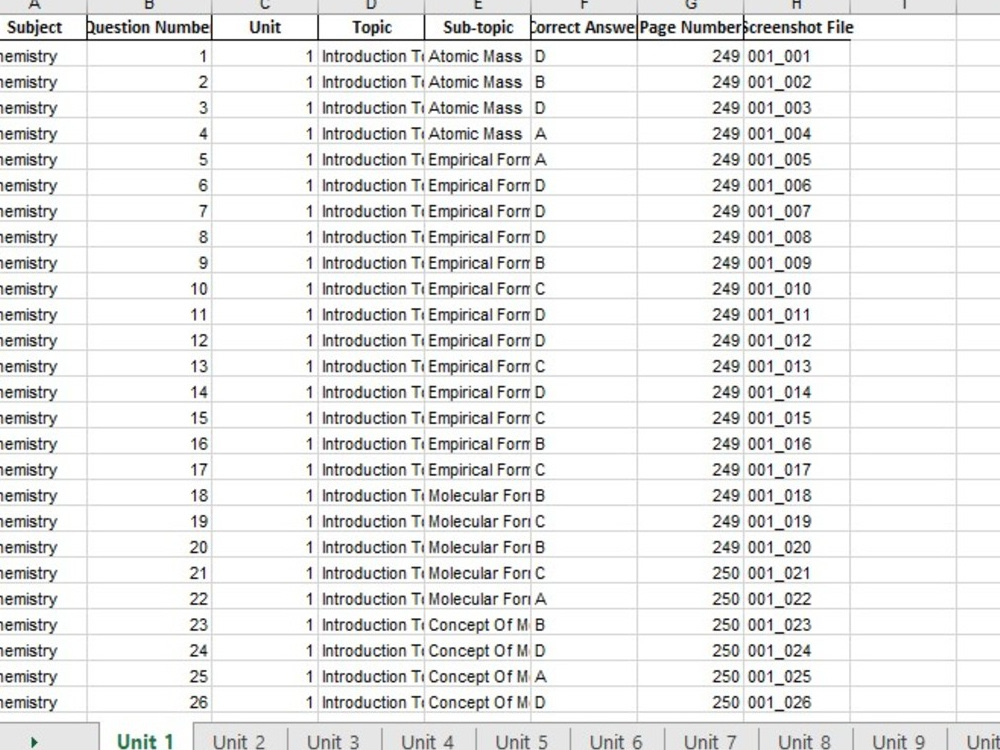
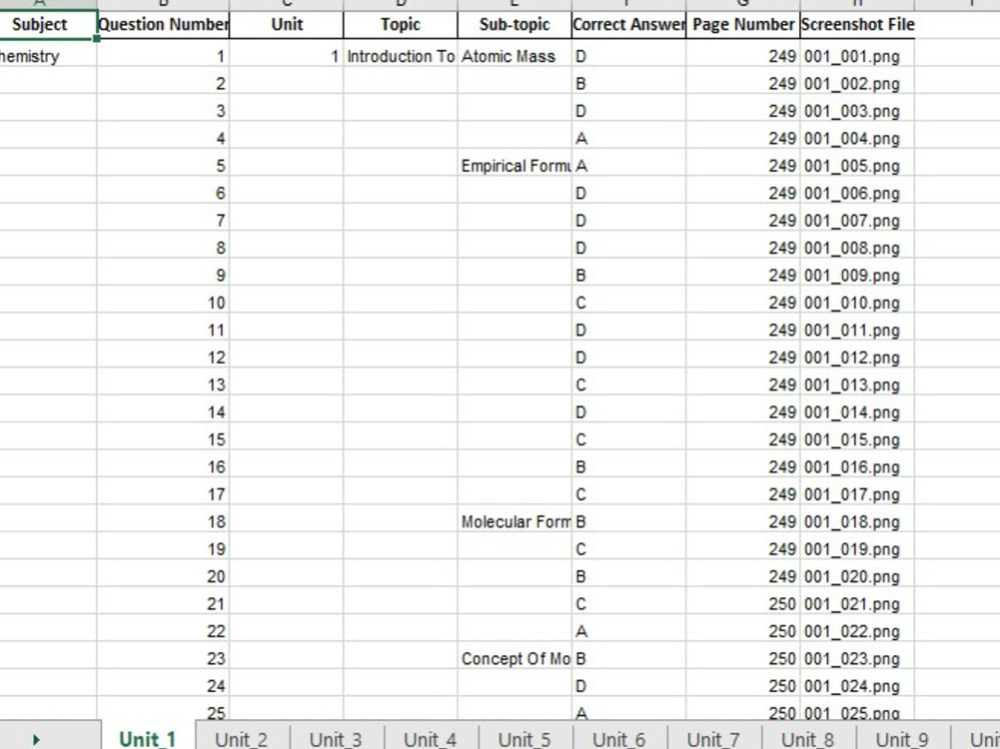
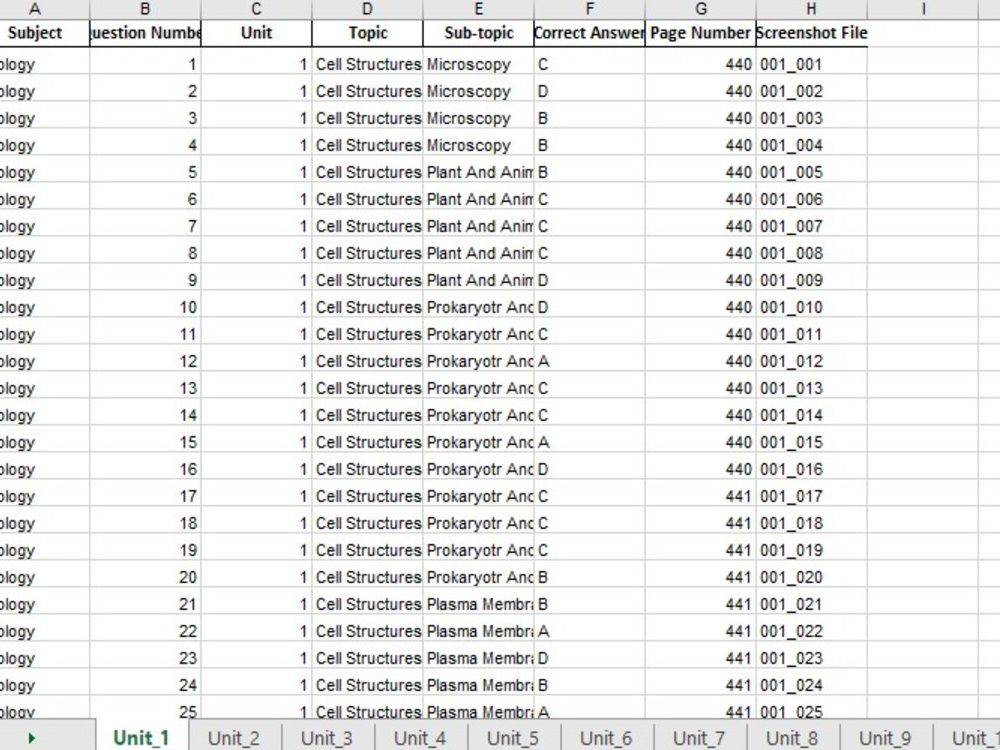
Project details
information assets. I focus on building intelligent data cleaning and ETL workflows that go beyond basic preprocessing by ensuring data consistency, structural integrity, and automation.
What makes this project unique is the combination of practical data engineering practices with reliable quality checks at each stage of the pipeline. From handling missing or noisy data to standardizing formats, detecting anomalies, and optimizing data movement across systems, the solution is built to support real-world production use.
The goal is not just to clean data, but to create sustainable pipelines that reduce manual effort, improve accuracy, and allow businesses to confidently use their data for analysis and decision-making.
What makes this project unique is the combination of practical data engineering practices with reliable quality checks at each stage of the pipeline. From handling missing or noisy data to standardizing formats, detecting anomalies, and optimizing data movement across systems, the solution is built to support real-world production use.
The goal is not just to clean data, but to create sustainable pipelines that reduce manual effort, improve accuracy, and allow businesses to confidently use their data for analysis and decision-making.
Data Tool
PythonWhat's included
| Service Tiers |
Starter
$25
|
Standard
$75
|
Advanced
$150
|
|---|---|---|---|
| Delivery Time | 2 days | 4 days | 6 days |
Number of Revisions | 1 | 2 | 3 |
Number of Pages Mined/Scraped | 0 | 0 | 0 |
Number of Sources Mined/Scraped | 0 | 0 | 0 |
About Eisha
AI & Backend Engineer | FastAPI | Python | LLM | GCP
Faisalabad, Pakistan - 11:40 pm local time
In my current role, I architect and maintain Python/FastAPI backends for multiple production platforms, integrating AI-powered features including automated evaluation, feedback generation, and voice-based interaction, alongside AI automation pipelines for data processing, classification, and content workflows. I manage end-to-end data pipelines processing 10,000+ documents monthly, from raw ingestion through LLM-assisted labeling, OCR extraction, and structured output to live app integration.
My AI toolkit includes RAG systems (FAISS, SentenceTransformers), LangGraph-based agent workflows, fine-tuning with LoRA (Qwen-1.5-4B), and daily integration of Gemini and OpenAI APIs. I deploy on GCP Cloud Run with Docker and Kubernetes, and have built event-driven pipelines using GCP Pub/Sub.
Available for LLM integration, API integration, AI feature development, backend architecture, and data engineering work.
Steps for completing your project
After purchasing the project, send requirements so Eisha can start the project.
Delivery time starts when Eisha receives requirements from you.
Eisha works on your project following the steps below.
Revisions may occur after the delivery date.
Requirements Review
Analyze dataset, understand cleaning rules & output expectations.
Data Inspection & Profiling
Identify missing values, duplicates, format issues, and anomalies.