You will get Data Cleaning & EDA Reports + ML Readiness Assessment
Rising Talent
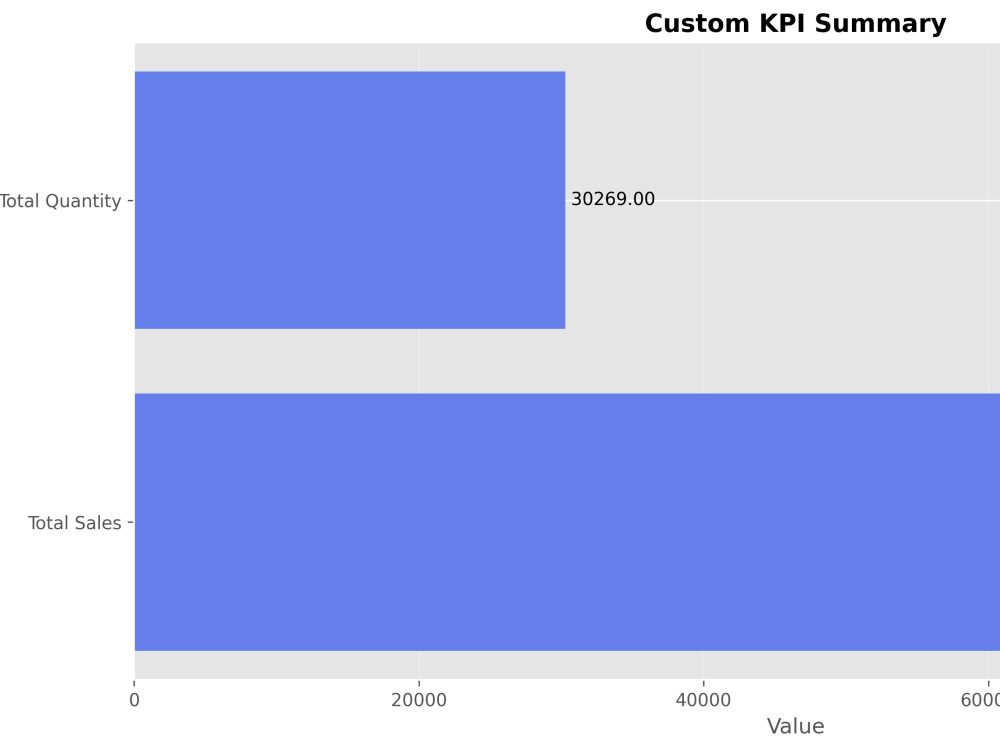
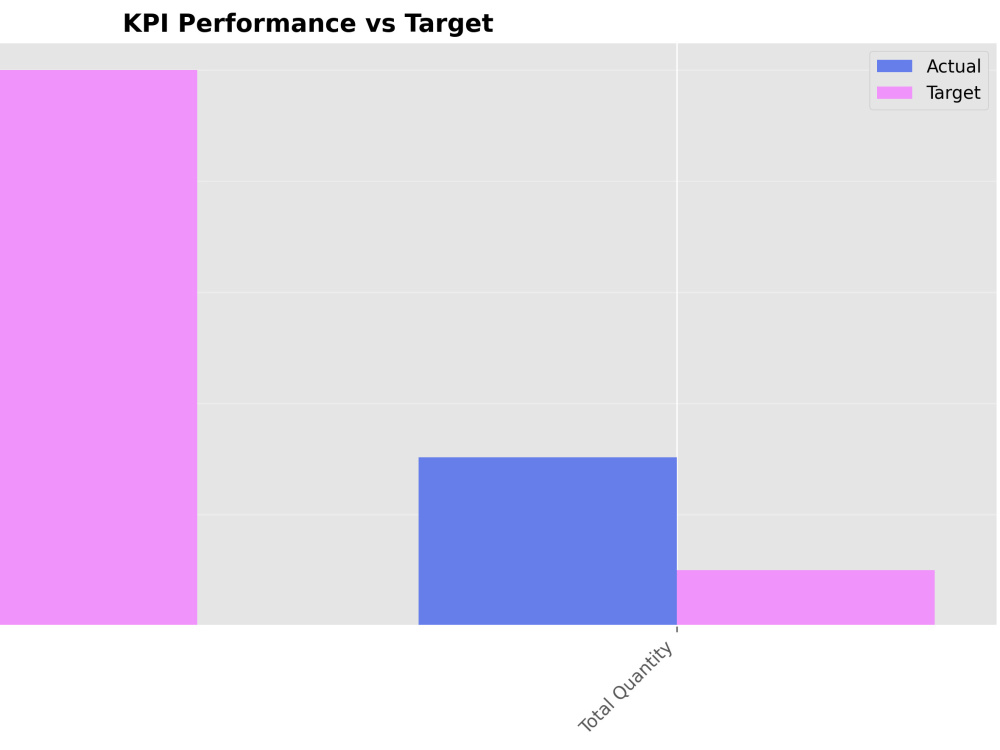
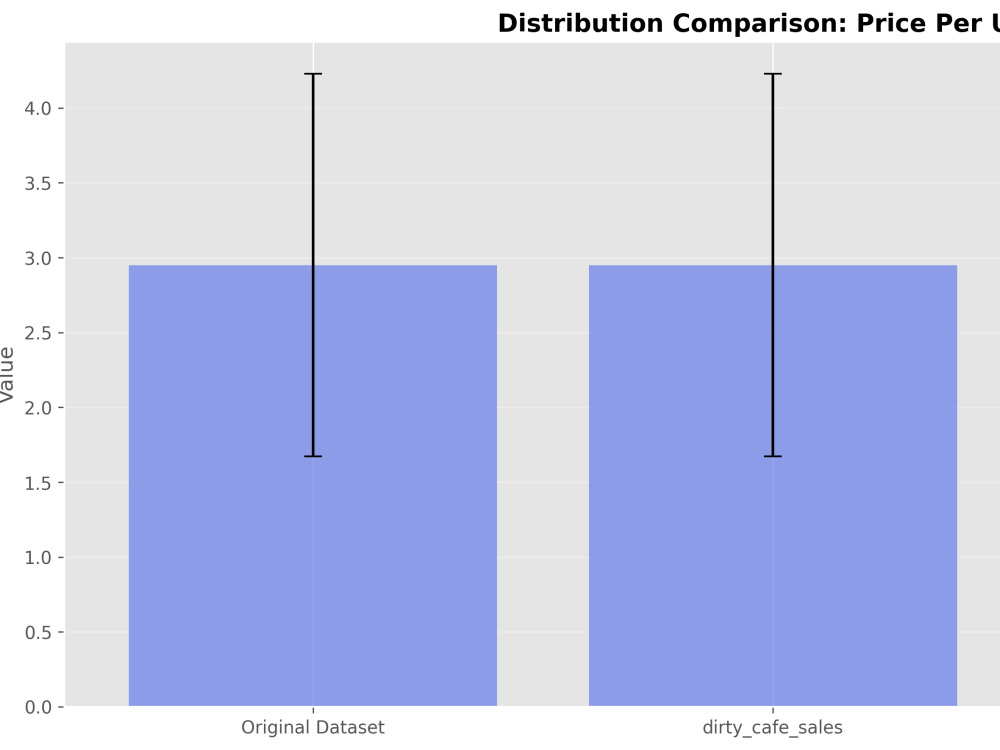
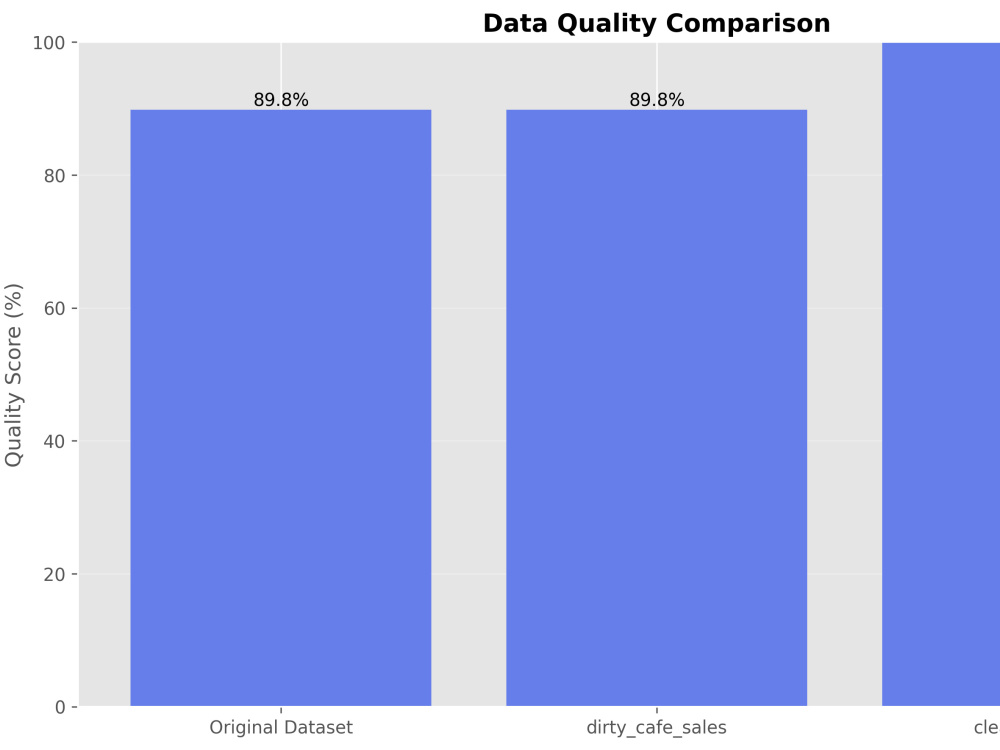
Project details
Production-grade, statistically robust data cleaning and exploratory analysis — delivered through a Python-pipeline-driven workflow.
This service is designed for clients who need reliable, decision-ready insights, not manual spreadsheet work.
What you get (Starter tier):
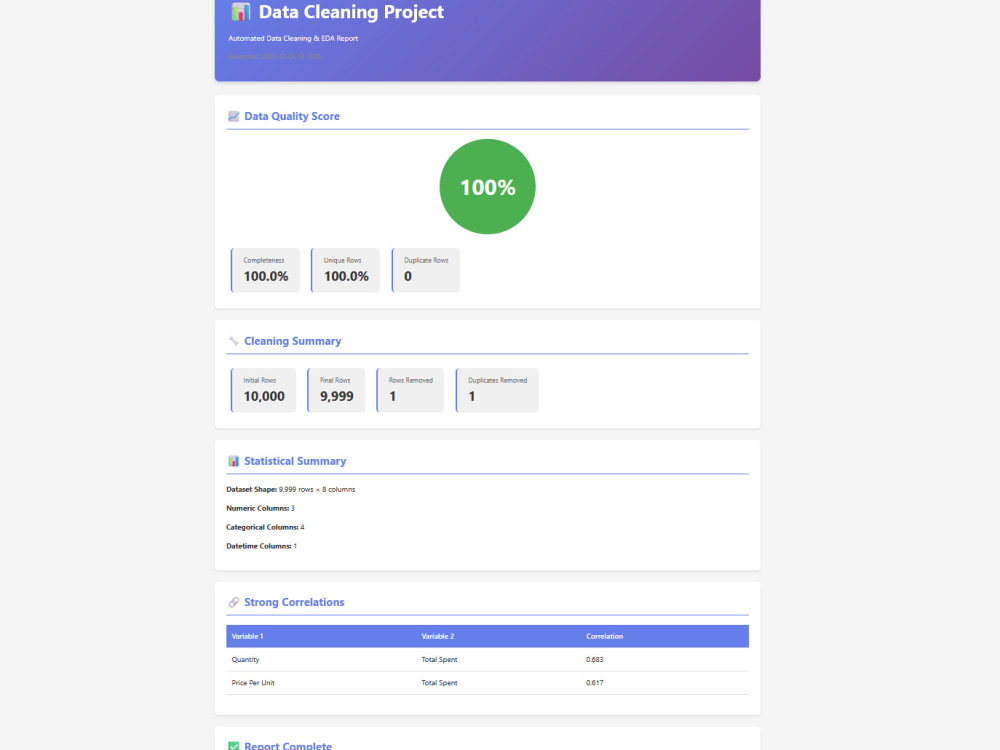
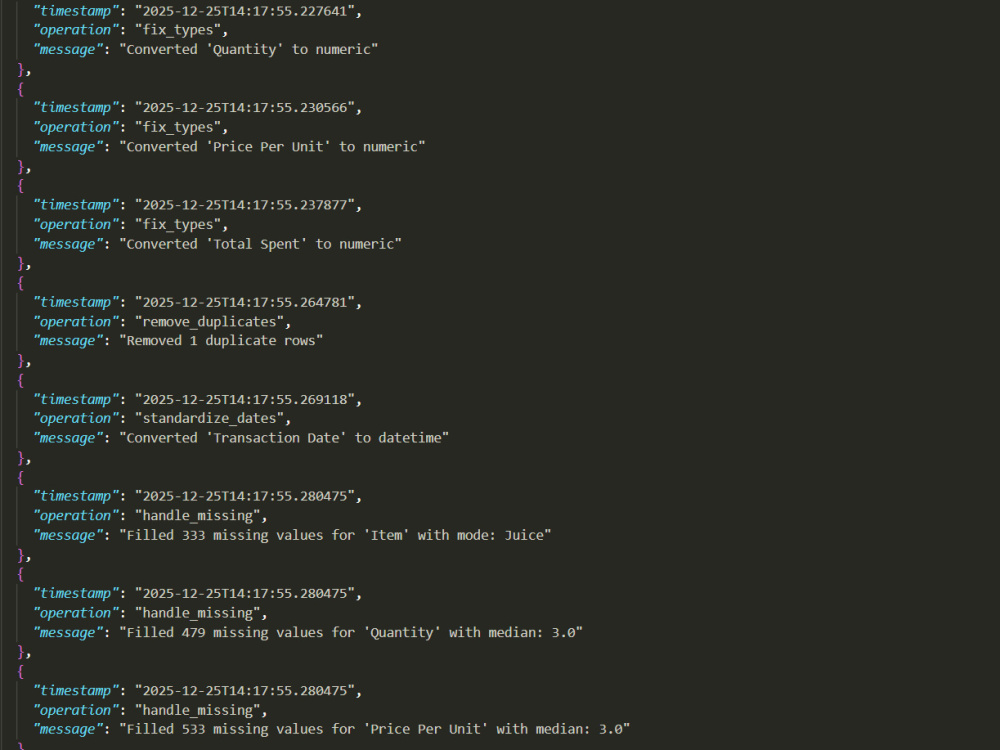
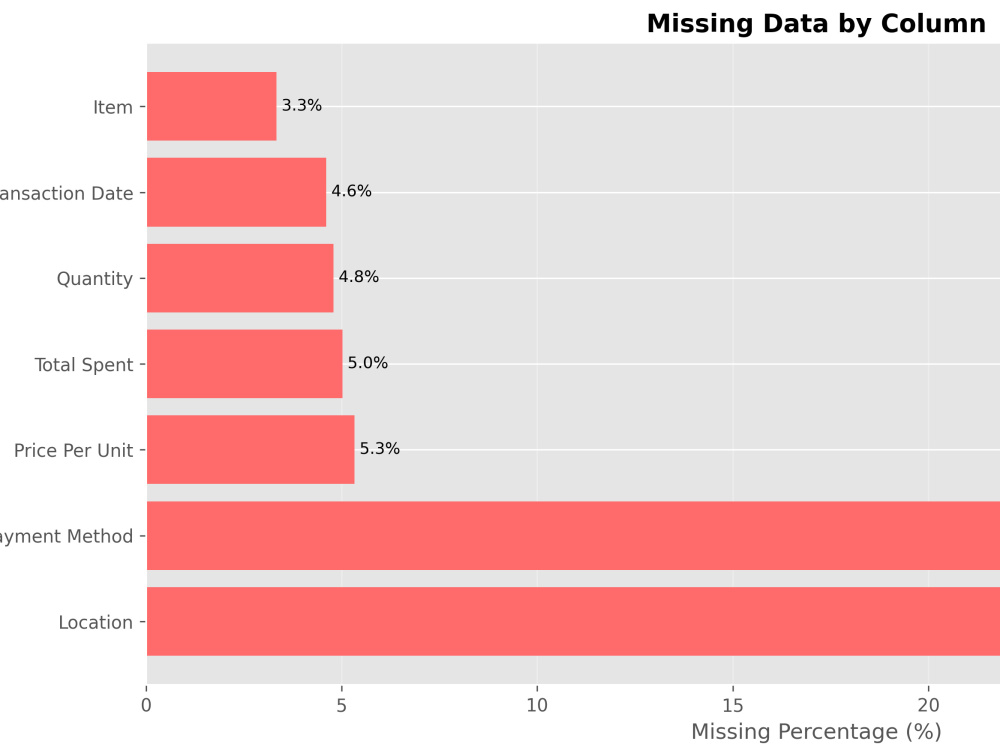
Full data cleaning (missing values, duplicates, data types, date standardization)
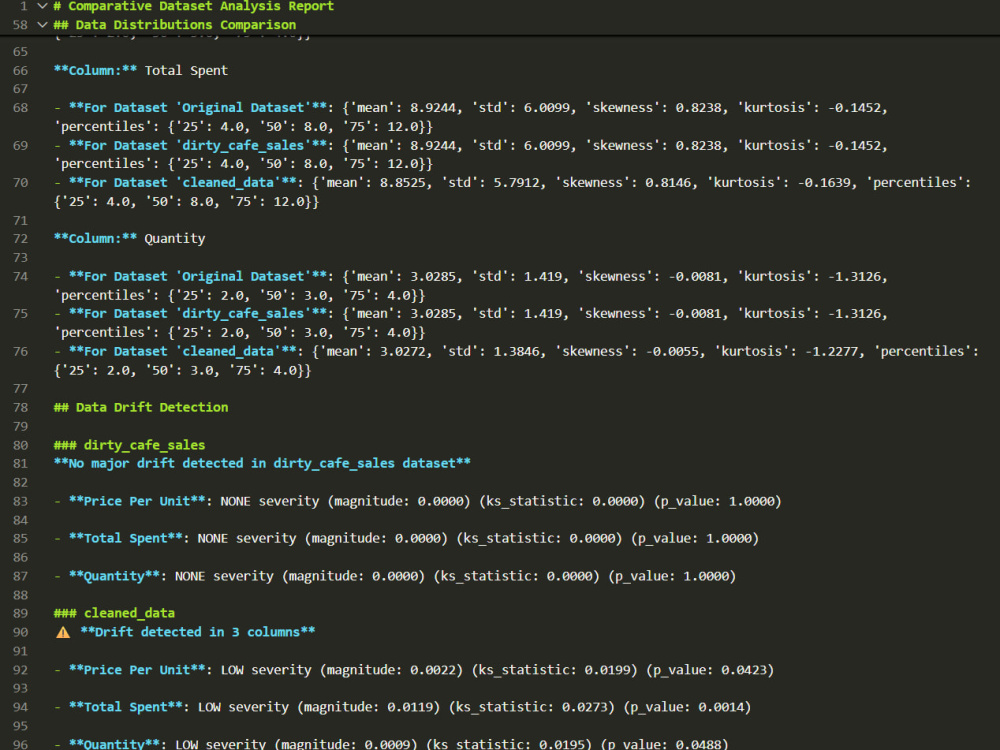
Exploratory Data Analysis (EDA) on cleaned data
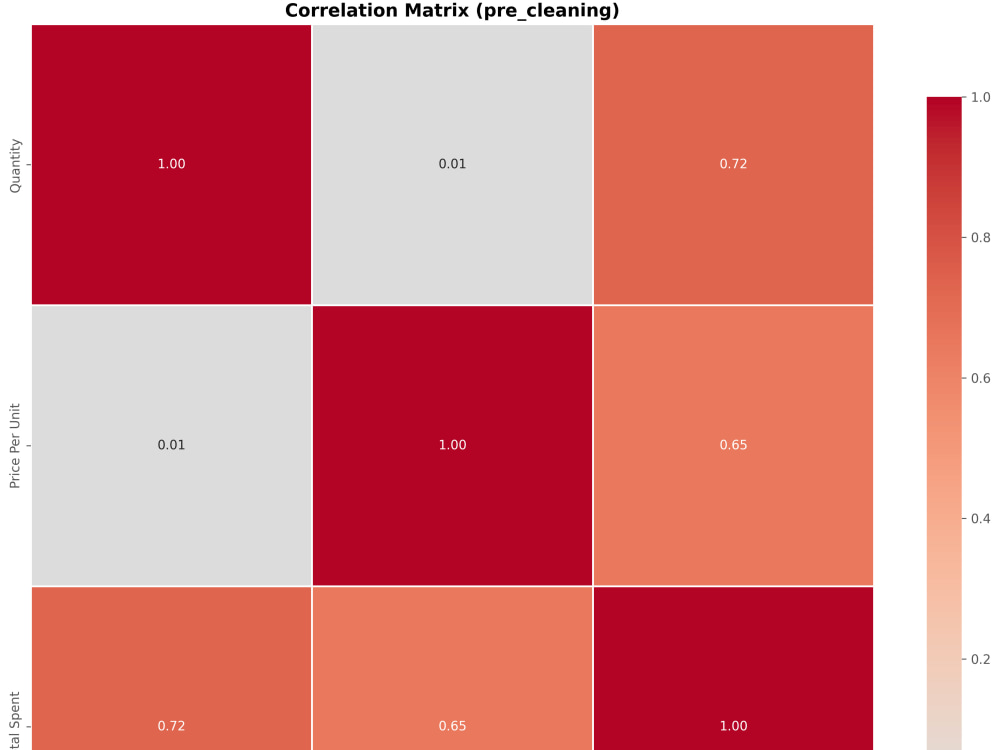
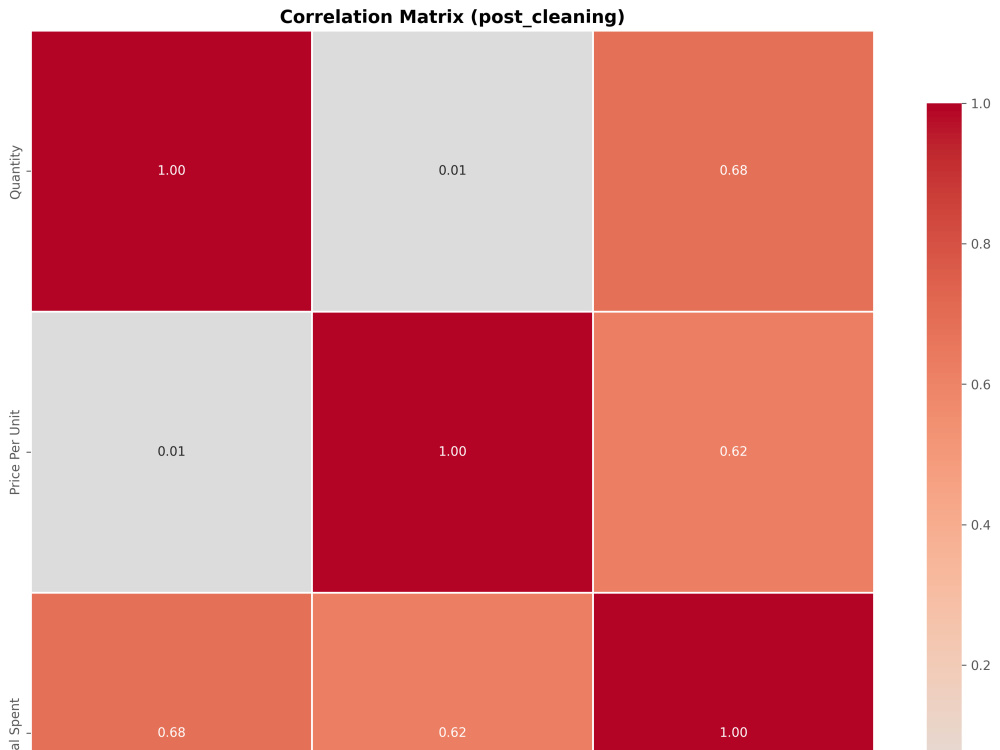
Statistical summaries and professional visualizations
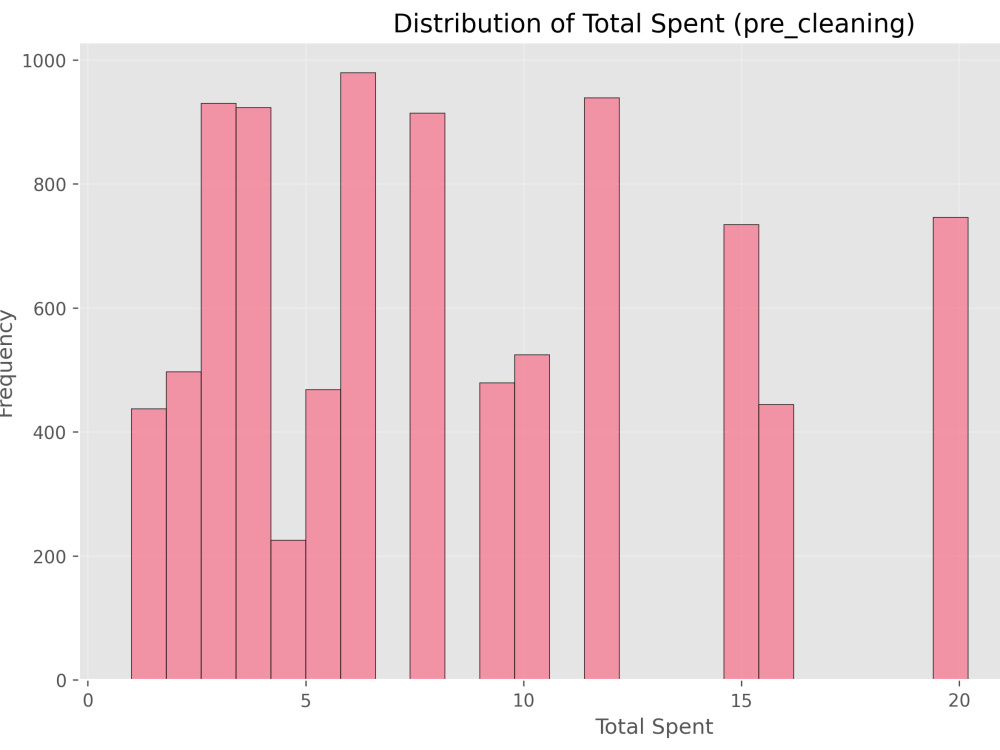
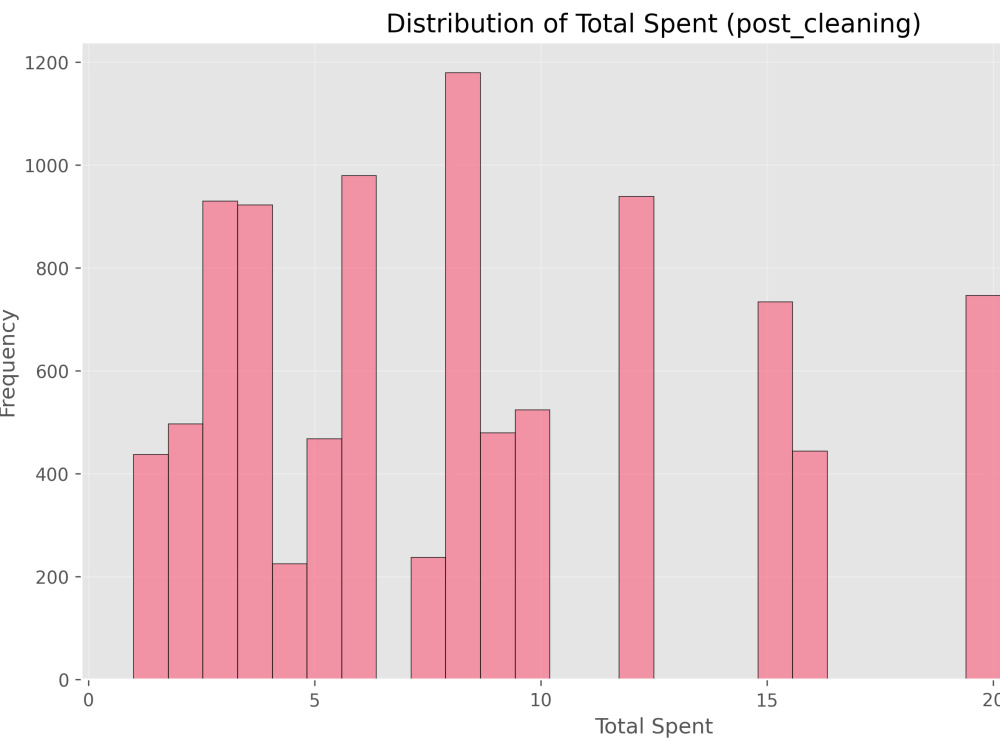
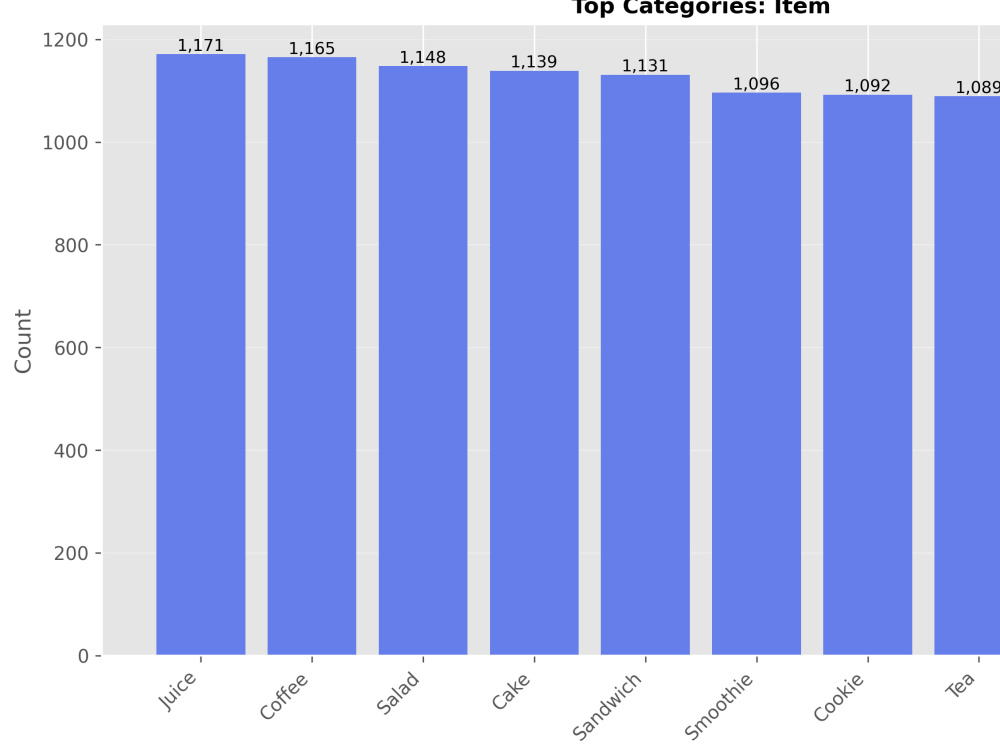
(distributions, correlations, scatter plots, box plots, categorical charts)
Higher tiers:
Pre-cleaning EDA as well
Outlier handling (IQR method)
Time-based statistical analysis for a target feature (trend & lag behavior)
Data drift detection to compare datasets (up to 3 max: 1 main dataset for cleaning, then 2 more only for comparisons)
Clear analytical reports explaining findings, stats, and implications
Important notes:
No manual data entry — this is a Python-based service
Input formats: CSV / Excel
Outputs: CSV, MD, JSON, PNG
If you need clean data and rapid analytical insights, then this is the service for you.
Please message me if you’re unsure which tier fits your dataset or if you need any more info about this service.
This service is designed for clients who need reliable, decision-ready insights, not manual spreadsheet work.
What you get (Starter tier):
Full data cleaning (missing values, duplicates, data types, date standardization)
Exploratory Data Analysis (EDA) on cleaned data
Statistical summaries and professional visualizations
(distributions, correlations, scatter plots, box plots, categorical charts)
Higher tiers:
Pre-cleaning EDA as well
Outlier handling (IQR method)
Time-based statistical analysis for a target feature (trend & lag behavior)
Data drift detection to compare datasets (up to 3 max: 1 main dataset for cleaning, then 2 more only for comparisons)
Clear analytical reports explaining findings, stats, and implications
Important notes:
No manual data entry — this is a Python-based service
Input formats: CSV / Excel
Outputs: CSV, MD, JSON, PNG
If you need clean data and rapid analytical insights, then this is the service for you.
Please message me if you’re unsure which tier fits your dataset or if you need any more info about this service.
Data Tool
PythonWhat's included
| Service Tiers |
Starter
$40
|
Standard
$80
|
Advanced
$150
|
|---|---|---|---|
| Delivery Time | 2 days | 3 days | 4 days |
Number of Revisions | 1 | 2 | 3 |
Number of Pages Mined/Scraped | 0 | 0 | 0 |
Number of Sources Mined/Scraped | 0 | 0 | 0 |
Optional add-ons
You can add these on the next page.
Fast Delivery
+$10 - $50
Additional Revision
+$50Frequently asked questions
About Hammad
Data Scientist | Machine Learning & Data Services
Rawalpindi, Pakistan - 6:29 am local time
• Data Cleaning services such as De-duplication, Missing value handling (Interpolation, forward-fill, back-fill, KNN & other Impute methods), Outlier handling (Z-Score Winsorized, IQR method).
• Exploratory Data Analysis including Correlation heat-maps, data distribution charts (hist, scatter, bar), Missing data & Box plots and summary of findings.
• Time-Series Analysis including Autocorrelation test plots (ACF, PACF), Stationarity tests (ADF, KPSS) and Trend Decomposition.
• Data Drift detection via KS_Statistic and p_values.
• Feature Engineering and Data Pre-Processing in preparation for Machine Learning. Creation of new features from existing numerical, categorical, and datetime features. Scaling and Encoding of numerical and categorical data. Class Balancing etc.
• Feature Selection via Mutual Info method, variance of feature with target, filtering for minimal covariance with other features and multi-collinearity etc. Stratified splitting and producing the final set of datasets in the form of Training-Validation-Testing splits.
• Building of Machine Learning models using the cleaned and processed data from above steps. Training multiple models using different algorithms and comparing the results. Algorithms used depend on whether the task is Regression (Linear Regression, Ridge, Lasso, Elastic Net, AutoGluon models etc) or Classification (Decision Trees, Random Forests, XGBoost, FLAML etc).
• Hyper-parameter Tuning via Random Search or Optuna Bayesian etc.
• Post modelling validation and testing using split data from previous steps. Comparisons of metrics scores between splits and algorithms.
• Post-Modelling Visualizations such as Feature Importances plots, Metrics Tables, Predicted VS Actuals plots, Residuals Analysis, Classification Reports, Precision Recall Curves, SHAPley plots etc.
And much more.
I've worked as a data scientist at multinational corporations such as AkzoNobel and British American Tobacco. I worked in a data analysis capacity in both of these roles, as well as building machine learning models using Python for various predictive tasks.
Specific examples of these tasks:
Using Neural Networks to build a model that predicts the quality of a type of paint based on the chemical composition. Then building a Genetic Algorithm based system that uses said neural network model to generate new paints as chemical compositions, that are predicted to be high quality.
Improving a machine learning model used to predict price elasticities for cigarette products, iterating upon original Linear Regression version by instead using XGB Regressor, Random Forests, ARIMA & SARIMAX etc. Then using the models to build a price scenario tool in Excel to make sales forecasts and predict revenue based on different price scenarios.
If you feel you might be in need of any of my services, please feel free to drop me a message so we can discuss. I've also uploaded services that I offer here on Upwork in my Project Catalog, each of which has a relevant item in my portfolio. Please check these out for an idea of what exactly I offer as final deliverables for each service.
Thanks for reading this, and I hope you'll reach out. Have a nice day!
Steps for completing your project
After purchasing the project, send requirements so Hammad can start the project.
Delivery time starts when Hammad receives requirements from you.
Hammad works on your project following the steps below.
Revisions may occur after the delivery date.
Input collection
I need to collect input files and requirements from the client. These will be used to configure my pipelines to perform exactly what the client needs from my offered services.
Execution and Review
I will run my pipelines with the settings & files collected, and review the outputs for any issues, and repeat as necessary until satisfactory results are achieved.