You will get Data engineer | ETL | Data integration | Database Architecture and design
Project details
Need a production-ready ETL pipeline, data integration system or database architecture built from scratch? You've found the right Data Engineer. As an experienced Data Engineer and ETL pipeline consultant with 11 years of experience, I design and deliver scalable data integration solutions, high-performance database architectures, and automated ETL/ELT pipelines that power enterprise-grade analytics including projects for global organizations like GSK.
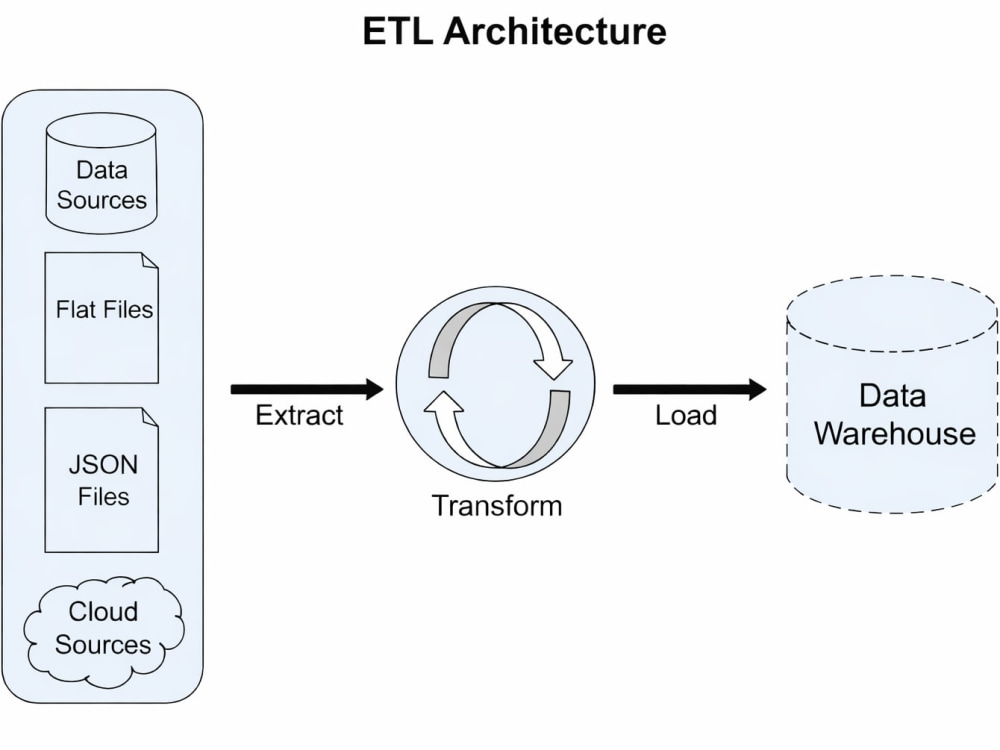
ETL/ELT Pipeline Development: Scalable batch and streaming pipelines using Apache Kafka, Apache Airflow, Apache Spark and Python
Data Integration: REST APIs, SaaS platforms and internal systems into one reliable data pipeline
Database Architecture & Design: High-performance data modeling using Star Schema and Snowflake Schema across Redshift, Snowflake, PostgreSQL, MySQL and BigQuery
Cloud Data Warehouse: Production-ready Snowflake, AWS Redshift, Google BigQuery and Azure warehouse solutions
Data Lakehouse Architecture: Build scalable Delta Lake and Databricks solutions for real-time analytics
DataOps & Monitoring: End-to-end data validation, lineage tracking, logging and CI/CD automation using Docker, Kubernetes and GitHub Actions
ETL/ELT Pipeline Development: Scalable batch and streaming pipelines using Apache Kafka, Apache Airflow, Apache Spark and Python
Data Integration: REST APIs, SaaS platforms and internal systems into one reliable data pipeline
Database Architecture & Design: High-performance data modeling using Star Schema and Snowflake Schema across Redshift, Snowflake, PostgreSQL, MySQL and BigQuery
Cloud Data Warehouse: Production-ready Snowflake, AWS Redshift, Google BigQuery and Azure warehouse solutions
Data Lakehouse Architecture: Build scalable Delta Lake and Databricks solutions for real-time analytics
DataOps & Monitoring: End-to-end data validation, lineage tracking, logging and CI/CD automation using Docker, Kubernetes and GitHub Actions
Database Type
MySQL, MS SQL, Oracle, SQLite, PostgreSQL, MongoDB, Azure Cosmos DBWhat's included
| Service Tiers |
Starter
$80
|
Standard
$250
|
Advanced
$500
|
|---|---|---|---|
| Delivery Time | 2 days | 6 days | 10 days |
Number of Revisions | 1 | 2 | Unlimited |
Number of Tables Added | 2 | 10 | 20 |
Schema Diagram | - | ||
Permissions Setup | |||
Import/Export Data | - | ||
Admin Panel Setup | - | - |
About Iftikhar
Data Engineer | ETL/ELT, Kafka, Databricks, Snowflake | AWS, Azure
Lahore, Pakistan - 11:46 am local time
🔹 What I Can Do for You:
Database Architecture & Optimization → Design and tune high-performance data models, cutting query time from hours to minutes.
Design and build scalable data pipelines (batch + streaming) using Python, SQL, Apache Kafka, Apache Spark, Airflow, and cloud platforms (AWS, GCP, Azure).
Develop data lakes, data warehouses, and lakehouse architectures that support high-performance analytics and real-time reporting.
Implement data validation, monitoring, lineage tracking, and CI/CD automation to ensure reliability and maintainability.
Optimize data workflows for cost, performance, and scalability while adhering to best practices in architecture and design.
Collaborate closely with analytics and ML teams to deliver feature-ready datasets for business intelligence and machine learning workflows.
🔹 Tech Stack:
Programming & Tools: Python (Pandas, Flask, Django, FastAPI, REST APIs), SQL, Bash Scripting, Spark
Cloud Platforms: AWS (S3, Redshift, RDS, Lambda, EMR, Athena), GCP (BigQuery, GKE, Cloud Storage), Azure
Data Engineering: Apache Kafka, Apache NiFi, Apache Airflow, Databricks, Delta Lake, Hive, ELK Stack (Elasticsearch, Logstash, Kibana), FluentD, Informatica (PowerCenter)
DevOps & CI/CD: Docker, Kubernetes, Linux, AWS CloudFormation, Git, GitHub Actions, GitLab CI/CD
BI & Visualization: Power BI, Kibana, Amazon QuickSight
Others: Data Warehousing, ETL / ELT Pipelines, Real-Time Streaming, Data Integration, Data Pipelines, Microservices Architecture, Star & Snowflake Schema, Data Validation, Monitoring & Lineage, Logging & Alerting Pipelines
🔹 Why Clients Hire Me
Enterprise-grade experience (GSK)
Clear communication & documentation
Ownership mindset, I treat your data as critical infrastructure
Focus on business outcomes, not just tools.
📩 If you need a Data Engineer who can own your data workflows end-to-end, let’s talk.
Steps for completing your project
After purchasing the project, send requirements so Iftikhar can start the project.
Delivery time starts when Iftikhar receives requirements from you.
Iftikhar works on your project following the steps below.
Revisions may occur after the delivery date.
Requirements review
Analyze data sources, target warehouse and pipeline scope
ETL pipeline development
Build Python and Airflow pipelines for extraction, transformation and loading