You will get data extracted from PDFs into the data format you want

Project details
With 5+ years of experience on automated data extraction over PDF files, I've built SpeedyF which reduces hours/days of work to minutes. By utilizing SpeedyF, I can deliver captured clean data from thousands of PDF pages.
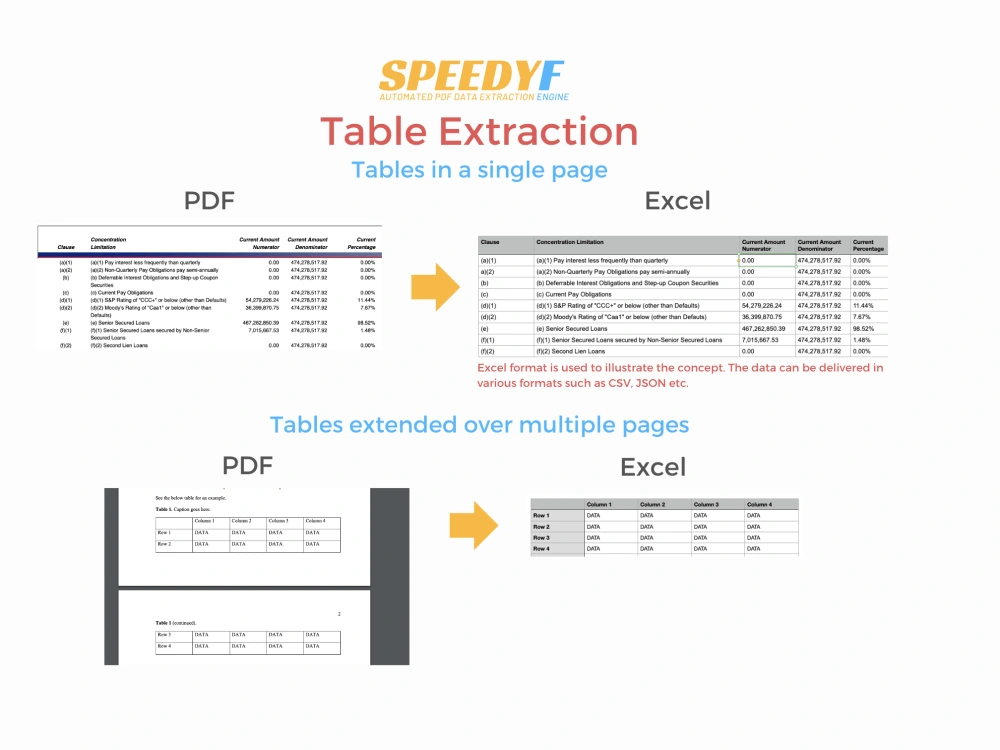
Please see the images on what types of data I can extract using SpeedyF.
This pricing and deliverables are intended to serve basic needs only. If you
• have many PDF files or/and large documents
• need ongoing PDF extraction
• need integration of SpeedyF into your system
then let's have a chat.
Feel free to contact me if you need additional information.
Please see the images on what types of data I can extract using SpeedyF.
This pricing and deliverables are intended to serve basic needs only. If you
• have many PDF files or/and large documents
• need ongoing PDF extraction
• need integration of SpeedyF into your system
then let's have a chat.
Feel free to contact me if you need additional information.
Data Tool
PythonWhat's included $150
These options are included with the project scope.
$150
- Delivery Time 1 day
- Number of Pages Mined/Scraped 100
- Number of Sources Mined/Scraped 1
- Number of Revisions 0
Optional add-ons
You can add these on the next page.
Additional Page Mined/Scraped
(+ 1 Day)
+$1
Additional Source Mined/Scraped
(+ 1 Day)
+$50
Additional Revision
+$20
Data normalization
+$20About Yigit
Senior Python Developer | Data Engineer
Mugla, Turkey - 8:48 am local time
My main focus is building pipelines that makes hidden/buried data useful, including design and development of
🔹 Data extraction systems by use of Machine Learning
🔹 Backend and database models
🔹 User interfaces to monitor or take action on the pipeline/data
NOTABLE PRODUCTS
▔▔▔▔▔▔▔▔▔▔
① Data warehouse to collect extensive data of financial vehicles through various data sources, which includes:
⦾ Data agnostic PDF extraction engine to process thousands of pages daily
⦾ Data agnostic internet bot manager to perform actions over web pages and collect data
⦾ Text extraction engine to capture data from emails
⦾ Event driven workflow engine to orchestrate the data pipeline
⦾ Backend/Frontend for user interventions on workflow and data monitoring
② Data warehouse to capture emotions of actors/actresses from TV shows or movies by use of videos and screenplay scripts
③ Patented audio content recognition (ACR) technology to engage viewers of TV shows/movies via smartphones
PROGRAMMING LANGUAGES / TECHNOLOGIES
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
Python: pandas, numpy, sklearn, TensorFlow, OpenCV, sns, Flask, Django, Selenium, nltk, SpaCy, celery, Spark, AirFlow, Kafka, RabbitMQ, gunicorn
JavaScript: Node.js (express, Apollo, Axios), React (hooks, MaterialUI)
DATABASE SYSTEMS
▔▔▔▔▔▔▔▔▔▔
NoSQL: MongoDB, AWS DynamoDB
SQL: MSSQL, MySQL, SQLite
Graph: Neo4j
Logging: Graylog
CLOUD TECHNOLOGIES
▔▔▔▔▔▔▔▔▔▔▔▔
Amazon Web Services: EC2, Lambda, S3, RDS, DynamoDB, Rekognition, Transcribe, EBS, CodePipeline, SQS, SNS, IAM
VERSION TRACKING / ISSUE MANAGEMENT
▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔
Github, BitBucket, Jira
Steps for completing your project
After purchasing the project, send requirements so Yigit can start the project.
Delivery time starts when Yigit receives requirements from you.
Yigit works on your project following the steps below.
Revisions may occur after the delivery date.
Review extraction requirements
This is a tentative step to clearly understand the data, in case anything is vague.