You will get Data Pipeline with PySpark and Azure
Project details
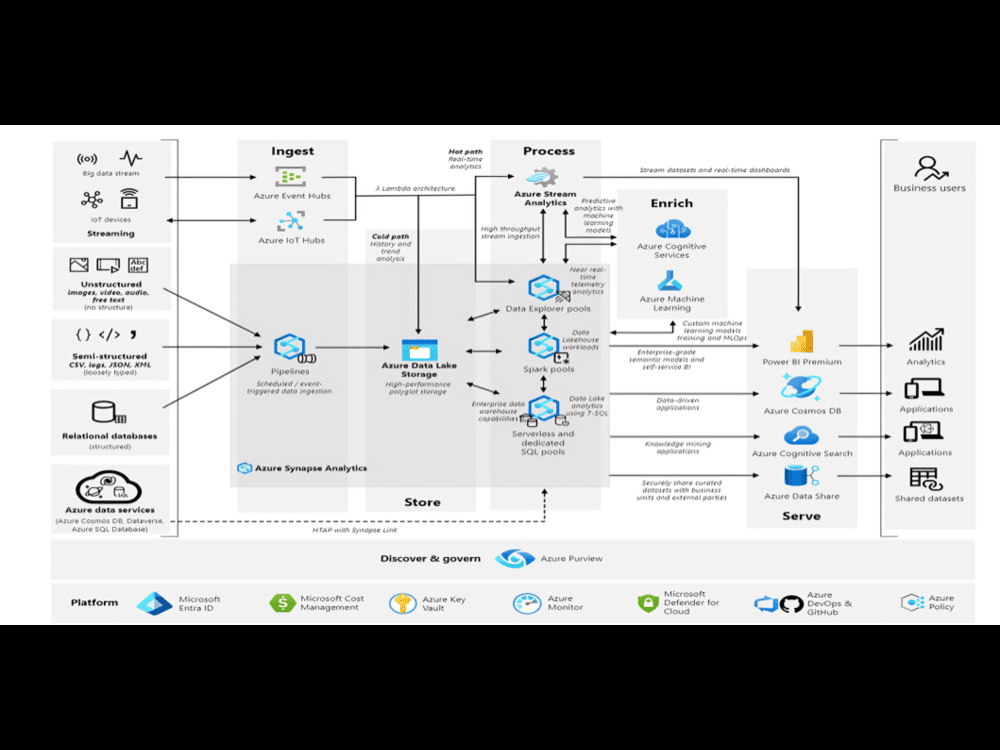
I specialize in building scalable, high-performance data pipelines using Azure and PySpark, ensuring seamless data processing, storage, and analysis. My approach focuses on efficiency, automation, and cost optimization, helping businesses unlock insights faster.
What makes my work stand out:
✔ End-to-End Expertise – From data ingestion to transformation and visualization, I handle the full pipeline lifecycle.
✔ Optimized Performance – Leveraging PySpark’s parallel processing and Azure’s cloud capabilities for speed and efficiency.
✔ Secure & Scalable Solutions – Implementing best practices in security, access control, and compliance (GDPR, HIPAA).
✔ Customized Approach – I tailor every project to the client's specific needs, ensuring long-term value.
By combining technical expertise with business-focused solutions, I deliver high-quality, reliable, and future-proof data engineering pipelines.
What makes my work stand out:
✔ End-to-End Expertise – From data ingestion to transformation and visualization, I handle the full pipeline lifecycle.
✔ Optimized Performance – Leveraging PySpark’s parallel processing and Azure’s cloud capabilities for speed and efficiency.
✔ Secure & Scalable Solutions – Implementing best practices in security, access control, and compliance (GDPR, HIPAA).
✔ Customized Approach – I tailor every project to the client's specific needs, ensuring long-term value.
By combining technical expertise with business-focused solutions, I deliver high-quality, reliable, and future-proof data engineering pipelines.
Database Type
MySQL, MS SQL, Oracle, SQLite, PostgreSQL, MongoDB, Azure Cosmos DBWhat's included
| Service Tiers |
Starter
$15
|
Standard
$20
|
Advanced
$25
|
|---|---|---|---|
| Delivery Time | 3 days | 5 days | 7 days |
Number of Revisions | 5 | 5 | Unlimited |
Query Debugging | |||
Query Optimization | |||
Query Scheduling | |||
Query Analysis | |||
Source Code |
Optional add-ons
You can add these on the next page.
Fast Delivery
+$30 - $50
Additional Revision
+$10
Additional Query
(+ 10 Days)
+$10About Viswalakshmi
Data Engineer | ETL Developer | DWH | Azure | Advance SQL
Mississauga, Canada - 2:44 pm local time
Extensive experience in Snowflake, Azure cloud services, ETL processes, and PySpark for big data processing.
Skilled in Python and SQL with a strong track record of implementing scalable data pipelines and ensuring data integrity.
Expertise in financial data analysis, risk management, and compliance, with a demonstrated ability to collaborate across cross-functional teams.
Excellent communicator with the ability to convey complex technical concepts effectively.
Steps for completing your project
After purchasing the project, send requirements so Viswalakshmi can start the project.
Delivery time starts when Viswalakshmi receives requirements from you.
Viswalakshmi works on your project following the steps below.
Revisions may occur after the delivery date.
Initial Consultation & Requirement Gathering
✅ Conduct a meeting or exchange messages to understand the client’s requirements. ✅ Define project goals, deliverables, and key performance indicators (KPIs). ✅ Confirm budget, timeline, and preferred tools/technologies.
Project Planning & Architecture Design
✅ Design an end-to-end data pipeline architecture using Azure Data Services. ✅ Choose the right technologies (Azure Data Factory, Databricks, PySpark, SQL, etc.). ✅ Create a detailed project roadmap with milestones and deadlines and provide workflow.