You will get Design a Scalable Data Architecture for Your Business
Rising Talent

Rising Talent
Project details
Are you building a data platform or struggling with scalability, performance, or unclear architecture?
I will design a robust, scalable, and cost-efficient data architecture tailored to your business needs whether you're starting from scratch or improving an existing system.
What you’ll get
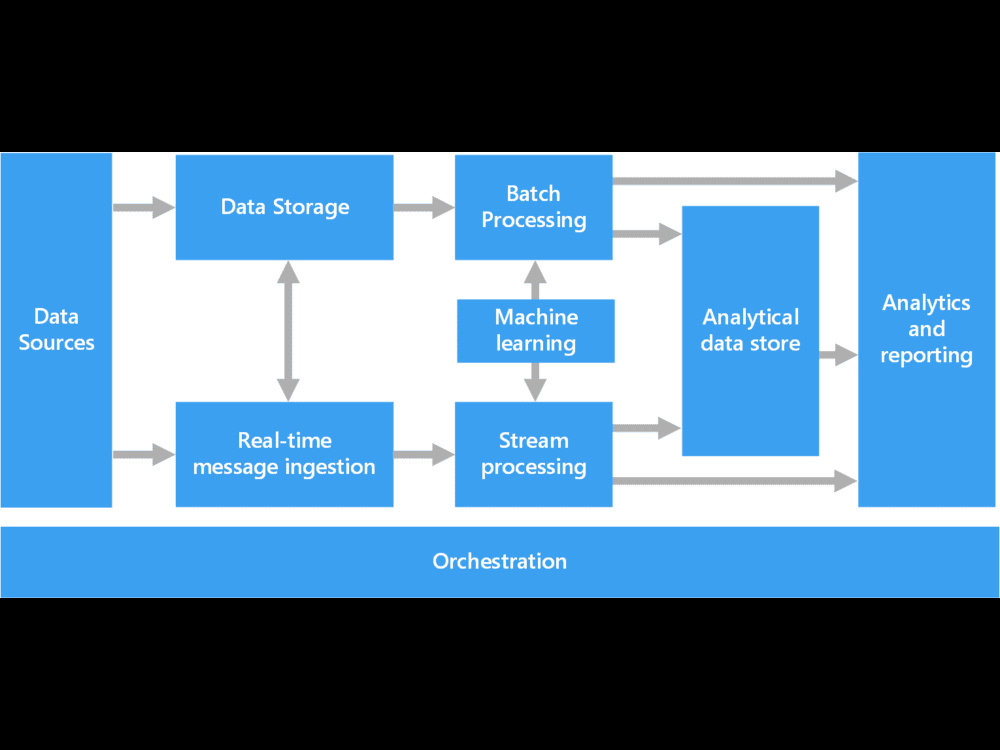
End-to-end data architecture design
Batch & real-time pipeline design
Data storage strategy (Data Lake / Warehouse / Lakehouse)
Tool stack recommendation (AWS, Azure, GCP, Snowflake, Databricks, etc.)
Architecture diagrams (professional & easy to understand)
Implementation roadmap
My approach
Requirement gathering & use case understanding
Current system analysis (if available)
Architecture design aligned with scalability & cost
Documentation & next steps
Who this is for
Startups building data platforms
Companies scaling data pipelines
Teams needing architecture clarity
I will design a robust, scalable, and cost-efficient data architecture tailored to your business needs whether you're starting from scratch or improving an existing system.
What you’ll get
End-to-end data architecture design
Batch & real-time pipeline design
Data storage strategy (Data Lake / Warehouse / Lakehouse)
Tool stack recommendation (AWS, Azure, GCP, Snowflake, Databricks, etc.)
Architecture diagrams (professional & easy to understand)
Implementation roadmap
My approach
Requirement gathering & use case understanding
Current system analysis (if available)
Architecture design aligned with scalability & cost
Documentation & next steps
Who this is for
Startups building data platforms
Companies scaling data pipelines
Teams needing architecture clarity
Database Type
MySQL, MS Access, Oracle, SQLite, PostgreSQL, MongoDB, TeradataWhat's included
| Service Tiers |
Starter
$40
|
Standard
$100
|
Advanced
$200
|
|---|---|---|---|
| Delivery Time | 1 day | 2 days | 6 days |
Number of Revisions | 0 | 1 | 3 |
Number of Tables Added | 3 | 4 | 4 |
Schema Diagram | - | ||
Permissions Setup | - | ||
Import/Export Data | - | ||
Admin Panel Setup | - |
About Muhammad
Data Engineer | Databricks, Azure, Spark, Airflow | Pipelines & DWH
Islamabad, Pakistan - 4:15 am local time
In 4 years across banking, telecom, and fast-moving startups, here's what I've delivered:
• Designed a Data Lakehouse using Apache Iceberg, Spark & MinIO — processing structured + unstructured data at scale
• Built event-driven pipelines (Kafka → Elasticsearch) with 20% improvement in system efficiency
• Created KPI dashboards used by 2,500+ employees daily, saving 20+ hours/week of manual reporting
• Managed 30+ production data pipelines with high availability and scheduled reporting
• Migrated large-scale Hadoop/Hive workloads to modern platforms and built production Databricks + Azure Data Factory pipelines
• Automated website analytics collection using Airflow + SQL, saving cost equivalent to 3 employees per site
━━━━━━━━━━━━━━━━━━━━
WHAT I DO BEST:
• Data Pipeline Development
- End-to-end ETL/ELT pipelines using Python, SQL, Spark, Airflow, NiFi, and dbt
- Idempotent design with retries, backfills, error handling, and data validation
- Batch and near real-time (CDC) ingestion from APIs, databases, files, and streams
• Data Lakehouse & Warehouse
- Architecture using Databricks, Apache Iceberg, Snowflake, Synapse, Redshift, and Doris
- Medallion architecture (Bronze/Silver/Gold) with schema evolution and data quality gates
- Dimensional modeling, star/snowflake schemas, SCD2, and naming conventions
• Microsoft / Azure Data Stack
- Production pipelines with Azure Data Factory and Databricks
- Synapse Analytics for warehousing and analytics workloads
- Microsoft Fabric for unified data and reporting
• Big Data Platforms
- Hadoop, Hive, and Ambari for large-scale data processing
- Hadoop-to-cloud migrations and legacy system modernization
- HiveQL optimization, partitioning, and ORC/Parquet tuning
• Real-Time Streaming
- Kafka-based event-driven architectures feeding Elasticsearch
- Stream processing with monitoring and alerting (Grafana / Loki)
- Back-pressure handling and pipeline throughput tuning
• Cloud Data Infrastructure
- AWS (S3, Glue, Redshift, Athena, Lambda, Kinesis) setup and optimization
- Cost optimization (FinOps), storage tiering, and performance tuning
- Containerized workloads with Docker
• BI & Dashboards
- Power BI, Grafana, Kibana dashboards built for real decision-making
- Data governance, security, and role-based access
- KPI tracking from executive overview down to detail level
• SQL & Performance Tuning
- Complex queries, window functions, CTEs across PostgreSQL, MySQL, SQL Server, Oracle
- Query optimization, indexing strategy, and execution-plan analysis
━━━━━━━━━━━━━━━━━━━━
MY TECH STACK:
• Languages: Python (Django, Flask, FastAPI), SQL, PL/SQL, NoSQL
• Data Tools: Apache Airflow, Spark/PySpark, Kafka, NiFi, dbt, Trino
• Microsoft/Azure: Databricks, Azure Data Factory, Synapse Analytics, Microsoft Fabric
• Big Data: Hadoop, Hive, Ambari
• Cloud: AWS (S3, Lambda, Glue, Redshift, Athena, Kinesis), Docker
• Warehousing & Storage: Snowflake, Apache Iceberg, MinIO, Elasticsearch, Apache Doris
• Databases: PostgreSQL, MySQL, SQL Server, Oracle
• BI & Monitoring: Power BI, Grafana, Kibana, Loki
━━━━━━━━━━━━━━━━━━━━
CERTIFICATIONS:
• AWS Certified Solutions Architect – Associate
• Astronomer Certified Apache Airflow 3
━━━━━━━━━━━━━━━━━━━━
INDUSTRIES I'VE WORKED IN:
• Banking & Fintech
• Telecom
• Technology Startups
━━━━━━━━━━━━━━━━━━━━
Whether you need a data pipeline built from scratch, a messy warehouse cleaned up, a Hadoop-to-cloud migration, a real-time streaming system, or a dashboard that actually gets used — message me and let's talk specifics. I respond within 2 hours.
Steps for completing your project
After purchasing the project, send requirements so Muhammad can start the project.
Delivery time starts when Muhammad receives requirements from you.
Muhammad works on your project following the steps below.
Revisions may occur after the delivery date.
working on solution design
after requirements gathering uzair will start working on solution design and provide timely update on it.