You will get Edge AI Model Deployment

Project details
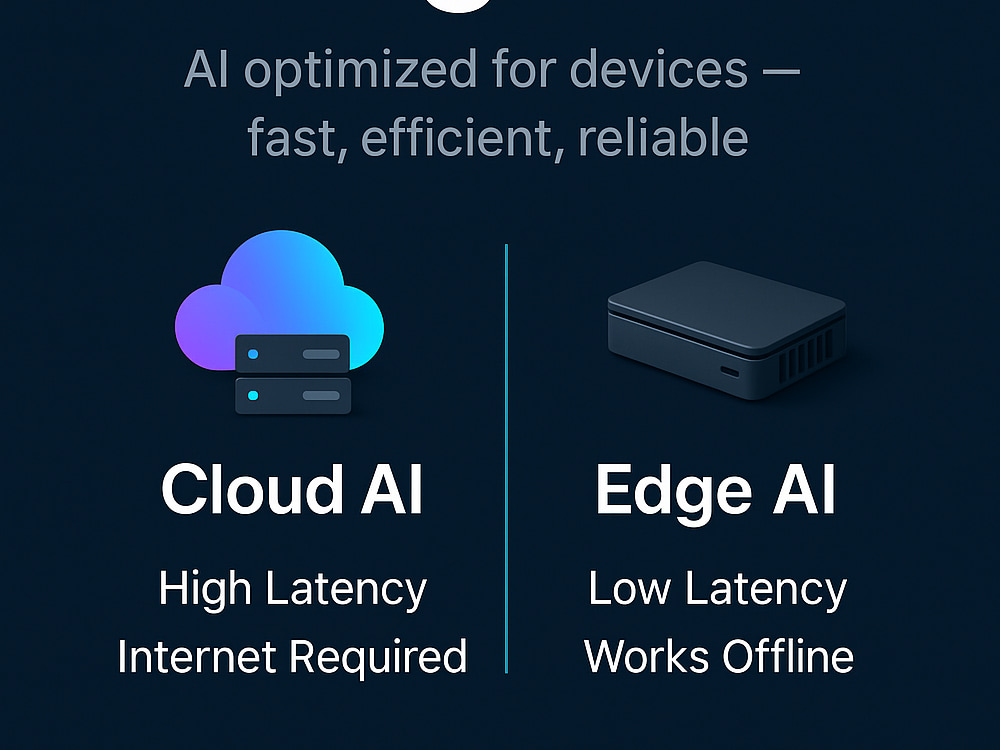
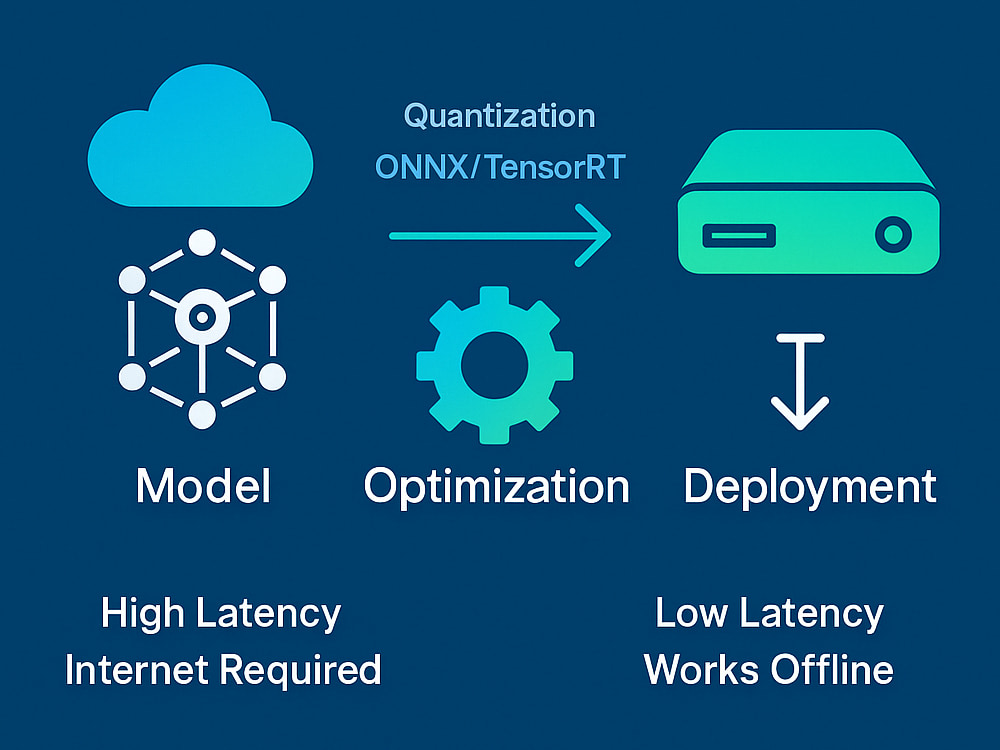
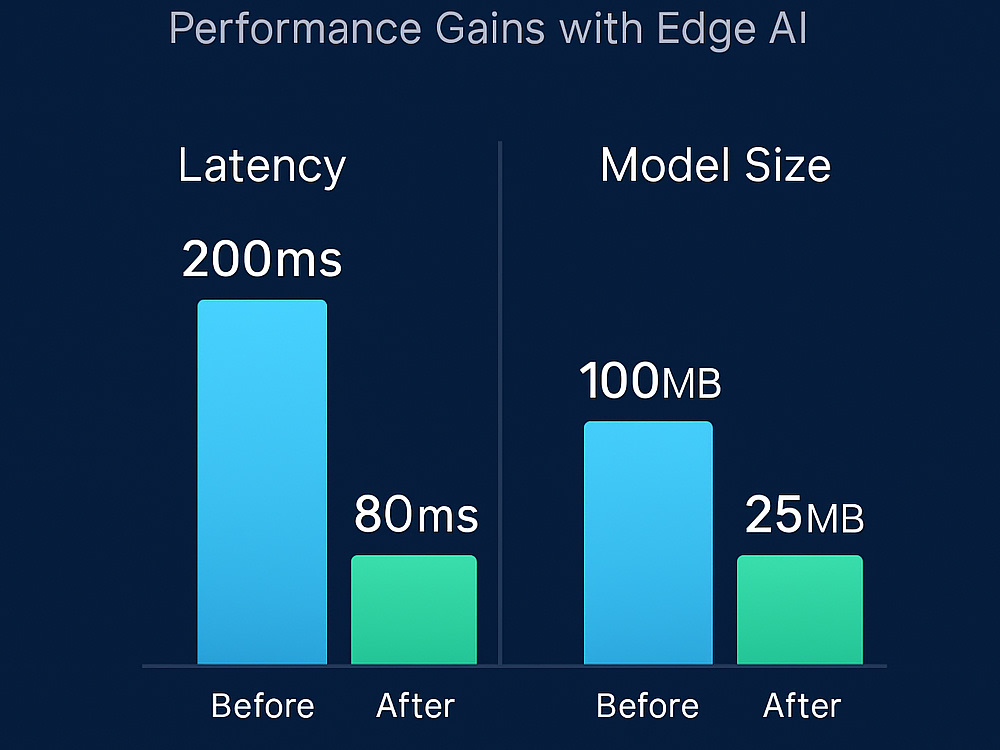
I deliver end-to-end Edge AI model deployment on embedded platforms like NVIDIA Jetson, NXP i.MX, and Raspberry Pi. From model optimization (TensorRT, ONNX, quantization) to integration with Linux-based environments, I ensure your AI runs fast, efficient, and reliable directly on-device.
With proven experience in automotive, robotics, and IoT, I bring production-grade deployment skills including latency benchmarking, thermal/power profiling, and regulatory alignment (ISO 26262, CSMS/SUMS). You’ll receive a fully optimized, tested, and documented AI pipeline — ready to run offline, with minimal latency, and tailored to your hardware.
With proven experience in automotive, robotics, and IoT, I bring production-grade deployment skills including latency benchmarking, thermal/power profiling, and regulatory alignment (ISO 26262, CSMS/SUMS). You’ll receive a fully optimized, tested, and documented AI pipeline — ready to run offline, with minimal latency, and tailored to your hardware.
Machine Learning Tools
Databricks MLflow, Keras, MLflow, NumPy, NVIDIA AI Platform, Open Neural Network Exchange, OpenCV, pandas, Python Scikit-Learn, PyTorch, scikit-learn, TensorFlow, XGBoostWhat's included
| Service Tiers |
Starter
$299
|
Standard
$749
|
Advanced
$1,499
|
|---|---|---|---|
| Delivery Time | 5 days | 10 days | 20 days |
Number of Revisions | 1 | 2 | 3 |
Number of Model Variations | 1 | 2 | 3 |
Number of Scenarios | 1 | 2 | 3 |
Number of Graphs/Charts | 0 | 2 | 3 |
Model Validation/Testing | - | ||
Model Documentation | - | - | |
Data Source Connectivity | - | - | |
Source Code |
Optional add-ons
You can add these on the next page.
Fast Delivery
+$99 - $399
Additional Revision
+$74
Additional Model Variation
(+ 3 Days)
+$199
Additional Scenario
(+ 2 Days)
+$149
Additional Graph/Chart
(+ 1 Day)
+$49
Model Validation/Testing
(+ 3 Days)
+$199
Model Documentation
(+ 2 Days)
+$149
Data Source Connectivity
(+ 4 Days)
+$299About Murat
Edge AI Engineer | Embedded Linux, Model Optimization & Deployment
Istanbul, Turkey - 12:35 pm local time
Most AI models are built for servers — too heavy for real-time use on devices. I specialize in Edge AI engineering, combining my background in embedded systems and Linux-based platforms with AI/ML model optimization to deliver fast, reliable, and efficient AI on resource-constrained hardware.
💡 What I do:
Optimize and deploy ML/DL models (PyTorch, TensorFlow, ONNX, TFLite, OpenVINO, TensorRT).
Build & customize embedded Linux/QNX platforms for AI applications.
Accelerate models with quantization, pruning, GPU/NPU/TPU integration.
Design real-time inference pipelines for video, audio, and sensor data.
Integrate AI with robotics, automotive, and IoT systems.
⚡ Why clients choose me:
Strong background in C++/Rust/Python and cross-compilation for ARM & heterogeneous platforms.
Hands-on with NVIDIA Jetson, NXP i.MX, Raspberry Pi, Intel Movidius, and similar edge hardware.
Proven experience in automotive, robotics, and embedded software engineering.
Focused on performance, low-power, and reliability — critical for production environments.
If you need AI that runs where it matters most — at the edge — I can help.
Steps for completing your project
After purchasing the project, send requirements so Murat can start the project.
Delivery time starts when Murat receives requirements from you.
Murat works on your project following the steps below.
Revisions may occur after the delivery date.
Requirement Gathering
Collection of hardware details (Jetson, NXP, RPi, etc.), software stack info, and AI model specifications..
Model Optimization
Optimization of the provided model (quantization, pruning, TensorRT/ONNX conversion) for performance without losing accuracy.