You will get Enterprise RAG Web Platform, Hybrid Search, OCR, Vector DB, LLM Integration
Project details
Transform your documents and internal knowledge into a fully searchable AI chat assistant, built on a production-grade RAG stack.
What you get:
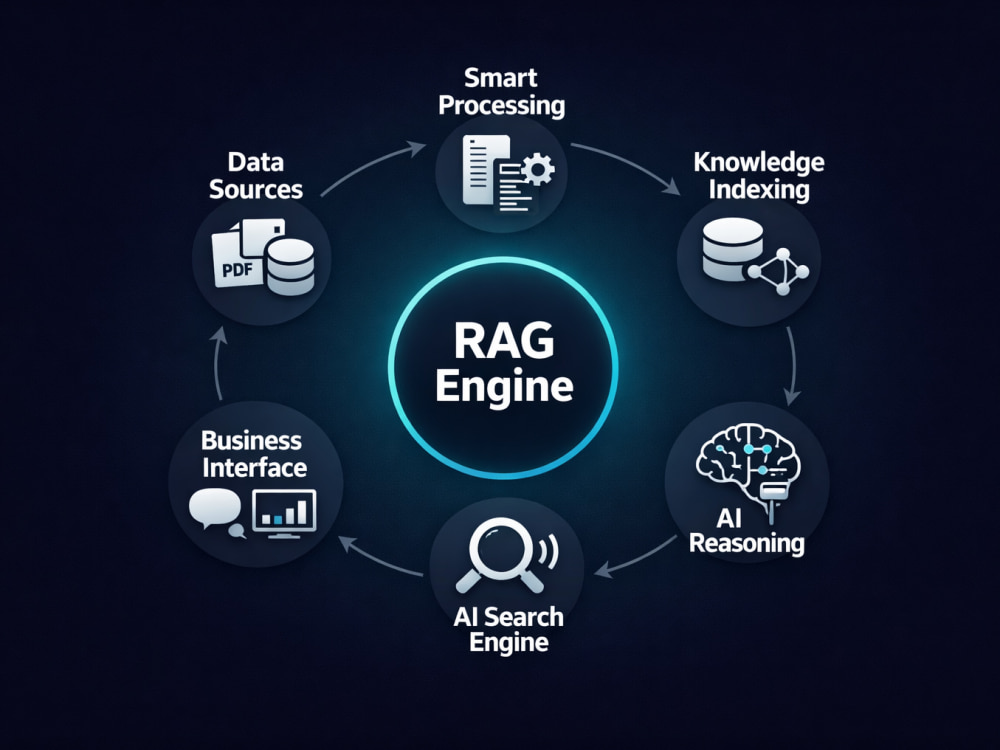
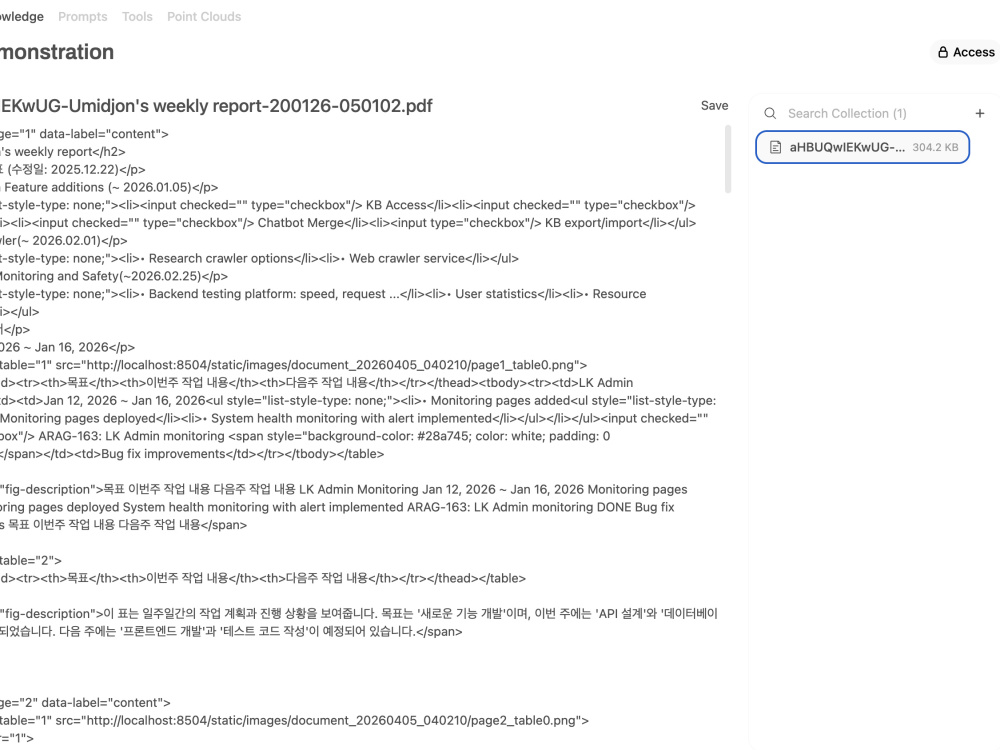
📥 Document ingestion: PDF, DOCX, spreadsheets, and scanned images — auto extracted, cleaned, chunked, and indexed into your knowledge base.
🔍 OCR extraction: Scanned documents and image-based PDFs become fully searchable with no text layer required.
⚡ Hybrid search: BM25 keyword search and semantic vector search run together for best-of-both-worlds retrieval and maximum recall.
🎯 Rerankingl reranking retrieved results before they reach the LLM, delivering sharper and more relevant answers.
🗄️ Vector DB (supported): Elasticsearch, Pgvector, Qdrant, Weaviate, Pinecone.
🏛️ Relational DB (supported): PostgreSQL, SQLite, MySQL.
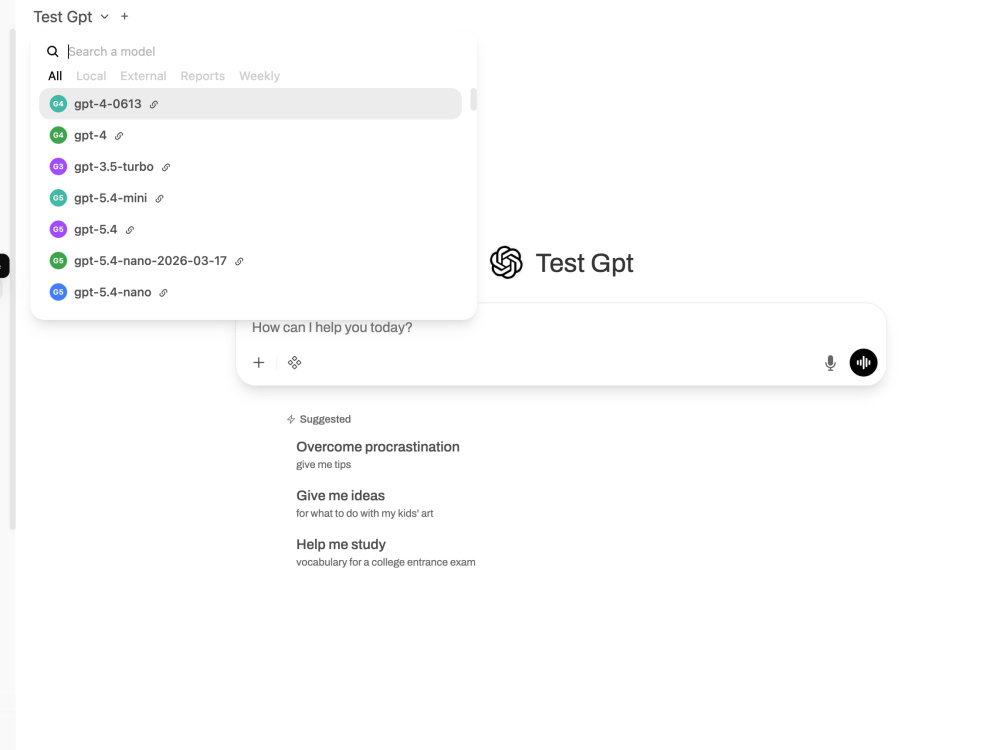
💬 Chat webapp: A polished, self-hosted frontend connected to any LLM: OpenAI, Anthropic, Ollama, or your own model.
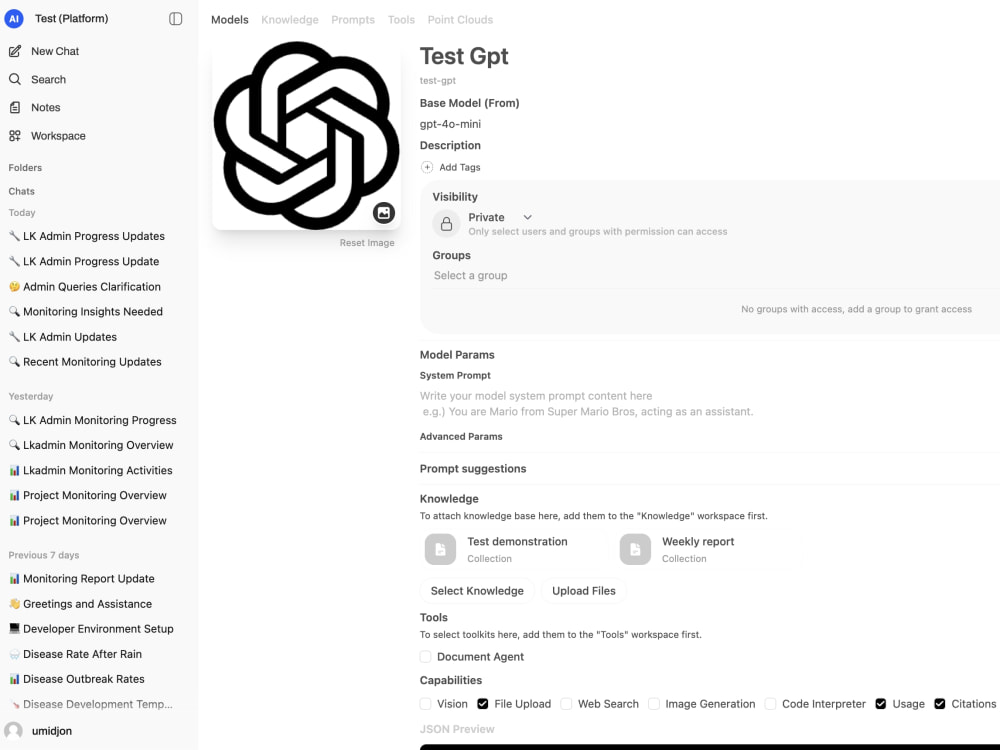
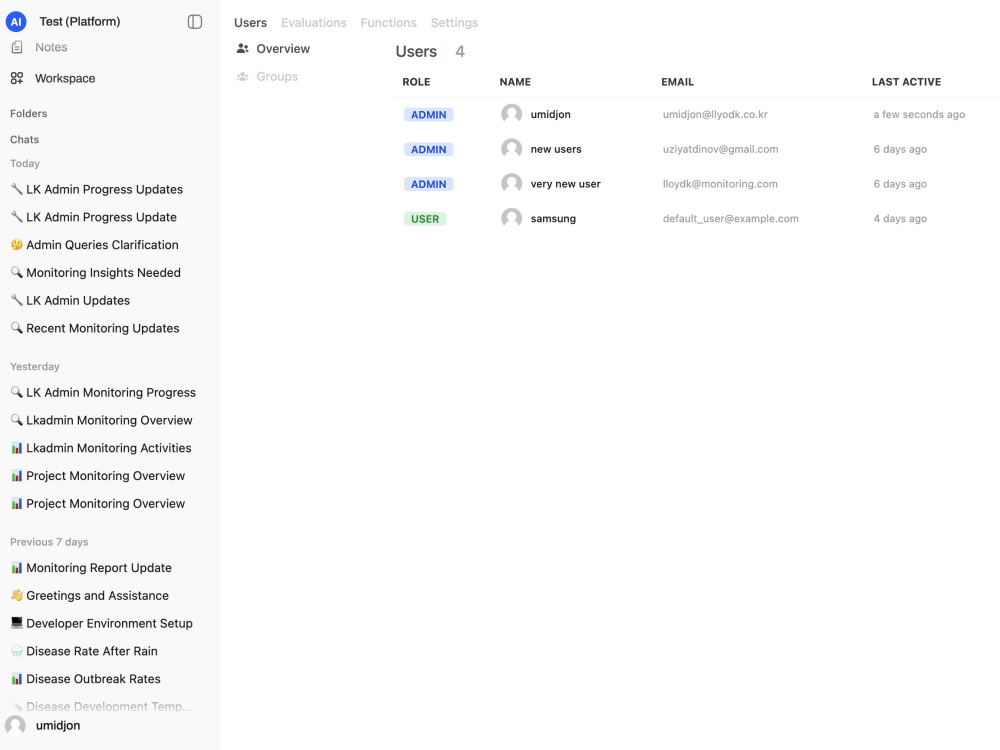
🛠️ Admin dashboard: Manage users, roles, knowledge bases, retrieval settings, and model configurations from one place.
📊 Observability: Track user's token usage, response, latency, and cost.
🐳 Fully Dockerized: Clean, reproducible, and portable deployments on any Linux server or VPS.
What you get:
📥 Document ingestion: PDF, DOCX, spreadsheets, and scanned images — auto extracted, cleaned, chunked, and indexed into your knowledge base.
🔍 OCR extraction: Scanned documents and image-based PDFs become fully searchable with no text layer required.
⚡ Hybrid search: BM25 keyword search and semantic vector search run together for best-of-both-worlds retrieval and maximum recall.
🎯 Rerankingl reranking retrieved results before they reach the LLM, delivering sharper and more relevant answers.
🗄️ Vector DB (supported): Elasticsearch, Pgvector, Qdrant, Weaviate, Pinecone.
🏛️ Relational DB (supported): PostgreSQL, SQLite, MySQL.
💬 Chat webapp: A polished, self-hosted frontend connected to any LLM: OpenAI, Anthropic, Ollama, or your own model.
🛠️ Admin dashboard: Manage users, roles, knowledge bases, retrieval settings, and model configurations from one place.
📊 Observability: Track user's token usage, response, latency, and cost.
🐳 Fully Dockerized: Clean, reproducible, and portable deployments on any Linux server or VPS.
AI Algorithms
Large Language Model, Multimodal Large Language Model, Transformer ModelAI Applications
AI Chatbot, AI-Enhanced Classification, Image Processing, Sentiment AnalysisAI Development Language
PythonAI Tools
Azure OpenAI, Hugging Face, Microsoft 365 Copilot, NVIDIA AI Platform, PyTorchAI Models
ChatGPT, DALL-E, GPT-3, LLaMA, Midjourney AIWhat's included
| Service Tiers |
Starter
$100
|
Standard
$300
|
Advanced
$1,000
|
|---|---|---|---|
| Delivery Time | 3 days | 7 days | 20 days |
Number of Revisions | 3 | 5 | 13 |
AI Model Integration | |||
Batch Normalization | - | - | - |
Database Integration | |||
Detailed Code Comments | - | - | - |
Image Upscaling | - | - | - |
MLOps | - | ||
Model Deployment | - | ||
Model Documentation | - | - | - |
Model Monitoring | - | ||
Model Testing & Optimization | - | - | - |
Model Tuning | - | - | - |
Natural Language Processing | - | - | - |
NLP Tokenization | - | - | - |
Pre-Training | - | - | - |
Prompt Engineering | - | - | - |
Setup File | - | - | - |
Source Code | - | - |
Optional add-ons
You can add these on the next page.
Server Deployment
(+ 1 Day)
+$100
OCR Deployment
+$200Frequently asked questions
About Umidjon
AI Developer Ai Agents | RAG | AI Tools | Openclaw | N8N | FastAPI
Seoul, South Korea - 3:44 am local time
If your chatbot is inaccurate or your AI setup is broken, I can fix or deploy it fast.
I build Ai pipelines and MVP using FastAPI and Nextjs, focused on chatbot systems, document AI, and API integrations.
I make sure your system is accurate, stable, and ready for real usage not just demos. ⚙️
I work on
• Document ingestion, chunking, embeddings, and vector databases
• Fixing retrieval issues so answers are correct and not hallucinated
• Improving latency, stability, and backend performance
• Deploying AI systems on Linux servers with Docker
I also fix broken AI systems. 🛠️
If your RAG pipeline or chatbot is not working properly, I quickly debug and improve retrieval quality, embeddings, and overall system behavior.
What I can help you with 👇
• RAG chatbot with your documents
• FastAPI backend for AI applications
• Fixing broken AI systems and improving accuracy
• AI deployment on VPS with Docker
• Document AI and internal tools
I focus on simple, reliable solutions that work in production and are easy to maintain. ✅
I can build a free POC for your use case so you can see results before committing. If it works, we continue.
Steps for completing your project
After purchasing the project, send requirements so Umidjon can start the project.
Delivery time starts when Umidjon receives requirements from you.
Umidjon works on your project following the steps below.
Revisions may occur after the delivery date.
Discovery & Requirement Check
Confirm tier, server access, and requirements. Run pre-flight checks on ports, disk, and Docker.
Configuration & Setup
Setup environment configs, prepare Docker Compose, and configure LLM and database connections.