You will get I will build a custom OCR or PDF extraction API with FastAPI & Python
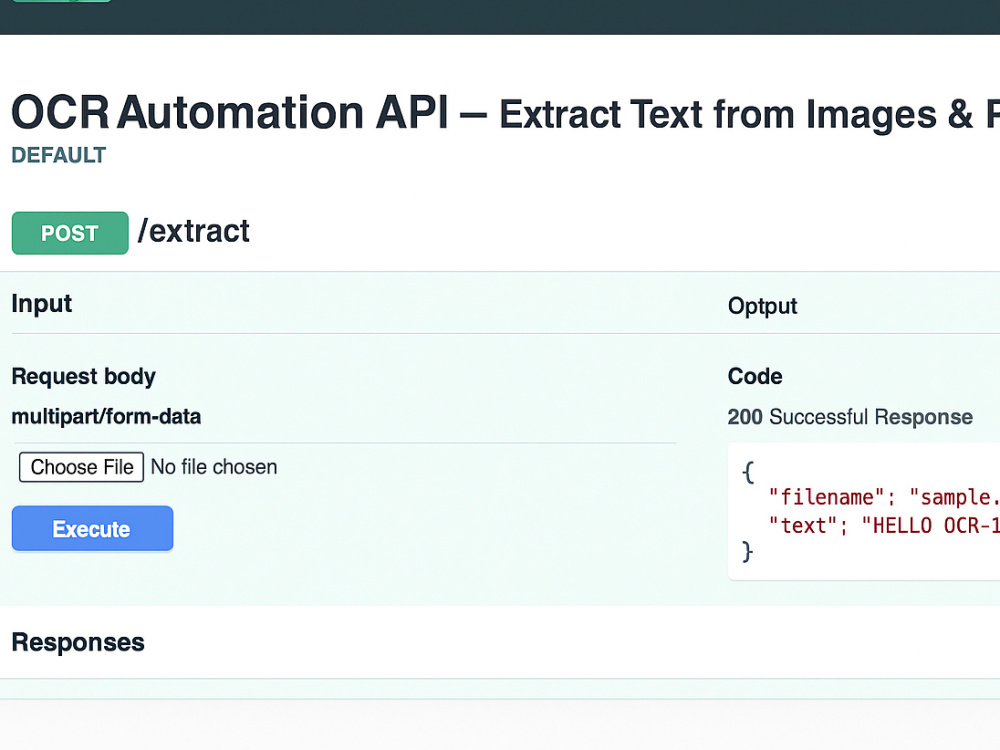
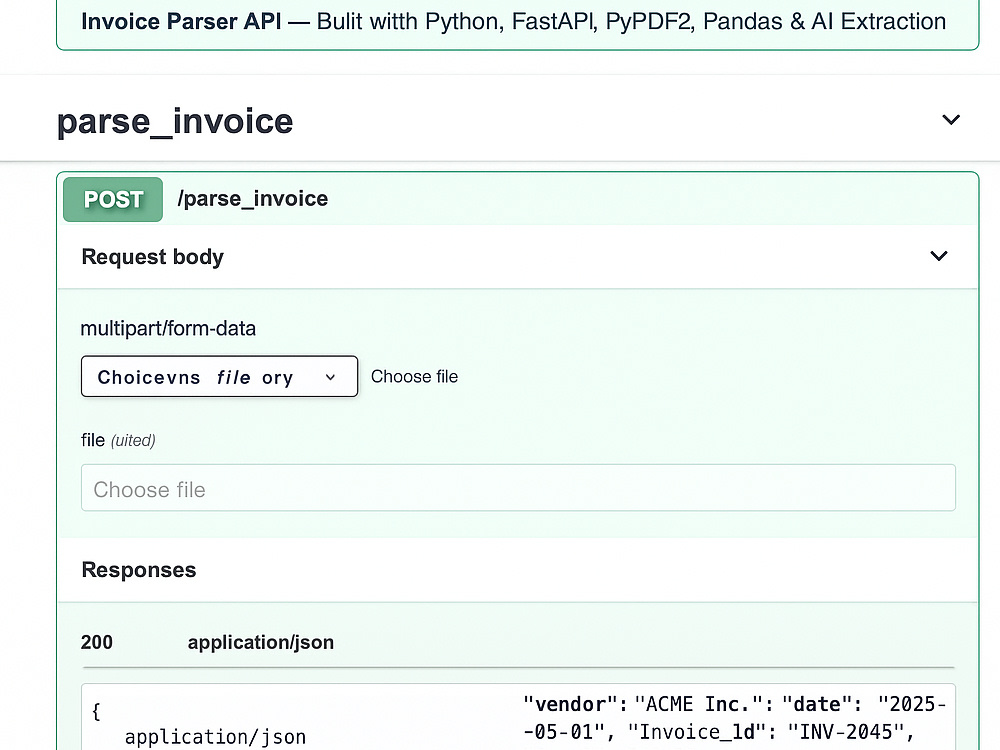
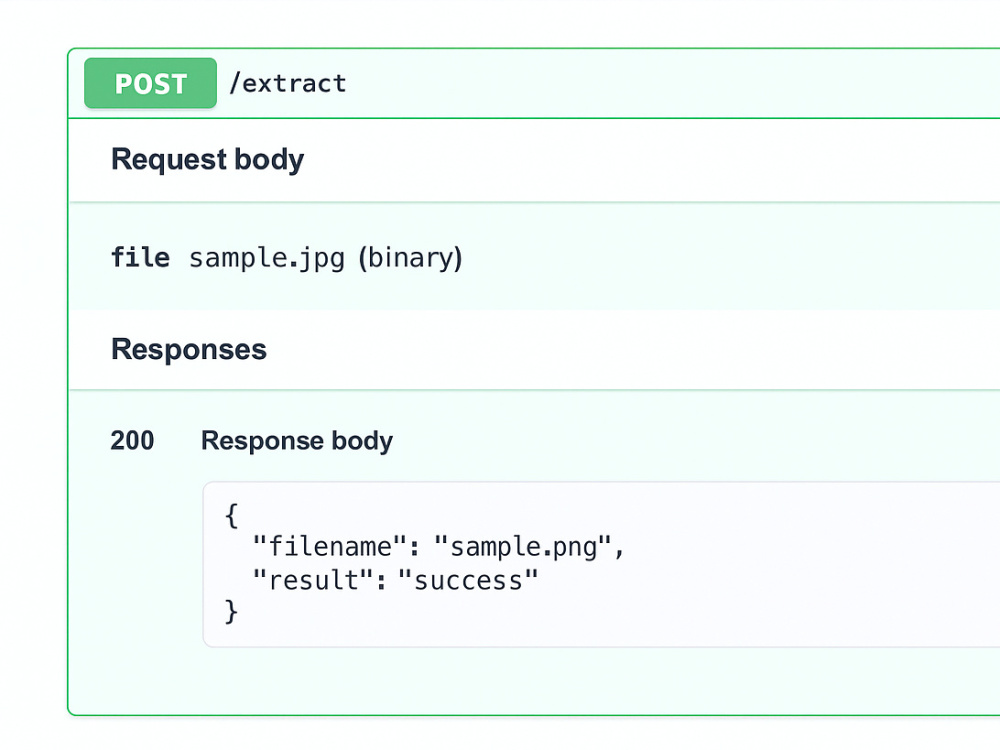
Project details
Bring your own PDF layout & rules. I deliver precise JSON fields + regex/heuristics you control.
Need to turn manual document tasks into a clean, automated API? I build custom OCR and PDF Data Extraction APIs using Python + FastAPI + Tesseract OCR + OpenCV — lightweight, fast, and production-ready. My service converts images or PDF files into structured JSON data, ready to plug into your app or workflow.
✅ Accurate OCR extraction (multi-language supported)
✅ PDF multi-page parsing and text cleaning
✅ FastAPI endpoint with Swagger documentation
✅ Clean, documented Python code
✅ Optional JSON post-processing for finance, receipts, or invoices
If you need something precise, robust, and built like a product — I’ll deliver it.
**Tech stack:** Python · FastAPI · OpenCV · Tesseract · PyPDF2 · Pandas · REST API.
Communication is text-only for maximum clarity and speed.
Need to turn manual document tasks into a clean, automated API? I build custom OCR and PDF Data Extraction APIs using Python + FastAPI + Tesseract OCR + OpenCV — lightweight, fast, and production-ready. My service converts images or PDF files into structured JSON data, ready to plug into your app or workflow.
✅ Accurate OCR extraction (multi-language supported)
✅ PDF multi-page parsing and text cleaning
✅ FastAPI endpoint with Swagger documentation
✅ Clean, documented Python code
✅ Optional JSON post-processing for finance, receipts, or invoices
If you need something precise, robust, and built like a product — I’ll deliver it.
**Tech stack:** Python · FastAPI · OpenCV · Tesseract · PyPDF2 · Pandas · REST API.
Communication is text-only for maximum clarity and speed.
Machine Learning Tools
OpenCV, pandas, Python, Tesseract OCRWhat's included
| Service Tiers |
Starter
$50
|
Standard
$150
|
Advanced
$300
|
|---|---|---|---|
| Delivery Time | 2 days | 4 days | 7 days |
Number of Revisions | 1 | 2 | 2 |
Number of Model Variations | 0 | 0 | 0 |
Number of Scenarios | 0 | 0 | 0 |
Number of Graphs/Charts | 0 | 0 | 0 |
Model Validation/Testing | - | - | - |
Model Documentation | - | - | - |
Data Source Connectivity | - | - | - |
Source Code | - | - | - |
Frequently asked questions
About Fabien
AI Automation Project Manager - OCR and Data Extraction Specialist
New York, United States - 2:37 pm local time
I build lightweight, fast, and reliable AI solutions using Python, FastAPI, Tesseract, and OpenCV. My focus is helping businesses and freelancers turn manual document tasks into fully automated workflows — saving hours every day.
💡 What I can deliver:
• OCR systems (images, PDFs, receipts → structured text)
• Document parsing & data extraction APIs
• Image background removal & preprocessing
• FastAPI microservices ready for deployment
• End-to-end automation pipelines
⚙️ Tech stack:
Python · FastAPI · Tesseract · OpenCV · Pillow · REST APIs · Stripe · Git
📝 Communication:
For accessibility reasons, I only communicate via **written messages (text-only)**.
This ensures clarity, focus, and faster delivery.
If you’re looking for someone who works precisely, writes clean code, and values efficiency — let’s collaborate!
Steps for completing your project
After purchasing the project, send requirements so Fabien can start the project.
Delivery time starts when Fabien receives requirements from you.
Fabien works on your project following the steps below.
Revisions may occur after the delivery date.
Custom API development & delivery
I will set up a custom FastAPI project, integrate OCR & PDF parsing logic, test with your sample files, and deliver the working API with documentation.