You will get I will build a RAG pipeline for your documents or knowledge base
Project details
I build production-ready RAG (Retrieval-Augmented Generation) systems
that let you ask questions over your own documents and get accurate,
cited answers powered by LLMs.
What makes my work different:
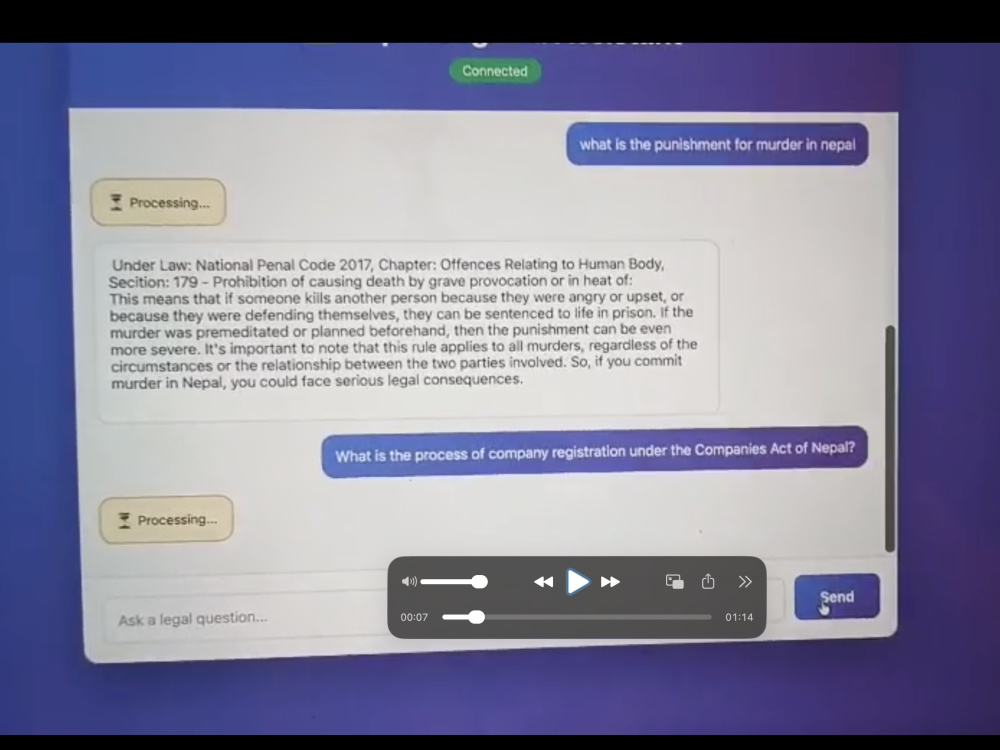
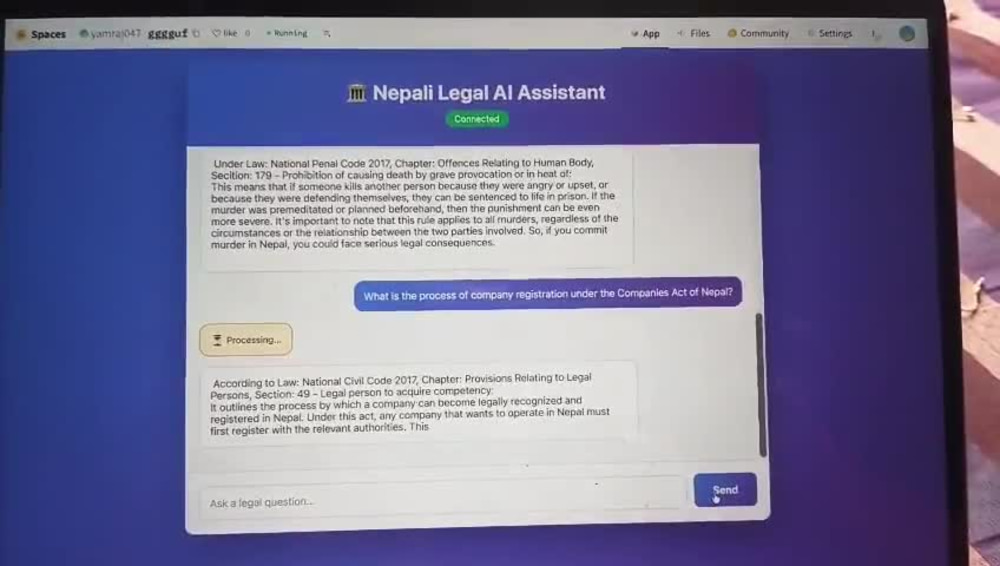
— I've built a full RAG system for Nepal's National Penal Code using
FAISS vector search, bi-encoder + cross-encoder reranking, and
WebSocket streaming. It's live on Hugging Face Spaces.
— I fine-tuned Mistral-7B on legal data — adopted by the open-source
community within 24 hours and redistributed in Q2–Q8 GGUF formats.
— I don't just build notebooks. I deliver working APIs, web apps,
and documented code you can actually use.
What you get:
✅ Document ingestion and chunking pipeline
✅ FAISS vector embeddings for fast semantic search
✅ LLM-powered Q&A grounded in your documents
✅ FastAPI endpoint ready for integration
✅ Clean, commented, production-ready code
I'm a Computer Engineering student at IOE Purwanchal Campus, Nepal,
currently interning at Planto AI. I presented my ML research at
ICRTAI 2025 international conference.
Tell me your use case — I'll build it right.
that let you ask questions over your own documents and get accurate,
cited answers powered by LLMs.
What makes my work different:
— I've built a full RAG system for Nepal's National Penal Code using
FAISS vector search, bi-encoder + cross-encoder reranking, and
WebSocket streaming. It's live on Hugging Face Spaces.
— I fine-tuned Mistral-7B on legal data — adopted by the open-source
community within 24 hours and redistributed in Q2–Q8 GGUF formats.
— I don't just build notebooks. I deliver working APIs, web apps,
and documented code you can actually use.
What you get:
✅ Document ingestion and chunking pipeline
✅ FAISS vector embeddings for fast semantic search
✅ LLM-powered Q&A grounded in your documents
✅ FastAPI endpoint ready for integration
✅ Clean, commented, production-ready code
I'm a Computer Engineering student at IOE Purwanchal Campus, Nepal,
currently interning at Planto AI. I presented my ML research at
ICRTAI 2025 international conference.
Tell me your use case — I'll build it right.
AI Development Type
Deep Learning, Knowledge Representation, Model Tuning, Recommendation SystemAI Tools
Azure Machine Learning, deeplearn.js, Deeplearning4j, MLflow, Open Neural Network Exchange, OpenCV, PyTorch, TensorFlowAI Development Language
PythonWhat's included
| Service Tiers |
Starter
$50
|
Standard
$100
|
Advanced
$150
|
|---|---|---|---|
| Delivery Time | 5 days | 8 days | 14 days |
Number of Revisions | 1 | 2 | 3 |
AI Model Integration | |||
Detailed Code Comments | - | ||
Knowledge Graph | - | - | |
Model Documentation | - | ||
Ontology | - | - | - |
Source Code | |||
Taxonomy | - | - | - |
Optional add-ons
You can add these on the next page.
Android App Integration
(+ 7 Days)
+$150Frequently asked questions
About Yamraj
Machine Learning & AI Enthusiast
Dharan, Nepal - 3:36 am local time
I build production ML and AI systems — not just notebooks.
I'm a Computer Engineering student at IOE Purwanchal Campus (Nepal) specializing in Machine Learning, LLMs, Computer Vision, and RAG pipelines. My work has been adopted by the open-source community and presented at international AI conferences.
WHAT I'VE BUILT
— Fine-tuned Mistral-7B on Nepal's National Penal Code → adopted by community maintainer within 24 hours and redistributed in Q2–Q8 GGUF formats for CPU-only inference across the llama.cpp ecosystem
— Built U-Net from scratch in TensorFlow for satellite land cover segmentation (Mean IoU: 0.674 across 7 classes) → presented at ICRTAI 2025 international conference
— Built multi-agent AI system using LangChain + LangGraph with 5 specialized agents: Mood Detection, FAISS-based Memory (RAG), Content Generation, Surprise Planning, Safety Check
— Deployed 4 live AI web apps + 2 production FastAPI endpoints + Android app (React Native/Expo) on Hugging Face Spaces
— Implemented RNN, GRU, LSTM, and BRNN architectures from scratch in PyTorch
— Built MLOps pipeline: MLflow experiment tracking, Optuna hyperparameter search, model registry
WHAT I CAN DO FOR YOU
1.Fine-tune LLMs on your domain-specific data
2. Build RAG pipelines for your documents or knowledge base
3.Train computer vision models (classification, segmentation, detection)
4. Build and deploy ML APIs with FastAPI on Hugging Face or cloud
5. MLOps: experiment tracking, reproducible pipelines, model registry
6. Multi-agent AI workflows with LangChain and LangGraph
TECH STACK
Python | TensorFlow | PyTorch | Hugging Face | FAISS | FastAPI | Streamlit | LangChain | LangGraph | MLflow | GGUF / llama.cpp | React Native
Steps for completing your project
After purchasing the project, send requirements so Yamraj can start the project.
Delivery time starts when Yamraj receives requirements from you.
Yamraj works on your project following the steps below.
Revisions may occur after the delivery date.
Review requirements and plan
I review your documents, example questions, and requirements. I confirm the best chunking strategy, embedding model, and LLM for your use case within 24 hours of purchase.
Build document pipeline
I process your documents — cleaning, chunking, and adding metadata. I generate vector embeddings and store them in a FAISS index optimized for fast semantic search.