You will get I will build a Retrieval-Augmented Generation (RAG) AI Chatbot
Project details
I specialize in building intelligent, retrieval-augmented generation (RAG) chatbots that don’t just answer questions—they understand your documents, retrieve relevant information instantly, and provide accurate, context-aware responses.
AI Algorithms
Large Language Model, Regression Analysis, Transformer ModelAI Applications
AI Chatbot, AI Text-to-Speech, Conversational AI, Image Recognition, Natural Language UnderstandingAI Development Language
PythonAI Tools
GitHub Copilot, Hugging Face, PyTorch, TensorFlowAI Models
LLaMAWhat's included
| Service Tiers |
Starter
$80
|
Standard
$100
|
Advanced
$150
|
|---|---|---|---|
| Delivery Time | 15 days | 30 days | 60 days |
Number of Revisions | 1 | 2 | 3 |
AI Model Integration | |||
Batch Normalization | - | ||
Database Integration | - | ||
Detailed Code Comments | - | ||
Image Upscaling | - | ||
MLOps | - | - | |
Model Deployment | - | - | |
Model Documentation | - | ||
Model Monitoring | - | ||
Model Testing & Optimization | - | ||
Model Tuning | - | ||
Natural Language Processing | |||
NLP Tokenization | |||
Pre-Training | |||
Prompt Engineering | |||
Setup File | |||
Source Code |
About Harshit
Data Scientist and AI/ML Engineer
New Delhi, India - 12:47 pm local time
What I offer
End-to-end ML projects: data collection, cleaning, feature engineering, modeling, evaluation, and deployment.
Document & OCR pipelines (Hindi + English) using OpenCV, Tesseract, and custom preprocessing.
Retrieval-Augmented Generation (RAG) & GenAI chatbots (context-aware, production-ready).
Speech-to-text / text-to-speech demos and integrations (Amazon Transcribe + alternatives; automated UI form autofill).
Search, indexing & embeddings: index design, mapping, and embedding pipelines to improve retrieval performance.
Microservices & cloud deployments: REST APIs, containerized services, and deployments on AWS / GCP / Azure.
Selected achievements
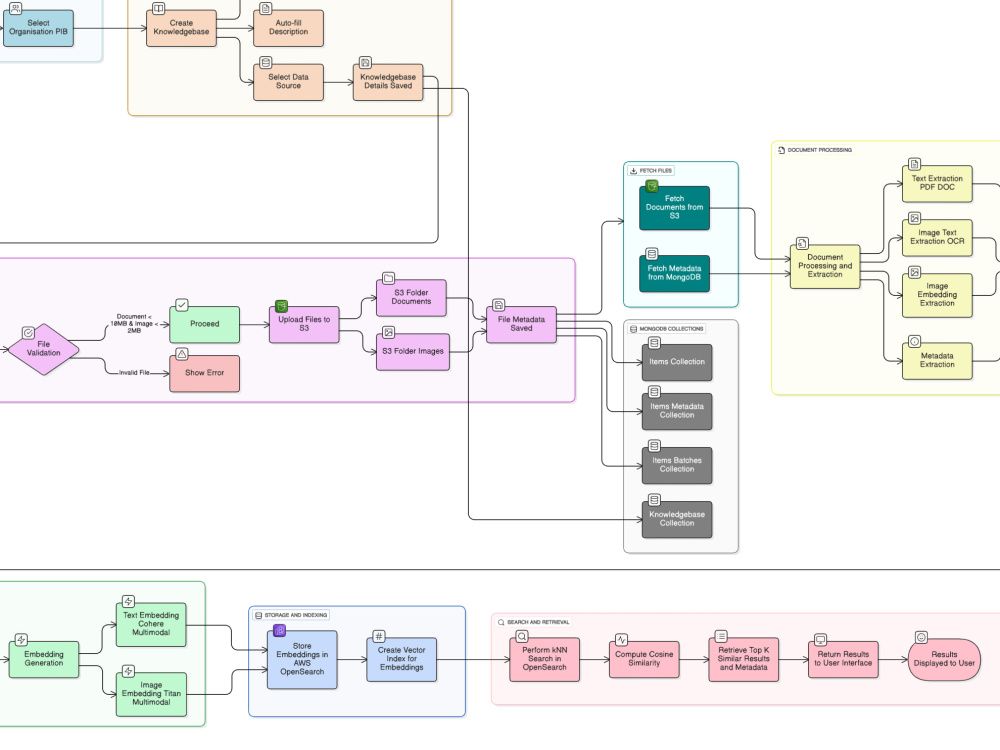
Built RAG chatbots for national-level projects (Press Information Bureau) for accurate, context-aware responses.
Improved recommendation accuracy by 25% and user engagement by 15% through GANs, clustering, and improved pipelines.
Automated PDF/image data ingestion and extraction workflows for bilingual documents (Hindi/English).
Tech stack
Python, Node.js/TypeScript, NumPy, Pandas, Scikit-learn, PyTorch/TensorFlow, OpenCV, Tesseract, SQL/MySQL, MongoDB, Power BI/Tableau, AWS/GCP/Azure, embeddings & LLMs (Claude Sonnet, OpenAI, Gemini, Cohere).
How I work
I focus on clear deliverables, reproducible code, and maintainable deployments. I’m comfortable collaborating with engineers and product teams and can provide prototypes, POCs, or production-ready systems depending on your needs.
If you have a problem that requires solid ML experience — especially with document processing, search, or conversational AI — send a message with a short description and I’ll propose a practical plan and next steps.
Steps for completing your project
After purchasing the project, send requirements so Harshit can start the project.
Delivery time starts when Harshit receives requirements from you.
Harshit works on your project following the steps below.
Revisions may occur after the delivery date.
Analyse and Take steps
I will analyse the project requirements. Create a timeline to take actions on the project.