You will get I will build an AI PDF & HTML to JSON extraction API
Project details
Extracting structured data from PDFs and HTML files is time-consuming and inconsistent — especially when documents use complex layouts like tables, forms, or multi-page reports.
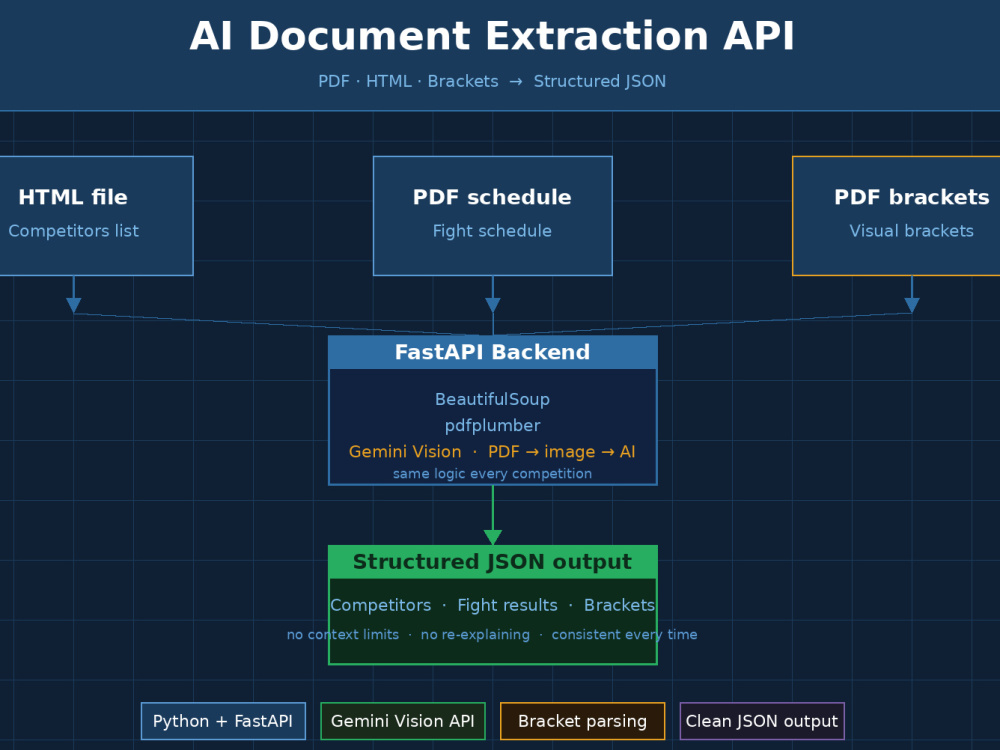
I use Gemini Vision to visually parse complex PDFs the same way every time — no manual copy-pasting, no missed fields. HTML files are extracted with BeautifulSoup, PDFs with pdfplumber, and complex visual layouts through AI image analysis. Every upload produces clean, consistent JSON.
Built with Python + FastAPI. You upload your files, you get back clean JSON — ready to use in any system.
I use Gemini Vision to visually parse complex PDFs the same way every time — no manual copy-pasting, no missed fields. HTML files are extracted with BeautifulSoup, PDFs with pdfplumber, and complex visual layouts through AI image analysis. Every upload produces clean, consistent JSON.
Built with Python + FastAPI. You upload your files, you get back clean JSON — ready to use in any system.
AI Algorithms
Large Language Model, Transformer ModelAI Applications
AI-Generated Code, Natural Language Understanding, Text RecognitionAI Development Language
PythonAI Models
ChatGPT, GPT-4What's included
| Service Tiers |
Starter
$50
|
Standard
$150
|
Advanced
$300
|
|---|---|---|---|
| Delivery Time | 3 days | 5 days | 10 days |
AI Model Integration | - | - | - |
Batch Normalization | - | - | - |
Database Integration | - | - | - |
Detailed Code Comments | - | - | - |
Image Upscaling | - | - | - |
MLOps | - | - | - |
Model Deployment | - | - | - |
Model Documentation | - | - | - |
Model Monitoring | - | - | - |
Model Testing & Optimization | - | - | - |
Model Tuning | - | - | - |
Natural Language Processing | |||
NLP Tokenization | - | - | - |
Pre-Training | - | - | - |
Prompt Engineering | |||
Setup File | |||
Source Code |
Optional add-ons
You can add these on the next page.
Add deployment to Railway/cloud
(+ 2 Days)
+$50
Add web upload UI
(+ 3 Days)
+$75
Priority support 7 days
+$30Frequently asked questions
About Kwstas
AI Application Engineer FastAPI + RAG +Document Extraction Specialist
Chios, Greece - 11:43 am local time
I recently built two production-grade AI projects: a multi-restaurant AI chatbot with LangGraph agents, parallel vector search, JWT authentication, and streaming responses (FastAPI, ChromaDB, Google Gemini, Next.js), and a Greek regional economic research assistant with custom scoring formulas and multi-tool LangGraph agent.
What I can build for you:
AI chatbots and RAG systems that answer questions from your documents or data
FastAPI backends with AI agent integration (OpenAI, Gemini, Claude)
LangGraph multi-step agents with memory and streaming
Data extraction pipelines from PDF, HTML, and structured data
Steps for completing your project
After purchasing the project, send requirements so Kwstas can start the project.
Delivery time starts when Kwstas receives requirements from you.
Kwstas works on your project following the steps below.
Revisions may occur after the delivery date.
Discovery
Review your files and define the JSON schema
Development
Build FastAPI extraction endpoints with Gemini AI