You will get I will train, evaluate, and deploy a custom ML model for your use case
Project details
I build end-to-end machine learning pipelines — from raw data to a trained, evaluated, and deployed model your team can actually use.
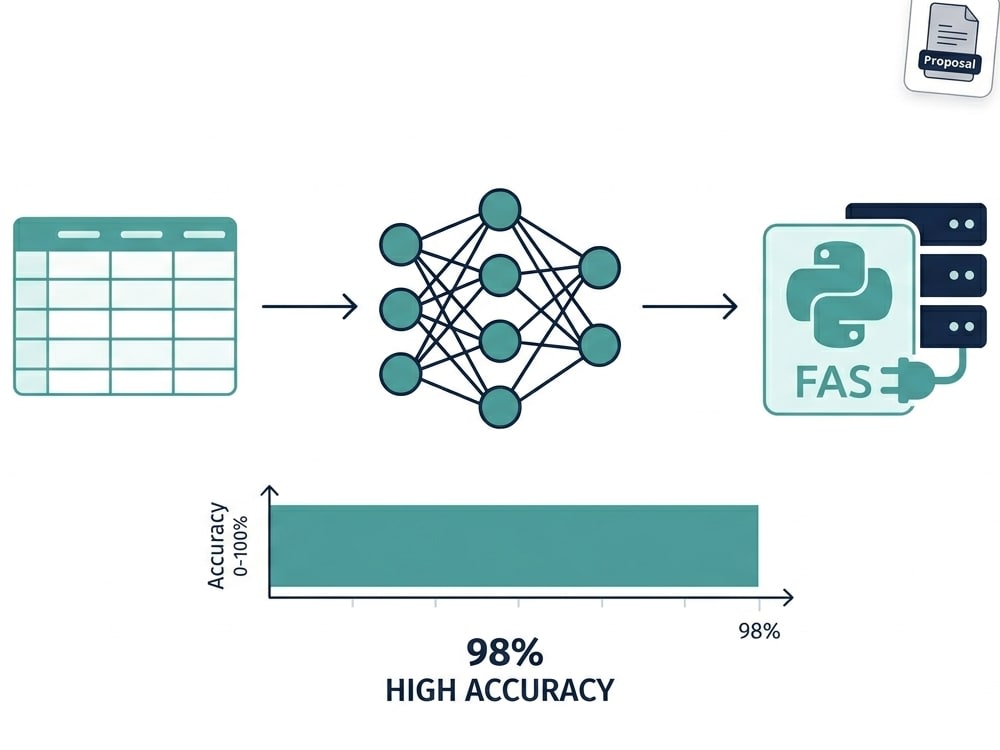
This covers the full ML lifecycle: data cleaning and EDA, feature engineering, model selection and training, hyperparameter tuning, performance evaluation, and production deployment via a FastAPI REST endpoint wrapped in Docker.
What I work with:
→ Classification, regression, clustering, and NLP tasks
→ Scikit-learn, PyTorch, TensorFlow, and Hugging Face
→ Tabular data (CSV/Excel), text, and structured datasets
→ FastAPI model serving with Swagger documentation
→ Docker containerisation and AWS EC2 deployment
Every project includes a full evaluation report (accuracy, F1, confusion matrix, feature importance) so you understand exactly how the model performs — not just a number.
You receive full source code, model weights, and a README covering how to retrain with new data. No lock-in, no black box.
Message me with your dataset and use case before ordering — I want to confirm this is the right fit.
This covers the full ML lifecycle: data cleaning and EDA, feature engineering, model selection and training, hyperparameter tuning, performance evaluation, and production deployment via a FastAPI REST endpoint wrapped in Docker.
What I work with:
→ Classification, regression, clustering, and NLP tasks
→ Scikit-learn, PyTorch, TensorFlow, and Hugging Face
→ Tabular data (CSV/Excel), text, and structured datasets
→ FastAPI model serving with Swagger documentation
→ Docker containerisation and AWS EC2 deployment
Every project includes a full evaluation report (accuracy, F1, confusion matrix, feature importance) so you understand exactly how the model performs — not just a number.
You receive full source code, model weights, and a README covering how to retrain with new data. No lock-in, no black box.
Message me with your dataset and use case before ordering — I want to confirm this is the right fit.
Machine Learning Tools
Deeplearning4j, GitHub Copilot, Google Sheets, Keras, MATLAB, Microsoft Excel, MLflow, NLTK, NumPy, Open Neural Network Exchange, OpenCV, pandas, Python, Python Scikit-Learn, PyTorch, scikit-learn, SciPy, SQL, TensorFlow, Word2vec, XGBoostWhat's included
| Service Tiers |
Starter
$100
|
Standard
$200
|
Advanced
$400
|
|---|---|---|---|
| Delivery Time | 5 days | 10 days | 21 days |
Number of Revisions | 1 | 5 | Unlimited |
Number of Model Variations | 5 | 7 | 10 |
Number of Graphs/Charts | 3 | 5 | 10 |
Model Validation/Testing | |||
Model Documentation | |||
Data Source Connectivity | - | ||
Source Code | - | - |
About Ahamed
AI/ML Engineer | RAG Systems | LLM Applications | Python
Kalmunai, Sri Lanka - 5:56 pm local time
RAG-powered research assistants to LLM pipelines with semantic
search and memory.
My recent project, Arxia, is a full-stack agentic RAG chatbot
built with Google Gemini 1.5 Flash, FAISS vector search, BM25
hybrid retrieval, and LangChain — deployed on AWS EC2 with a
React/Vite frontend on Vercel. It handles intent classification,
multi-layer memory (SQLite + conversation buffer), and searches
both a curated AI/ML knowledge base and live ArXiv papers.
What I can build for you:
→ RAG chatbots over your documents or knowledge base
→ LLM-powered automation pipelines
→ Semantic search systems
→ AI assistants with memory and context management
→ Python backends with FastAPI + vector databases (FAISS, Chroma)
I have hands-on production experience. I communicate
clearly, deliver on time, and document my work properly.
Let's talk about your project.
Steps for completing your project
After purchasing the project, send requirements so Ahamed can start the project.
Delivery time starts when Ahamed receives requirements from you.
Ahamed works on your project following the steps below.
Revisions may occur after the delivery date.
Data review & scoping
I review your dataset, define the problem type (classification, regression, NLP etc.), and confirm the approach before writing any code.
Data preprocessing & EDA
Clean, transform, and explore your data. You receive an EDA report with key insights and a preprocessing pipeline.