You will get Large-Scale Semantic FAISS Index for Your RAG Pipeline


Project details
Choose this if you need enterprise-scale / high-stakes semantic indexing with verified, reproducible, audit-ready outputs (correctness over speed).
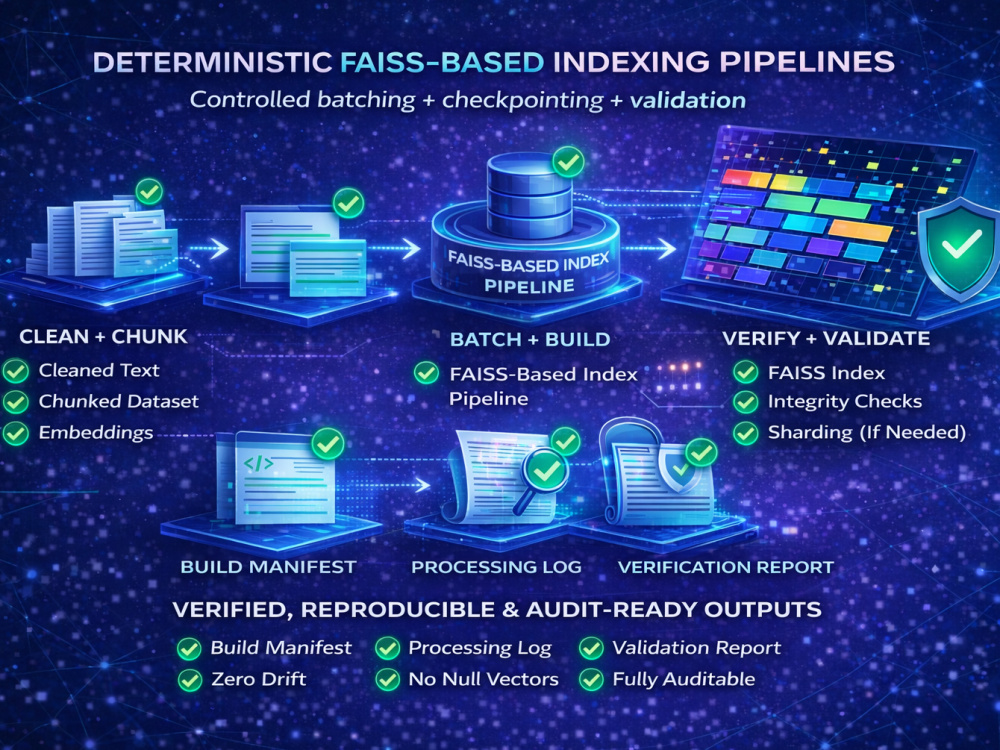
I build deterministic FAISS-based indexing pipelines with controlled batching + checkpointing + integrity checks + post-build validation to prevent partial indexes, misalignment, and drift.
Deliverables
• Cleaned + normalized text
• Chunked dataset
• Embeddings
• FAISS index (sharded if needed)
Validation artifacts + documentation
• Validation Pack (Included)
• 1:1:1 alignment (chunks ↔ metadata ↔ vectors)
• Zero null/corrupt vectors
• Index integrity test (loads + searches)
• Build manifest (model, dims, normalization, policy, counts, hashes)
• Processing log (audit trail / reproducibility)
Definition of Done:
Index loads + searches. 1:1:1 alignment verified (chunks = metadata = vectors). Zero null/corrupt vectors. Build manifest delivered (model, dims, counts, hashes). Processing log for reproducibility. Sharded indexes load independently if used.
If you only need a fast RAG-ready index without audit-grade validation, use my Production-Ready FAISS Index service instead. See Portfolio for full example outputs.
I build deterministic FAISS-based indexing pipelines with controlled batching + checkpointing + integrity checks + post-build validation to prevent partial indexes, misalignment, and drift.
Deliverables
• Cleaned + normalized text
• Chunked dataset
• Embeddings
• FAISS index (sharded if needed)
Validation artifacts + documentation
• Validation Pack (Included)
• 1:1:1 alignment (chunks ↔ metadata ↔ vectors)
• Zero null/corrupt vectors
• Index integrity test (loads + searches)
• Build manifest (model, dims, normalization, policy, counts, hashes)
• Processing log (audit trail / reproducibility)
Definition of Done:
Index loads + searches. 1:1:1 alignment verified (chunks = metadata = vectors). Zero null/corrupt vectors. Build manifest delivered (model, dims, counts, hashes). Processing log for reproducibility. Sharded indexes load independently if used.
If you only need a fast RAG-ready index without audit-grade validation, use my Production-Ready FAISS Index service instead. See Portfolio for full example outputs.
Machine Learning Tools
BERT, NLTK, NumPy, NVIDIA AI Platform, pandas, Python, PyTorch, Tesseract OCRWhat's included
| Service Tiers |
Starter
$550
|
Standard
$750
|
Advanced
$1,200
|
|---|---|---|---|
| Delivery Time | 9 days | 11 days | 13 days |
Number of Revisions | 1 | 1 | 1 |
Model Validation/Testing | |||
Model Documentation | |||
Data Source Connectivity | - | - | - |
Source Code |
Optional add-ons
You can add these on the next page.
Fast Delivery
+$30
Additional Revision
+$25
Index Report
+$50
Integration Help
+$75Frequently asked questions
About John
Semantic Indexing Engineer | RAG Data Pipelines | FAISS + e5-large-v2
Poughkeepsie, United States - 1:41 pm local time
I transform raw text into structured vector datasets using semantic chunking, dense embeddings, FAISS indexing, and metadata alignment — with validation so retrieval stays reliable over time. Clients use my indexes to power document Q&A, compliance search, knowledge base retrieval, and research discovery — so teams stop searching and start finding answers.
✅ What I Deliver
- RAG readiness audits + deployment prep for production launch
- Production-ready semantic indexing (FAISS + embeddings)
- Large-scale indexing with validation thresholds
- Framework-ready outputs (LangChain, LlamaIndex, Haystack compatible)
📊 Proof
- Indexed and validated 100+ datasets across legal, regulatory, scientific, and general knowledge domains
- Applied methodology across multiple research organizations
- Delivered auditable handoff packages (corpora, FAISS indexes, metadata, summaries)
🔍 How Reliability Is Verified
- Index loads successfully
- Vector count matches chunk count
- Vector–chunk alignment + dimensional integrity checks
🧰 Core Stack
- FAISS • e5-large-v2 • Python • semantic chunking • embeddings • retrieval validation
- Compatible with: LangChain • LlamaIndex • Haystack • pgvector • Pinecone
If your team needs results that don't break in production, I'll deliver the indexing stack you wish came prebuilt.
Steps for completing your project
After purchasing the project, send requirements so John can start the project.
Delivery time starts when John receives requirements from you.
John works on your project following the steps below.
Revisions may occur after the delivery date.
Scale & constraint validation
Confirm dataset size, document type, and operational constraints.
Pipeline execution
Run optimized semantic indexing pipelines for large datasets.