You will get [$5 Intro Consultation] LLM Cost Reduction & Architecture Strategy
Project details
I’m offering a limited $5 consultation to connect with new Upwork clients and build new partnerships.
If you're using OpenAI, Anthropic, or a custom LLM stack, we’ll review your current setup and identify cost and architectural improvements.
In 30 minutes, we'll:
• Review usage patterns and token spend
• Analyze prompts and model selection
• Identify cost reduction opportunities
• Provide architecture feedback
• Outline clear next steps
You’ll receive a brief written follow-up summary with prioritized recommendations.
Best suited for founders, CTOs, and product teams already using or preparing to launch LLM-powered products.
If you're using OpenAI, Anthropic, or a custom LLM stack, we’ll review your current setup and identify cost and architectural improvements.
In 30 minutes, we'll:
• Review usage patterns and token spend
• Analyze prompts and model selection
• Identify cost reduction opportunities
• Provide architecture feedback
• Outline clear next steps
You’ll receive a brief written follow-up summary with prioritized recommendations.
Best suited for founders, CTOs, and product teams already using or preparing to launch LLM-powered products.
AI Algorithms
Large Language ModelAI Applications
AI Chatbot, AI Content Creation, AI Text-to-Image, AI Text-to-Speech, AI-Generated Code, Conversational AI, Natural Language Generation, Natural Language UnderstandingAI Development Language
PythonAI Tools
Adobe Firefly, Azure OpenAI, GitHub Copilot, PyTorch, Replit, TensorFlowAI Models
ChatGPT, GPT-3, GPT-4, LLaMA, OpenAI CodexWhat's included $5
These options are included with the project scope.
$5
- Delivery Time 1 day
- Number of Revisions 0
- AI Model Integration
- Model Documentation
- Model Testing & Optimization
- Natural Language Processing
- Prompt Engineering
Frequently asked questions
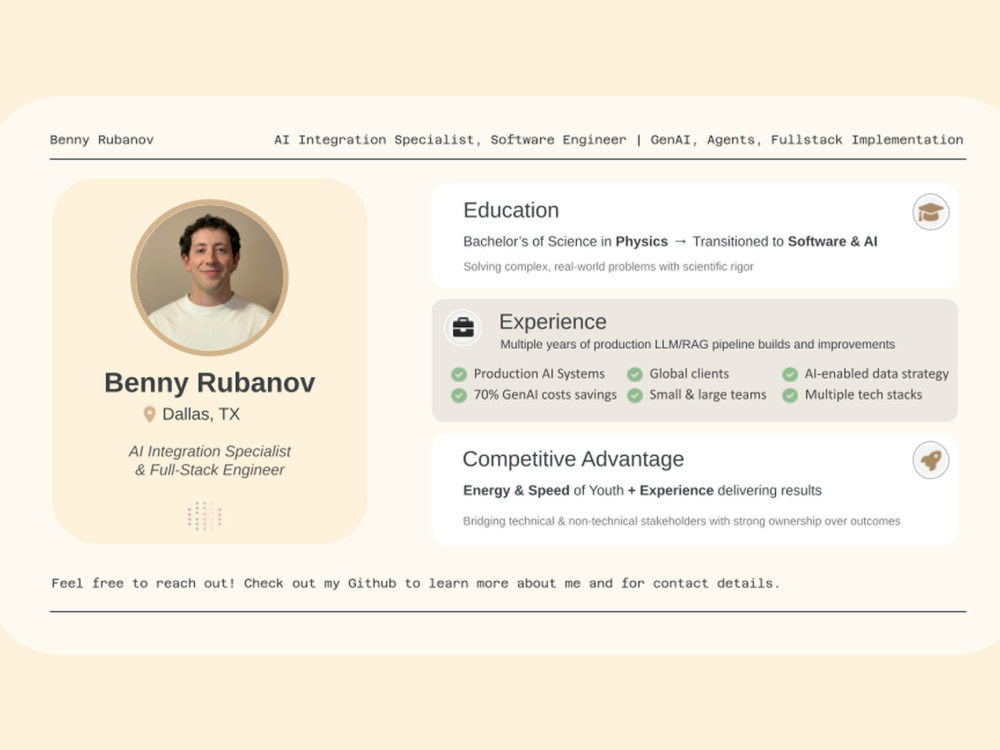
About Benny
AI Integration Specialist - GenAI, Agents, Fullstack Implementation
Dallas, United States - 5:25 pm local time
💡AI-powered web applications, automations, RAG/LLM pipelines, and more
💻 GenAI, LLMs, RAG, Typescript, React/Next.js, Python, SQL, Postgres, HTML/CSS, Javascript, C, Vue, Nuxt.js, Docker, Enterprise Cloud (AWS, GCP, Azure), Vercel, Firebase, Supabase
✅ What I Offer
• LLM & RAG Systems: Hallucination reduction, prompt engineering, retrieval tuning, automated testing & grading
• Production AI Systems: Stable, maintainable GenAI pipelines with guardrails, monitoring, and clear ownership
• AI Cost Optimization: Token accounting, prompt compression, routing, caching, and spend control
• Unstructured Data Ingestion: Turning PDFs, Markdown, scraped web data into clean, queryable databases
• AI System Audits & Fix Plans: Diagnose brittle systems and deliver concrete remediation roadmaps
🎯 Recent Achievements
• Built and maintained LLM/RAG pipelines with adaptive prompting, chaining logic, and live scraped data, generating 30,000+ product descriptions for a large e-commerce reseller
• Primary technical advisor on new AI-augmented database architecture and maintenance strategy for new Print-On-Demand SaaS initiative
• Reduced GenAI token spend by ~70% on a large-scale content generation pipeline without degrading quality
• Developed a modular RAG-based AI platform cutting proposal draft time from 10+ hours to under 30 minutes
• Led production feature development for an Atlassian Marketplace app used by 200+ companies
🔧 Technical Stack
AI / GenAI: LLM APIs, RAG architectures, prompt engineering, evaluation harnesses, automated grading
Languages: Python, TypeScript, JavaScript, SQL
Frameworks: FastAPI, React/Next.js, Vue/Nuxt, Node.js
Data: SQL & NoSQL databases, vector databases, web scraping pipelines
Cloud: AWS, GCP
Practices: Testing, logging, cost monitoring, regression prevention, production hardening
🌟 What Sets Me Apart
I’ve spent several years owning real production systems, not demos.
I combine the energy and speed of a younger engineer with hands-on experience maintaining AI pipelines as models, data, and requirements change.
I don’t just “build AI features.” I focus on accuracy, cost, and long-term maintainability, and I take responsibility for systems once they’re live.
📋 Services I Provide
• LLM & RAG accuracy audits and hallucination control
• Prompt testing at scale with grading and regression checks
• Token usage analysis and LLM cost reduction
• AI content generation pipelines with guardrails
• Unstructured document ingestion and database design
• AI system stabilization, refactors, and production hardening
• Ongoing ownership and maintenance of AI subsystems
🔑 Keywords
Artificial Intelligence, Generative AI, GenAI, LLM, RAG, Retrieval Augmented Generation, Prompt Engineering, Hallucination Reduction, AI Testing, Automated Evaluation, Token Optimization, AI Cost Reduction, Vector Databases, NLP, Python, FastAPI, TypeScript, AWS, GCP, Data Ingestion, Postgres, ETL, AI Pipelines, Production AI
Steps for completing your project
After purchasing the project, send requirements so Benny can start the project.
Delivery time starts when Benny receives requirements from you.
Benny works on your project following the steps below.
Revisions may occur after the delivery date.
Pre-call review (optional)
I review your usage snapshot and examples to spot obvious cost drivers.
Live consultation
We walk through token usage patterns, architectural choices, and strategies for cost reductions together.