You will get LLM Token + Spend Optimization (Cost Down Without Quality Loss)

Project details
Most teams overspend because they don’t model token usage and they default to expensive patterns (too much context, no routing, no caching). I’ve reduced token spend by ~70% in a large-scale GenAI pipeline without sacrificing quality, and this project applies the same playbook to your system.
AI Algorithms
Large Language Model, Multimodal Large Language Model, Regression Analysis, Transformer ModelAI Applications
AI Chatbot, AI Content Creation, AI Text-to-Image, AI Text-to-Speech, AI-Generated Code, AI-Generated Video, Conversational AI, Natural Language Generation, Natural Language Understanding, Text RecognitionAI Development Language
PythonAI Tools
Azure OpenAI, GitHub Copilot, Hugging Face, PyTorch, Replit, TensorFlowAI Models
BERT, ChatGPT, GPT-3, GPT-4, LLaMA, Midjourney AI, OpenAI Codex, Stable DiffusionWhat's included
| Service Tiers |
Starter
$900
|
Standard
$1,800
|
Advanced
$3,700
|
|---|---|---|---|
| Delivery Time | 3 days | 5 days | 10 days |
Number of Revisions | 1 | 2 | 2 |
AI Model Integration | - | - | |
Batch Normalization | - | - | - |
Database Integration | - | - | |
Detailed Code Comments | - | - | |
Image Upscaling | - | - | - |
MLOps | - | - | |
Model Deployment | - | - | - |
Model Documentation | |||
Model Monitoring | - | - | |
Model Testing & Optimization | - | ||
Model Tuning | - | - | |
Natural Language Processing | |||
NLP Tokenization | |||
Pre-Training | - | - | - |
Prompt Engineering | |||
Setup File | - | - | - |
Source Code | - | - |
Optional add-ons
You can add these on the next page.
Fast Delivery
+$450 - $1,900Frequently asked questions
About Benny
AI Integration Specialist - GenAI, Agents, Fullstack Implementation
Dallas, United States - 5:33 am local time
💡AI-powered web applications, automations, RAG/LLM pipelines, and more
💻 GenAI, LLMs, RAG, Typescript, React/Next.js, Python, SQL, Postgres, HTML/CSS, Javascript, C, Vue, Nuxt.js, Docker, Enterprise Cloud (AWS, GCP, Azure), Vercel, Firebase, Supabase
✅ What I Offer
• LLM & RAG Systems: Hallucination reduction, prompt engineering, retrieval tuning, automated testing & grading
• Production AI Systems: Stable, maintainable GenAI pipelines with guardrails, monitoring, and clear ownership
• AI Cost Optimization: Token accounting, prompt compression, routing, caching, and spend control
• Unstructured Data Ingestion: Turning PDFs, Markdown, scraped web data into clean, queryable databases
• AI System Audits & Fix Plans: Diagnose brittle systems and deliver concrete remediation roadmaps
🎯 Recent Achievements
• Built and maintained LLM/RAG pipelines with adaptive prompting, chaining logic, and live scraped data, generating 30,000+ product descriptions for a large e-commerce reseller
• Primary technical advisor on new AI-augmented database architecture and maintenance strategy for new Print-On-Demand SaaS initiative
• Reduced GenAI token spend by ~70% on a large-scale content generation pipeline without degrading quality
• Developed a modular RAG-based AI platform cutting proposal draft time from 10+ hours to under 30 minutes
• Led production feature development for an Atlassian Marketplace app used by 200+ companies
🔧 Technical Stack
AI / GenAI: LLM APIs, RAG architectures, prompt engineering, evaluation harnesses, automated grading
Languages: Python, TypeScript, JavaScript, SQL
Frameworks: FastAPI, React/Next.js, Vue/Nuxt, Node.js
Data: SQL & NoSQL databases, vector databases, web scraping pipelines
Cloud: AWS, GCP
Practices: Testing, logging, cost monitoring, regression prevention, production hardening
🌟 What Sets Me Apart
I’ve spent several years owning real production systems, not demos.
I combine the energy and speed of a younger engineer with hands-on experience maintaining AI pipelines as models, data, and requirements change.
I don’t just “build AI features.” I focus on accuracy, cost, and long-term maintainability, and I take responsibility for systems once they’re live.
📋 Services I Provide
• LLM & RAG accuracy audits and hallucination control
• Prompt testing at scale with grading and regression checks
• Token usage analysis and LLM cost reduction
• AI content generation pipelines with guardrails
• Unstructured document ingestion and database design
• AI system stabilization, refactors, and production hardening
• Ongoing ownership and maintenance of AI subsystems
🔑 Keywords
Artificial Intelligence, Generative AI, GenAI, LLM, RAG, Retrieval Augmented Generation, Prompt Engineering, Hallucination Reduction, AI Testing, Automated Evaluation, Token Optimization, AI Cost Reduction, Vector Databases, NLP, Python, FastAPI, TypeScript, AWS, GCP, Data Ingestion, Postgres, ETL, AI Pipelines, Production AI
Steps for completing your project
After purchasing the project, send requirements so Benny can start the project.
Delivery time starts when Benny receives requirements from you.
Benny works on your project following the steps below.
Revisions may occur after the delivery date.
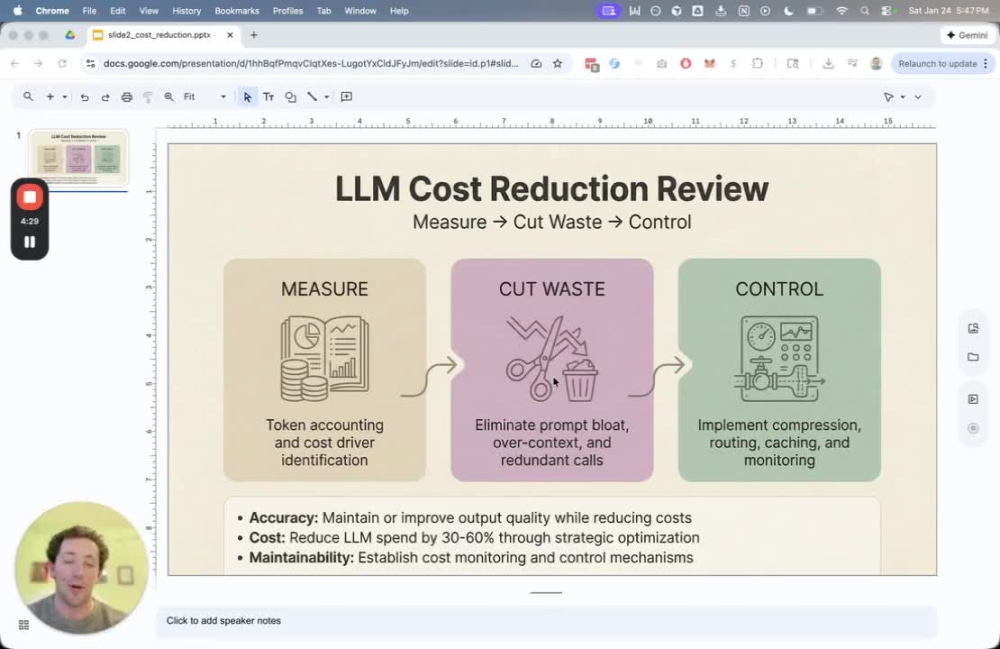
Token accounting — where spend comes from (input/output/context patterns).
Waste identification — prompt bloat, over-context, redundancy, model misuse