You will get Local AI Legal Discovery: Secure Air-Gapped Data Engine
Project details
Sovereign Legal Engine | Air-Gapped AI Discovery & Structured Data
Stop sending sensitive legal filings to 3rd-party APIs. The Sovereign Legal Engine is a precision-engineered, local-first audit system designed for Zero-Trust environments. Built on an Ollama backbone, it transforms massive, unstructured judicial opinions into high-fidelity discovery ledgers without data ever leaving your hardware.
Key Engineering Features:
Dual-Agent Orchestration: Parallel processing using The Narrator (mission-aware reasoning) and The Auditor (constrained JSON agent) to ensure 100% schema integrity.
Defensive Fallback Chain: Integrated local OCR and structural parsing that pivots automatically if text density is garbled.
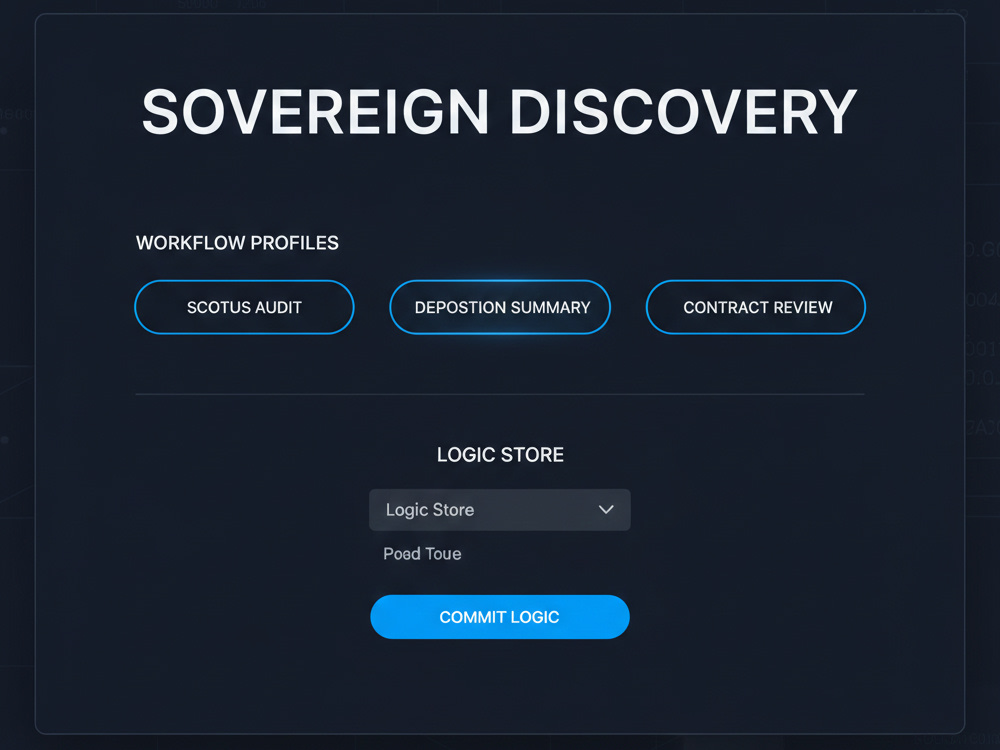
End-User Programmability: Includes a "Logic Store" where you define custom legal taxonomies and prompt outputs without touching the backend.
Zero-Chatter Sanitization: Custom layer that strips conversational AI "fluff," delivering only raw findings, authority types, and risk levels.
Stop sending sensitive legal filings to 3rd-party APIs. The Sovereign Legal Engine is a precision-engineered, local-first audit system designed for Zero-Trust environments. Built on an Ollama backbone, it transforms massive, unstructured judicial opinions into high-fidelity discovery ledgers without data ever leaving your hardware.
Key Engineering Features:
Dual-Agent Orchestration: Parallel processing using The Narrator (mission-aware reasoning) and The Auditor (constrained JSON agent) to ensure 100% schema integrity.
Defensive Fallback Chain: Integrated local OCR and structural parsing that pivots automatically if text density is garbled.
End-User Programmability: Includes a "Logic Store" where you define custom legal taxonomies and prompt outputs without touching the backend.
Zero-Chatter Sanitization: Custom layer that strips conversational AI "fluff," delivering only raw findings, authority types, and risk levels.
AI Algorithms
Large Language Model, Long Short-Term Memory Network, Multimodal Large Language ModelAI Applications
AI-Enhanced Classification, Natural Language Generation, Synthetic Data Generation, Text RecognitionAI Development Language
PythonAI Tools
PyTorch, TensorFlowAI Models
AlphaCode, ChatGPT, LLaMAWhat's included
| Service Tiers |
Starter
$250
|
Standard
$500
|
Advanced
$1,500
|
|---|---|---|---|
| Delivery Time | 1 day | 3 days | 10 days |
Number of Revisions | 0 | 2 | 5 |
AI Model Integration | |||
Batch Normalization | - | - | - |
Database Integration | - | ||
Detailed Code Comments | - | ||
Image Upscaling | - | - | - |
MLOps | - | - | - |
Model Deployment | - | - | |
Model Documentation | |||
Model Monitoring | - | - | - |
Model Testing & Optimization | - | ||
Model Tuning | - | - | |
Natural Language Processing | |||
NLP Tokenization | |||
Pre-Training | - | - | - |
Prompt Engineering | - | ||
Setup File | |||
Source Code |
Optional add-ons
You can add these on the next page.
Additional Revision
+$150
1 review
(0)
(1)
(0)
(0)
(0)
This project doesn't have any reviews.
PV
Peter V.
May 22, 2025
Prototype Developer: AI Character Illustration from Photo (LoRA + ControlNet + SD)
About Todd
AI/LLM Systems Engineer, Local Inference, RAG & Multi Agent Pipelines
Wayne County, United States - 7:33 am local time
My work is production-grade local LLM deployment: multi-agent pipelines, FAISS vector knowledge bases, document ingestion, and domain-specific AI tools for legal, security, and engineering use cases. If you need a sovereign AI system that handles sensitive data without sending it to OpenAI, this is what I do.
What I build:
Multi-Agent RAG Systems — Triple-LLM architectures with distinct Initializer, Orchestrator, and Reasoner agents. Each model is scoped to its role. Built on Ollama with locally fine-tuned models. Your data never leaves your machine.
FAISS Vector Pipelines — Full Phase 1→2 ingestion: extract, chunk, summarize, embed, index. Versioned FAISS indices with outlier detection, metadata preservation, and cross-KB semantic retrieval. Embedding engine locked to all-mpnet-base-v2 at 768 dims.
Document Processing — PDF (pdfplumber + PyPDF2), DOCX, OCR via Tesseract, and web crawl ingestion. Structured JSONL output with token counts, categories, timestamps, and summaries — ready for Phase 2 vectorization.
Domain AI Tools — Built a dual-agent legal discovery engine with chunked PDF processing, OCR, and structured audit tables. Built a sovereign coding assistant with RAG-indexed codebase memory. Built cybersecurity analysis tools aligned with IBM and Cisco SOC frameworks.
Backend APIs — Flask and FastAPI services for every component: vectorization endpoints, top-k semantic search, agent query routing. Async-ready, CORS-hardened, modular by design.
My background spans both sides of this stack: AI/ML engineering and cybersecurity. I hold certifications from IBM (Generative AI, Cybersecurity), Cisco (SOC Specialization, Threat Analysis), Stanford (Machine Learning — Andrew Ng), Google (IT Infrastructure, OS), and University of Michigan (Python 3 Specialization).
I don't build demos. I build systems that ship.
Steps for completing your project
After purchasing the project, send requirements so Todd can start the project.
Delivery time starts when Todd receives requirements from you.
Todd works on your project following the steps below.
Revisions may occur after the delivery date.
Environment & Dependency Sync
I verify your local hardware configuration and confirm that Ollama and Python 3.10+ are correctly installed. This ensures the engine has the necessary local resources to run inference without latency.