You will get NGS Data Analysis , RNA-Seq, DNA-Seq, Variant Calling, Annotation.

Project details
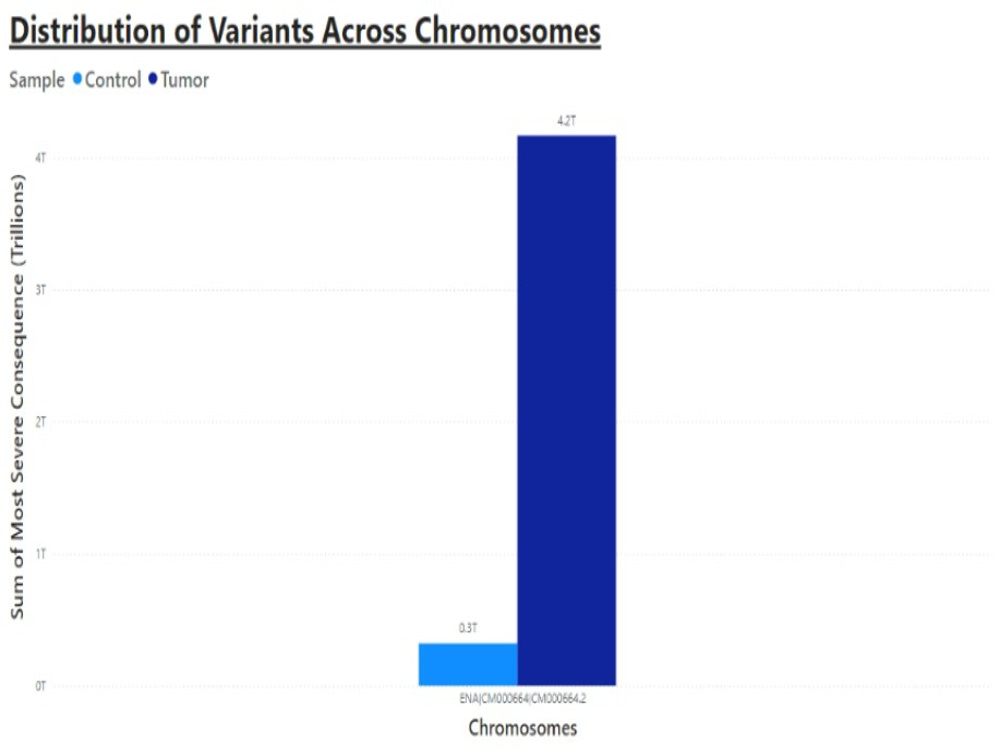
This project offers end-to-end Next-Generation Sequencing (NGS) data analysis for research, clinical, or academic use. I provide expert support in processing raw sequencing data (FASTQ, BAM, or VCF) to deliver high-quality, well-annotated, and publication-ready results. Services include variant calling, differential gene expression analysis, mutation impact prediction, and data visualization.
Whether you're working with RNA-Seq, DNA-Seq, or need proteogenomics integration, I use industry-standard tools and workflows to ensure accuracy, reproducibility, and clarity. The final deliverables include processed data, annotated results, visualizations, and a summary report tailored to your project needs.
This service is ideal for researchers, graduate students, biotech companies, or anyone requiring reliable, fast, and accurate bioinformatics analysis.
Whether you're working with RNA-Seq, DNA-Seq, or need proteogenomics integration, I use industry-standard tools and workflows to ensure accuracy, reproducibility, and clarity. The final deliverables include processed data, annotated results, visualizations, and a summary report tailored to your project needs.
This service is ideal for researchers, graduate students, biotech companies, or anyone requiring reliable, fast, and accurate bioinformatics analysis.
Data Tool
RWhat's included
| Service Tiers |
Starter
$15
|
Standard
$21
|
Advanced
$25
|
|---|---|---|---|
| Delivery Time | 1 day | 1 day | 2 days |
Number of Pages Mined/Scraped | 2 | 3 | 5 |
Number of Sources Mined/Scraped | 3 | 5 | 7 |
Number of Revisions | 2 | 4 | 6 |
Optional add-ons
You can add these on the next page.
Fast Delivery
+$5
Additional Revision
+$5Frequently asked questions
About Sethupathy
Bioinformatics Analyst
Coimbatore, India - 12:26 am local time
My expertise includes tools like FastQC, BWA, GATK, ANNOVAR, and programming in Python on Ubuntu/Linux environments. I’ve worked on real-world datasets such as glioblastoma multiforme (GBM), identifying key mutations (e.g., EGFR, TP53) and visualizing insights using Power BI.
Whether you're a startup, researcher, or biotech company, I can help you build scalable, efficient bioinformatics solutions tailored to your goals.
Steps for completing your project
After purchasing the project, send requirements so Sethupathy can start the project.
Delivery time starts when Sethupathy receives requirements from you.
Sethupathy works on your project following the steps below.
Revisions may occur after the delivery date.
Review and Validate Input Data
Verify the integrity and format of your uploaded files (FASTQ, BAM, VCF, metadata) Confirm reference genome and analysis goals
Preprocessing and Quality Control
Perform quality checks using tools like FastQC Conduct adapter trimming and filtering (Trimmomatic or similar) Align reads to the reference genome (using BWA, STAR, or HISAT2)