You will get NLP & Document Intelligence: Text Classification, Extraction & Automation

Project details
I build NLP solutions for real-world challenges - messy data, limited labels, complex requirements.
WHY I DELIVER:
End-to-End Data Capability
• Document parsing: PDFs, scans → structured data
• Pipeline: collection, cleaning, transformation
Weak Supervision Expertise
• SOTA on weakly-supervised tasks: 56% COCO segmentation
• High accuracy from 20-50 labeled examples
• Optimized for small datasets
Research-Grade Results
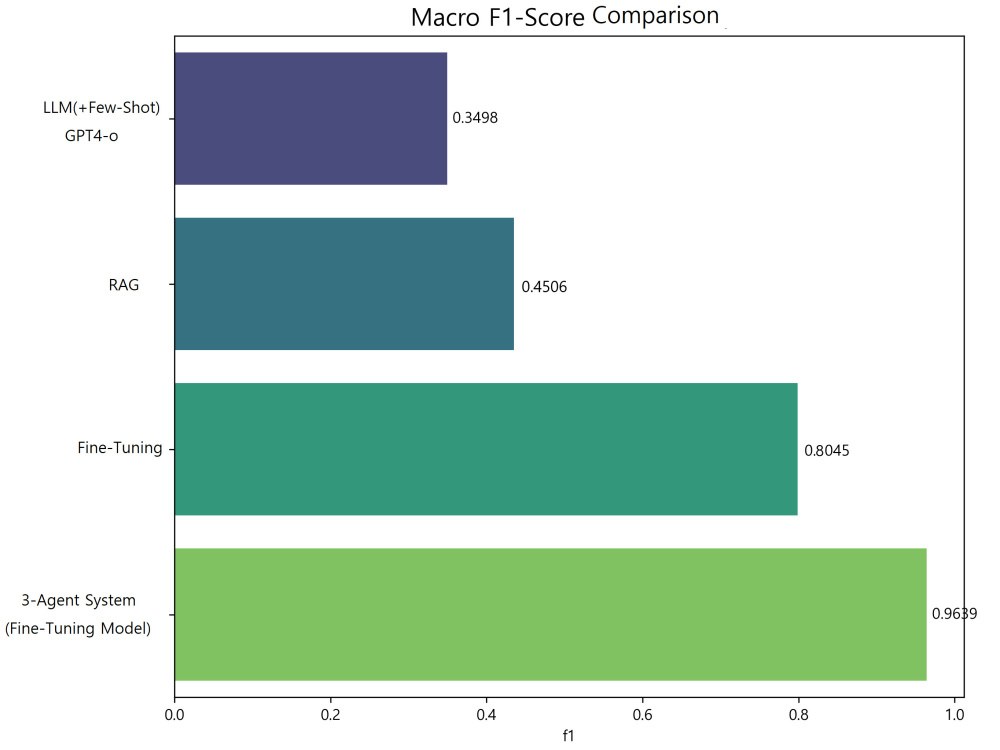
• Beat benchmarks: 56% COCO, 94.5% ISIC
• Government docs: 95%+ accuracy, <50 labels
• Production quality with research accuracy
Real Production:
• 270+ documents: 40h → 2h automation
• Multi-class classification, minimal training data
• Full pipeline: data → parsing → classification → API
What This Means:
• Messy/incomplete data? I handle it
•NLP + Data collection together? End-to-end solution
• Small dataset? Weak supervision strength
• High accuracy needed? Research-proven methods
I solve complete problems: data collection, limited labels (weak supervision), research accuracy, production deployment.
Not just models - working systems.
WHY I DELIVER:
End-to-End Data Capability
• Document parsing: PDFs, scans → structured data
• Pipeline: collection, cleaning, transformation
Weak Supervision Expertise
• SOTA on weakly-supervised tasks: 56% COCO segmentation
• High accuracy from 20-50 labeled examples
• Optimized for small datasets
Research-Grade Results
• Beat benchmarks: 56% COCO, 94.5% ISIC
• Government docs: 95%+ accuracy, <50 labels
• Production quality with research accuracy
Real Production:
• 270+ documents: 40h → 2h automation
• Multi-class classification, minimal training data
• Full pipeline: data → parsing → classification → API
What This Means:
• Messy/incomplete data? I handle it
•NLP + Data collection together? End-to-end solution
• Small dataset? Weak supervision strength
• High accuracy needed? Research-proven methods
I solve complete problems: data collection, limited labels (weak supervision), research accuracy, production deployment.
Not just models - working systems.
Machine Learning Tools
BERT, ChatGPT, Databricks Platform, deeplearn.js, GitHub Copilot, Google AutoML, Google Data Studio, GPT-3, MLflow, NumPy, OpenCV, pandas, Python, PyTorch, R, scikit-learn, SciPy, SQL, TensorFlow, Word2vec, XGBoostWhat's included
| Service Tiers |
Starter
$100
|
Standard
$450
|
Advanced
$800
|
|---|---|---|---|
| Delivery Time | 5 days | 10 days | 14 days |
Number of Revisions | 1 | 2 | 3 |
Number of Model Variations | 1 | 1 | 1 |
Number of Scenarios | 1 | 2 | 3 |
Number of Graphs/Charts | 2 | 3 | 4 |
Model Validation/Testing | |||
Model Documentation | |||
Data Source Connectivity | - | ||
Source Code | - | - |
Frequently asked questions
About Choi
AI Engineer: Vision, NLP, RL, Agent | SOTA Research meets Production
Seoul, South Korea - 12:00 am local time
CORE CAPABILITIES:
AI Agent Systems (LangGraph/LangChain)
- Multi-agent architectures with state management and tool orchestration
- Human-in-the-loop workflows for complex decision-making
- API integration and async processing for production deployment
- Real deployment: Travel booking system with 4 API integrations serving live customers
Computer Vision
- Weakly-supervised semantic segmentation (56% mIoU COCO, beat SOTA)
- Object detection and tracking for real-time applications
- Medical imaging classification (94.5% ISIC benchmark)
- Self-training, multi-signal fusion (CLIP/DINO), custom architectures
NLP & Document Intelligence
- Large-scale document classification and routing systems
- Weak supervision frameworks with minimal labeled data
- Information extraction and semantic matching
- Production system: Automated 270+ file processing (40 hours → 2 hours)
Predictive Modeling & RL
- Ensemble methods: XGBoost, NGBoost, LightGBM, CatBoost
- Uncertainty quantification for high-stakes decisions
- Reinforcement learning for optimization problems
- Real impact: 3x improvement in bid success rate (₩7.7T market)
Production Engineering
- Web automation with anti-bot evasion (Playwright, Selenium)
- Async architectures for long-running AI tasks (FastAPI, Node.js)
- Database design, API development, frontend integration (React)
- Deployment: Docker, AWS, GCP, monitoring and error handling
WHAT MAKES MY WORK DIFFERENT:
I don't just train models - I build complete systems where AI components work together to automate complex workflows. Whether it's combining computer vision with NLP for document understanding, or integrating predictive models into multi-agent systems, I focus on end-to-end solutions that deliver measurable business value.
DELIVERABLES:
✓ Production-ready code with proper error handling and logging
✓ Clear documentation and architecture decisions
✓ Model training pipelines with evaluation metrics
✓ Deployment guides and monitoring setup
✓ Real results, not benchmarks
TECHNICAL STACK:
AI/ML: PyTorch, TensorFlow, Transformers, LangChain, LangGraph
Models: XGBoost, LightGBM, CatBoost, NGBoost, RL frameworks
Backend: Python, FastAPI, Node.js, async processing
Frontend: React, JavaScript
Automation: Playwright, Selenium, API integration
DevOps: Docker, AWS, GCP, monitoring tools
Based in Seoul (UTC+9), flexible for US/EU hours.
GitHub: github.com/HarimxChoi
Available for: AI agent development, computer vision systems, NLP applications, predictive modeling, end-to-end ML pipelines, production automation
Let's discuss how AI can solve your specific business problem.
Steps for completing your project
After purchasing the project, send requirements so Choi can start the project.
Delivery time starts when Choi receives requirements from you.
Choi works on your project following the steps below.
Revisions may occur after the delivery date.
Dataset Review & Model Planning
Analyze your text data: quality, size, class distribution, edge cases. Design approach: model selection (BERT, RoBERTa, etc.), weak supervision if needed, handling class imbalance. Create technical plan and confirm before training.
Model Training & Optimization
Fine-tune pretrained models on your data. Apply data augmentation, handle class imbalance, optimize hyperparameters. For extraction: implement entity recognition and key-value parsing. Iterative training until performance targets met.