You will get OCR data amd text extraction from PDFs, scans, and images






Project details
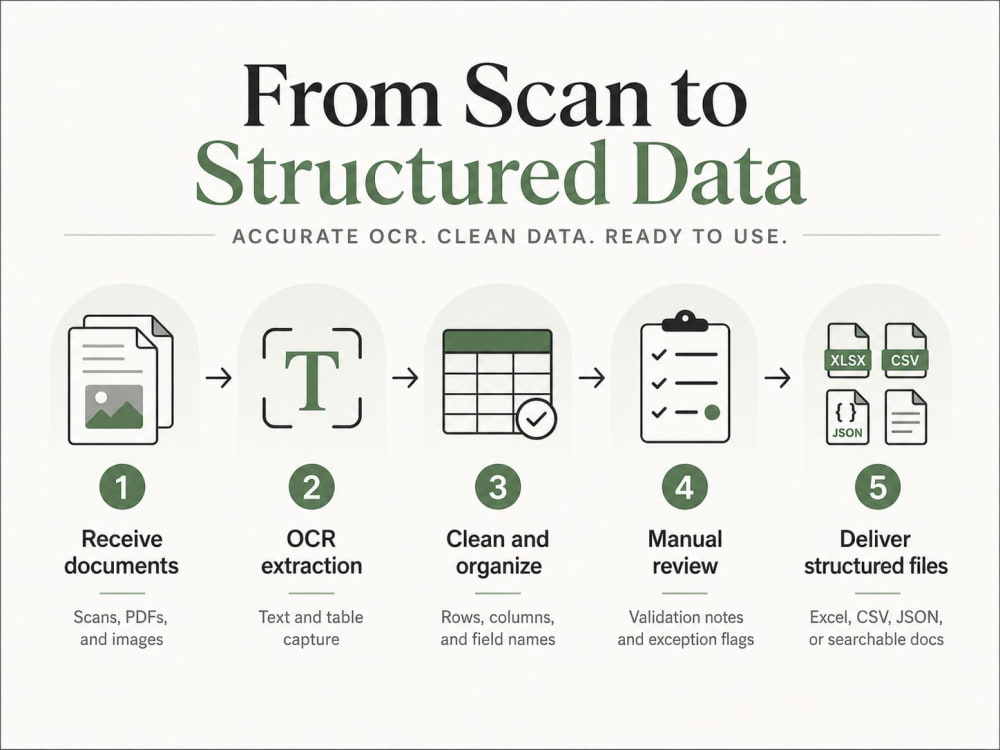
I will extract, clean, and organize text or structured data from scanned PDFs, image files, invoices, forms, tables, statements, reports, and document archives using OCR with human review where needed.
This project is for clients who need usable outputs, not just a raw OCR dump. I can deliver Excel, CSV, Google Sheets-ready files, Word, searchable PDF, JSON, or a reusable OCR/Python workflow depending on the package. I check sample pages first, define the fields to capture, flag low-confidence pages, clean obvious OCR errors, and format the output so it can be filtered, analyzed, imported, or reviewed.
Best fit: typed or printed documents, scanned reports, tables, invoices, forms, directories, statements, questionnaires, and mixed PDF/image files. Handwriting, damaged scans, very poor photos, or complex layouts may require a custom quote after reviewing samples.
This project is for clients who need usable outputs, not just a raw OCR dump. I can deliver Excel, CSV, Google Sheets-ready files, Word, searchable PDF, JSON, or a reusable OCR/Python workflow depending on the package. I check sample pages first, define the fields to capture, flag low-confidence pages, clean obvious OCR errors, and format the output so it can be filtered, analyzed, imported, or reviewed.
Best fit: typed or printed documents, scanned reports, tables, invoices, forms, directories, statements, questionnaires, and mixed PDF/image files. Handwriting, damaged scans, very poor photos, or complex layouts may require a custom quote after reviewing samples.
Data Tool
PythonWhat's included
| Service Tiers |
Starter
$15
|
Standard
$50
|
Advanced
$200
|
|---|---|---|---|
| Delivery Time | 3 days | 5 days | 10 days |
Number of Pages Mined/Scraped | 100 | 500 | 2000 |
Number of Sources Mined/Scraped | 1 | 3 | 10 |
Number of Revisions | 1 | 2 | 3 |
Frequently asked questions
About Michael Izuchukwu Ayibatonye
Report Design, Data Visualization & OCR Automation
Abuja, Nigeria - 12:13 am local time
My core work is editorial and information design: annual reports, impact reports, policy reports, financial reports, white papers, research papers, company profiles, case studies, brochures, pitch decks, and publication systems. I focus on structure, hierarchy, typography, chart cleanup, table design, and data visualization so the final document is easier to read, trust, and present.
I also support the technical side of information-heavy work: OCR, PDF data extraction, scanned-document processing, data cleaning, spreadsheet-ready outputs, and practical AI-assisted workflows for research, reporting, and document processing. That means I can help not only with how complex information looks, but also with how it is extracted, organized, validated, and prepared for use.
Useful project types include:
- Annual reports, impact reports, white papers, research reports, and policy briefs
- Data visualization, infographics, dashboards, chart redesign, and report graphics
- Brochures, company profiles, case studies, publication templates, and editorial systems
- OCR, PDF data extraction, document automation, spreadsheet cleanup, and repeatable workflows
- AI-assisted research, reporting, and document-processing workflows with human review
If your project involves complex content, data, or documents that need to be clear, polished, and operationally useful, send me a note with the material, deadline, and intended audience.
Steps for completing your project
After purchasing the project, send requirements so Michael Izuchukwu Ayibatonye can start the project.
Delivery time starts when Michael Izuchukwu Ayibatonye receives requirements from you.
Michael Izuchukwu Ayibatonye works on your project following the steps below.
Revisions may occur after the delivery date.
Review sample and output structure
I check sample files, document quality, page count, expected fields, output format, and validation rules before extraction.
Run OCR and extract the data
I process the files with OCR/table extraction, capture the agreed fields, and separate clean records from uncertain pages.