You will get optimized VLSI AI hardware for faster edge computing
Rising Talent


Project details
Hi Client,
Are you trying to fit complex neural networks or heavy DSP algorithms onto low-power edge devices? Taking a machine learning model from software and making it run efficiently on actual silicon is a tough challenge, but it is exactly what I love doing.
I have a Master's in Electronics and am currently doing my PhD in VLSI architecture for neural networks. I specialize in translating heavy mathematical models into optimized, synthesizable Verilog RTL. Before my PhD, I spent five years at TCS-EIS developing ADAS control algorithms (like Automatic Parking Assistants) in MATLAB/Simulink. This means I understand the full picture—from the high-level system behavior down to the strict power, performance, and area constraints of the hardware.
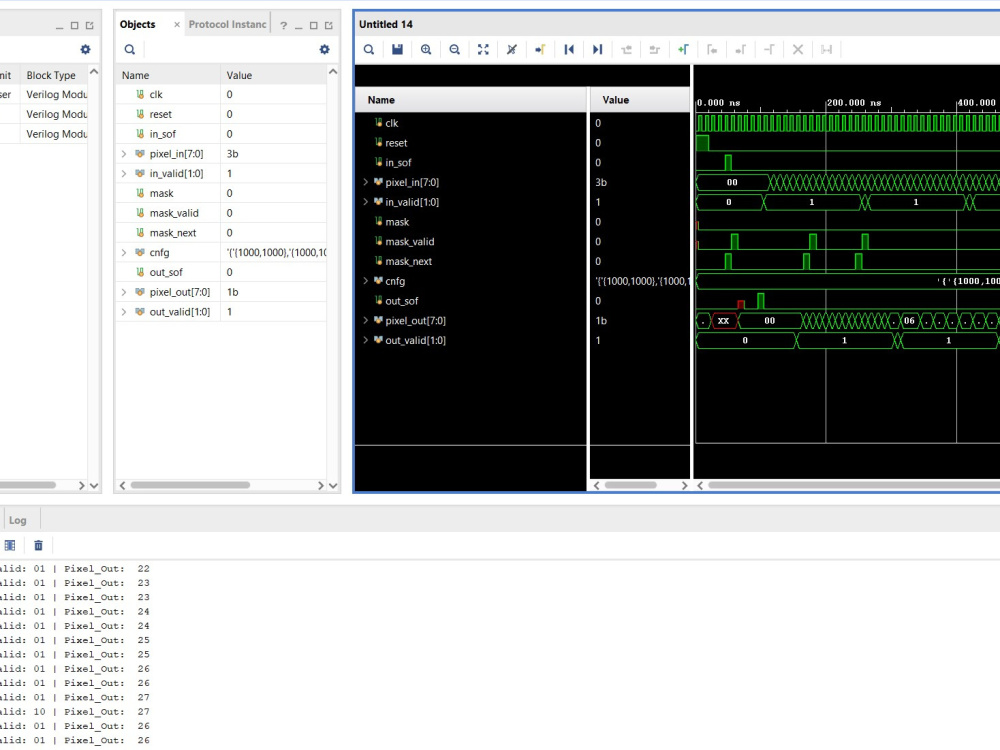
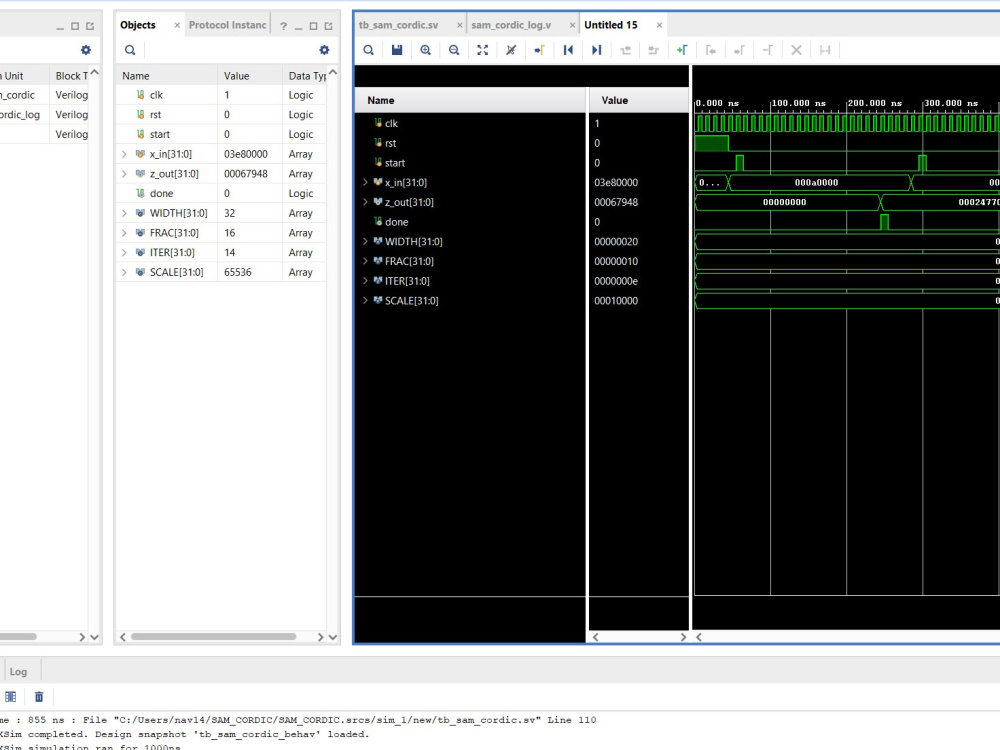
Whether you need a custom neural network accelerator, a low-power CORDIC engine, or a hardware-based Gabor filter, I can build it. I also offer ASIC synthesis and physical design using industry-standard Cadence Genus and Innovus, giving you silicon-proven metrics, not just code. Let's get your AI running flawlessly on hardware.
Thanks,
Naveen Jones
Are you trying to fit complex neural networks or heavy DSP algorithms onto low-power edge devices? Taking a machine learning model from software and making it run efficiently on actual silicon is a tough challenge, but it is exactly what I love doing.
I have a Master's in Electronics and am currently doing my PhD in VLSI architecture for neural networks. I specialize in translating heavy mathematical models into optimized, synthesizable Verilog RTL. Before my PhD, I spent five years at TCS-EIS developing ADAS control algorithms (like Automatic Parking Assistants) in MATLAB/Simulink. This means I understand the full picture—from the high-level system behavior down to the strict power, performance, and area constraints of the hardware.
Whether you need a custom neural network accelerator, a low-power CORDIC engine, or a hardware-based Gabor filter, I can build it. I also offer ASIC synthesis and physical design using industry-standard Cadence Genus and Innovus, giving you silicon-proven metrics, not just code. Let's get your AI running flawlessly on hardware.
Thanks,
Naveen Jones
AI Development Type
Deep LearningAI Tools
MATLAB, NVIDIA AI Platform, PyTorch, TensorFlowAI Development Language
PythonWhat's included
| Service Tiers |
Starter
$100
|
Standard
$250
|
Advanced
$750
|
|---|---|---|---|
| Delivery Time | 4 days | 10 days | 21 days |
Number of Revisions | 1 | 2 | 3 |
AI Model Integration | - | ||
Detailed Code Comments | |||
Knowledge Graph | - | - | - |
Model Documentation | - | ||
Ontology | - | - | - |
Source Code | |||
Taxonomy | - | - | - |
Optional add-ons
You can add these on the next page.
Fast Delivery
+$30 - $200
Additional Revision
+$25
ASIC Logic Synthesis (Cadence Genus)
(+ 4 Days)
+$100
Place & Route / Physical Design (Innovus)
(+ 7 Days)
+$300Frequently asked questions
About Naveen
VLSI Architect | Edge AI Hardware | MATLAB Simulink Engineer
Tiruvalla, India - 10:50 pm local time
What I offer:
1. Hardware-AI Co-Design: Translating complex AI models and non-linear algorithms (CNNs, CORDIC algorithms, Gabor filters) into highly optimized, resource-efficient ASIC/silicon implementations.
2. AI Model Development (Python/PyTorch): Engineering custom, lightweight neural networks from the math up, and optimizing semantic segmentation for autonomous systems.
3. VLSI & Edge Hardware: Delivering production-ready RTL microarchitecture and Edge AI inference engines under strict memory and latency constraints.
4. Model-Based Design: Full-cycle automotive system development, ADAS logic, and control systems using MATLAB/Simulink and Stateflow.
Standard deep learning models are often too bulky for real-world edge devices. I help R&D teams and startups translate complex perception bottlenecks into mathematically optimized, hardware-ready solutions.
Steps for completing your project
After purchasing the project, send requirements so Naveen can start the project.
Delivery time starts when Naveen receives requirements from you.
Naveen works on your project following the steps below.
Revisions may occur after the delivery date.
Algorithm Analysis & Microarchitecture
I will analyze your provided Python/MATLAB reference model or mathematical equations and design a custom hardware microarchitecture (datapath and control unit) optimized for your PPA goals.
RTL Design & Coding
I will write the synthesizable Verilog RTL code for the designed architecture, ensuring it is optimized for your target FPGA or ASIC platform.