You will get PDF & Document OCR Extractor — Automated Data Entry to Excel
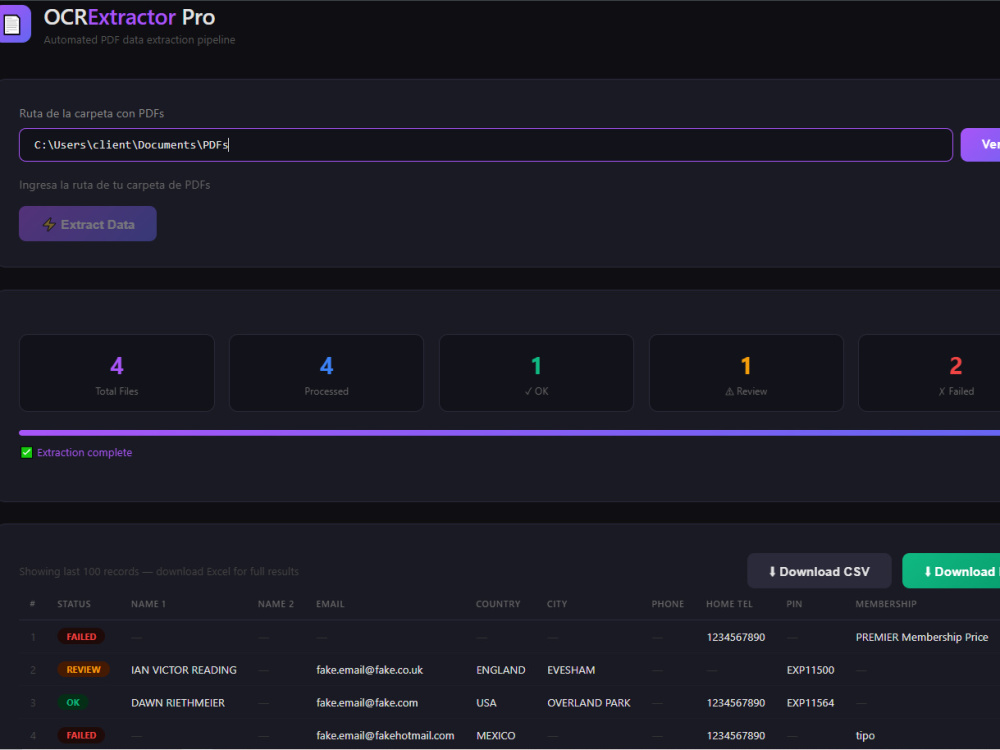
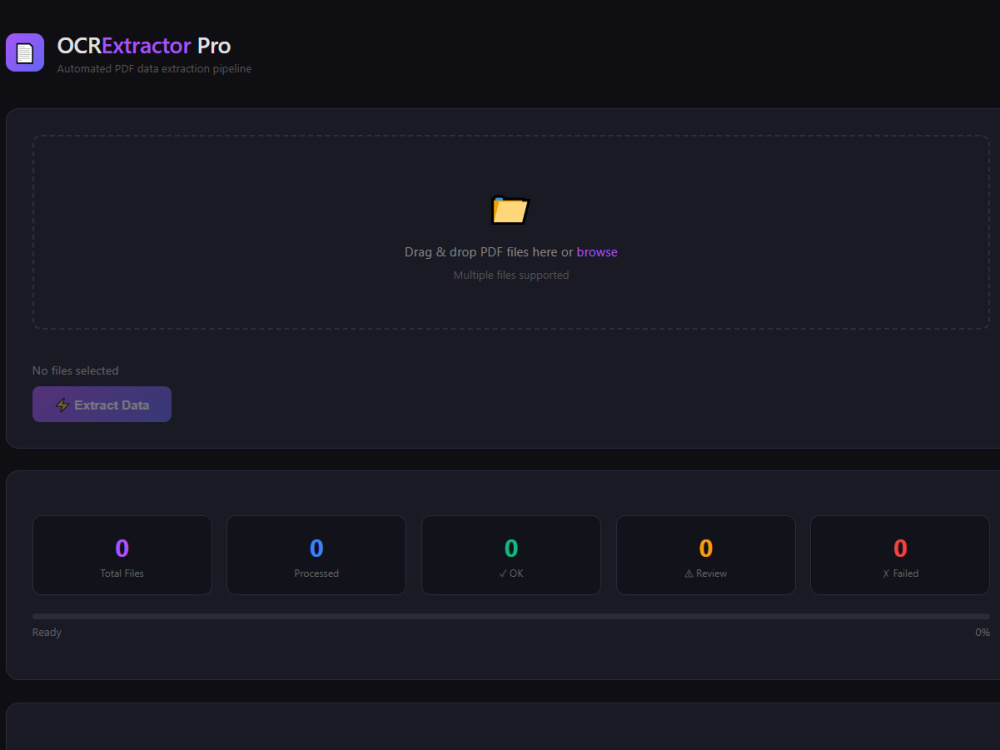
Project details
Still manually typing data from PDFs, invoices, or scanned
forms? I build custom OCR pipelines that read your documents
automatically and deliver clean, structured data to Excel or
CSV — no manual entry required.
Unlike generic OCR tools, my solution is built specifically
for your document format. I analyze your files first,
configure the extraction engine to your exact fields, and
deliver results you can actually use from day one.
Built with Python, Tesseract, and OpenCV — the same stack
used in enterprise document processing — but delivered as a
fast, affordable freelance service.
What makes this different:
✓ Processes hundreds of documents in one batch run
✓ Multi-language support (English + Spanish)
✓ Real-time progress tracking during processing
✓ Status validation — flags uncertain results for review
✓ Built custom for your specific document layout
forms? I build custom OCR pipelines that read your documents
automatically and deliver clean, structured data to Excel or
CSV — no manual entry required.
Unlike generic OCR tools, my solution is built specifically
for your document format. I analyze your files first,
configure the extraction engine to your exact fields, and
deliver results you can actually use from day one.
Built with Python, Tesseract, and OpenCV — the same stack
used in enterprise document processing — but delivered as a
fast, affordable freelance service.
What makes this different:
✓ Processes hundreds of documents in one batch run
✓ Multi-language support (English + Spanish)
✓ Real-time progress tracking during processing
✓ Status validation — flags uncertain results for review
✓ Built custom for your specific document layout
Data Tool
PythonWhat's included
| Service Tiers |
Starter
$99
|
Standard
$350
|
Advanced
$650
|
|---|---|---|---|
| Delivery Time | 3 days | 5 days | 7 days |
Number of Revisions | 1 | 2 | 3 |
Number of Pages Mined/Scraped | 50 | 200 | 1000 |
Number of Sources Mined/Scraped | 1 | 2 | 5 |
Optional add-ons
You can add these on the next page.
Fast Delivery
+$50 - $100
Additional Revision
+$25
Additional Page Mined/Scraped
+$10
Additional Source Mined/Scraped
+$50
Google Sheets Integration
+$75Frequently asked questions
About Diego
Data Automation & Web Scraping Specialist | Python - Node.js - OCR
Playa del Carmen, Mexico - 7:02 pm local time
or documents that need processing by hand? I build the
automations that make those problems disappear.
I'm a Data Automation & Web Scraping specialist with hands-on
experience delivering real solutions:
* Built OCR extractors that automatically process documents,
invoices, and forms — eliminating manual data entry entirely.
* Developed webhook-based Google Sheets automations and bots
that sync live data across platforms in real time.
* Created a Discord bot integrated with a Sheets database that
auto-updated records and messaged agents directly.
* Currently building Elementa Pulse, a cloud-based dialer
system using Node.js and Next.js — so I understand what
production-grade software demands.
My stack: Python · Node.js · Next.js · Google Sheets API ·
OCR · Web Scraping · REST APIs · Webhooks · JavaScript
I don't just write code — I understand your business process
first, then build something that actually solves it. Clean,
documented, and built to last.
Let's automate the boring stuff so you can focus on what
matters.
Steps for completing your project
After purchasing the project, send requirements so Diego can start the project.
Delivery time starts when Diego receives requirements from you.
Diego works on your project following the steps below.
Revisions may occur after the delivery date.
Document Analysis
Review your sample documents, identify all data fields and test OCR accuracy on your specific format.
Pipeline Configuration
Configure the extraction engine for your document type, language, and field layout.