You will get production-ready RAG system with LLM integration
Project details
You will get a production-ready Retrieval-Augmented Generation (RAG) system that enables large language models to answer questions accurately from your private documents. I specialize in building scalable AI backends using FastAPI, vector databases, and modern LLMs such as GPT-4 and open-source models.
Unlike basic chatbot setups, I design RAG systems with proper document chunking, embedding strategies, retrieval optimization, and structured API architecture. The result is a reliable, low-latency AI system ready for real-world use cases such as internal knowledge bases, SaaS features, customer support automation, or document intelligence platforms.
My focus is on clean architecture, performance, and maintainability. You receive well-structured source code, deployment guidance, and a system built to scale, not just a demo.
Unlike basic chatbot setups, I design RAG systems with proper document chunking, embedding strategies, retrieval optimization, and structured API architecture. The result is a reliable, low-latency AI system ready for real-world use cases such as internal knowledge bases, SaaS features, customer support automation, or document intelligence platforms.
My focus is on clean architecture, performance, and maintainability. You receive well-structured source code, deployment guidance, and a system built to scale, not just a demo.
AI Algorithms
Large Language Model, Multimodal Large Language Model, Recurrent Neural Network, Transformer ModelAI Applications
AI Chatbot, AI Content Creation, AI-Enhanced Classification, Conversational AI, Natural Language Generation, Natural Language Understanding, Sequence Modeling, Text RecognitionAI Development Language
PythonAI Tools
Gradio, Hugging Face, PyTorch, StreamlitAI Models
BLOOM, ChatGPT, GPT-3, GPT-4, LLaMA, WhisperWhat's included
| Service Tiers |
Starter
$200
|
Standard
$400
|
Advanced
$800
|
|---|---|---|---|
| Delivery Time | 4 days | 7 days | 10 days |
Number of Revisions | 2 | 3 | |
AI Model Integration | |||
Batch Normalization | - | - | - |
Database Integration | |||
Detailed Code Comments | |||
Image Upscaling | - | - | - |
MLOps | - | - | |
Model Deployment | - | ||
Model Documentation | - | ||
Model Monitoring | - | - | |
Model Testing & Optimization | |||
Model Tuning | - | - | |
Natural Language Processing | |||
NLP Tokenization | - | - | |
Pre-Training | - | - | - |
Prompt Engineering | |||
Setup File | |||
Source Code |
About Eisha
AI & Backend Engineer | FastAPI | Python | LLM | GCP
Faisalabad, Pakistan - 1:18 am local time
In my current role, I architect and maintain Python/FastAPI backends for multiple production platforms, integrating AI-powered features including automated evaluation, feedback generation, and voice-based interaction, alongside AI automation pipelines for data processing, classification, and content workflows. I manage end-to-end data pipelines processing 10,000+ documents monthly, from raw ingestion through LLM-assisted labeling, OCR extraction, and structured output to live app integration.
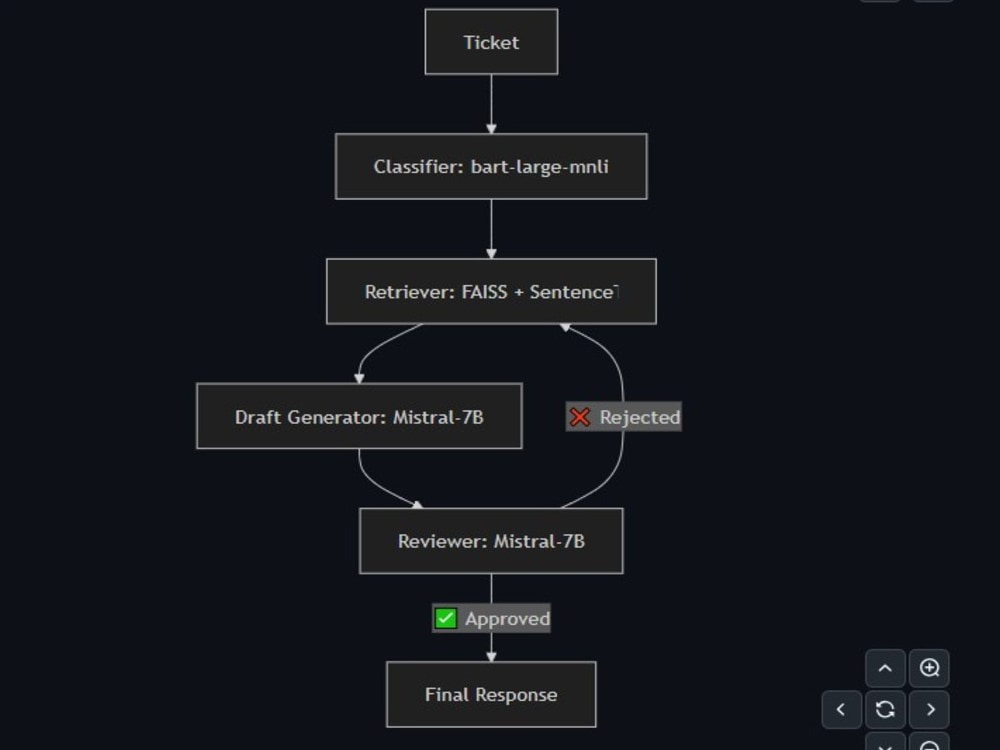
My AI toolkit includes RAG systems (FAISS, SentenceTransformers), LangGraph-based agent workflows, fine-tuning with LoRA (Qwen-1.5-4B), and daily integration of Gemini and OpenAI APIs. I deploy on GCP Cloud Run with Docker and Kubernetes, and have built event-driven pipelines using GCP Pub/Sub.
Available for LLM integration, API integration, AI feature development, backend architecture, and data engineering work.
Steps for completing your project
After purchasing the project, send requirements so Eisha can start the project.
Delivery time starts when Eisha receives requirements from you.
Eisha works on your project following the steps below.
Revisions may occur after the delivery date.
Requirement Analysis
Review documents, use case, and technical constraints.
Architecture Design
Define RAG pipeline: ingestion, embeddings, vector store, LLM flow.