You will get RAG Knowledge System on AWS Bedrock
Rising Talent
Rising Talent
Project details
Most RAG implementations are just a vector database bolted onto an LLM. That breaks at scale poor retrieval quality, inconsistent outputs, and no way to evaluate what is going wrong.
I build production RAG pipelines with proper chunking strategy, retrieval tuning, knowledge base design, and structured output layers. My background includes enterprise manufacturing intelligence systems with RAG powered troubleshooting bots, SOP retrieval, and parts entity resolution, built on AWS Bedrock Knowledge Bases and OpenSearch with full ingestion pipelines.
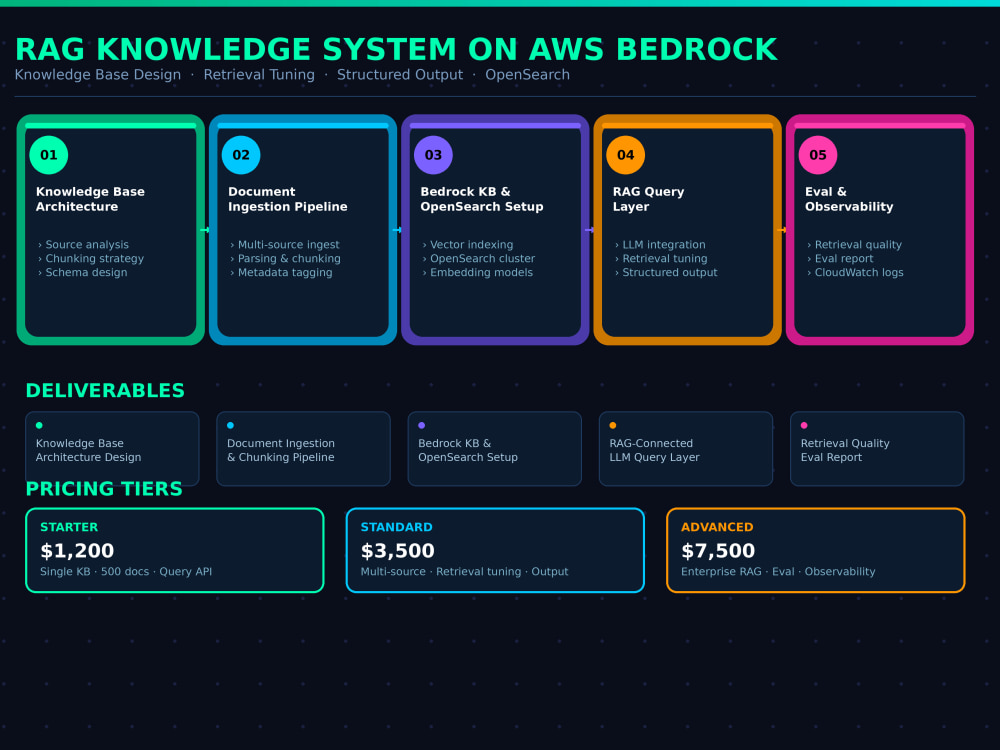
Every engagement starts with a knowledge base architecture design so you know exactly how your documents will be structured, indexed, and retrieved before any build begins. You get a complete ingestion pipeline, a tuned retrieval layer, a connected LLM query API, and a retrieval quality evaluation report.
I have delivered these systems for Fortune 500 manufacturing and automotive companies at AWS, where accuracy, latency, and observability are non-negotiable.
If you need a RAG system that actually works at scale and not just in a demo, this is the engagement for you.
I build production RAG pipelines with proper chunking strategy, retrieval tuning, knowledge base design, and structured output layers. My background includes enterprise manufacturing intelligence systems with RAG powered troubleshooting bots, SOP retrieval, and parts entity resolution, built on AWS Bedrock Knowledge Bases and OpenSearch with full ingestion pipelines.
Every engagement starts with a knowledge base architecture design so you know exactly how your documents will be structured, indexed, and retrieved before any build begins. You get a complete ingestion pipeline, a tuned retrieval layer, a connected LLM query API, and a retrieval quality evaluation report.
I have delivered these systems for Fortune 500 manufacturing and automotive companies at AWS, where accuracy, latency, and observability are non-negotiable.
If you need a RAG system that actually works at scale and not just in a demo, this is the engagement for you.
AI Development Type
Deep Learning, Knowledge Representation, Model TuningAI Tools
Amazon SageMaker, MLflow, PyTorch, TensorFlowAI Development Language
PythonWhat's included
| Service Tiers |
Starter
$1,200
|
Standard
$3,500
|
Advanced
$7,500
|
|---|---|---|---|
| Delivery Time | 10 days | 21 days | 30 days |
Number of Revisions | 1 | 2 | 3 |
AI Model Integration | |||
Detailed Code Comments | - | ||
Knowledge Graph | - | - | |
Model Documentation | - | ||
Ontology | - | - | - |
Source Code | |||
Taxonomy | - |
Optional add-ons
You can add these on the next page.
Fast Delivery
+$200 - $1,000
Additional Revision
+$150About Hassan
Field CTO & GenAI Architect | AWS
Aurora, United States - 11:41 pm local time
◆ $10M+ AI modernization delivered.
◆ 100K+ devices, autonomously managed.
◆ Fortune 500 AI strategy advisor.
What I do:
◆ I architect and ship agentic AI systems from idea to production.
◆ A decade across AWS, enterprise, and unicorn startups.
◆ I know where systems fail. I design so they don't.
Good fit if:
◆ You need a full agentic AI system built and running in production
◆ Your AI works in demos but breaks in the real world
◆ You need multi-agent architecture done properly
◆ You want RAG that actually works, not a vector DB bolted onto an LLM
◆ You're building on AWS and want someone who knows it natively
Stack:
◆ AWS serverless infrastructure
◆ TypeScript, Python, React, React Native
◆ AWS Bedrock AgentCore
◆ LangChain / LangGraph
◆ Strands SDK
◆ MCP (Model Context Protocol)
◆ A2A for multi-agent communication
I keep my work focused. Reach out, happy to talk.
Steps for completing your project
After purchasing the project, send requirements so Hassan can start the project.
Delivery time starts when Hassan receives requirements from you.
Hassan works on your project following the steps below.
Revisions may occur after the delivery date.
Knowledge Base Architecture & Ingestion Pipeline
I analyze your documents and data sources, define the chunking strategy and schema, then build a full ingestion pipeline with parsing, metadata tagging, and vector indexing on OpenSearch.
Bedrock Knowledge Base Setup & Retrieval Tuning
I configure AWS Bedrock Knowledge Bases, connect the OpenSearch index, and tune retrieval parameters to maximize accuracy and relevance for your specific query types.