You will get Real-Time Data Architecture - Architecture, Design and Implementation
Project details
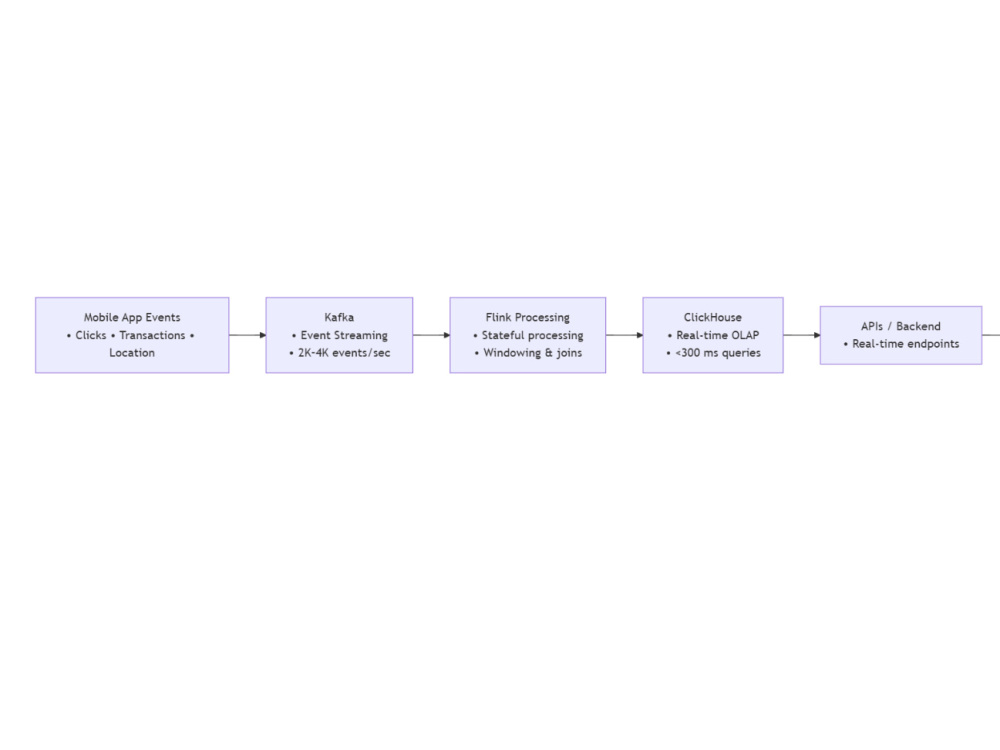
You will get a scalable, production-ready real-time data pipeline built using tech stack like Apache Kafka, Apache Flink, DuckDB, ClickHouse, etc designed to handle high-volume streaming data with low latency (<1-2 seconds).
With strong expertise in real-time systems, distributed architectures, and large-scale data processing, I help businesses move from delayed batch reporting to instant, actionable insights.
What sets me apart:
Hands-on experience with millions of events/day pipelines
Expertise in stateful stream processing (Flink)
Deep optimization knowledge of ClickHouse for sub-second analytics
Focus on production-grade systems (scalable, fault-tolerant, reliable)
Clean, modular, and well-documented implementation
Whether you're building real-time dashboards, tracking systems, or event-driven applications, I deliver solutions that are efficient, scalable, and ready for growth.
With strong expertise in real-time systems, distributed architectures, and large-scale data processing, I help businesses move from delayed batch reporting to instant, actionable insights.
What sets me apart:
Hands-on experience with millions of events/day pipelines
Expertise in stateful stream processing (Flink)
Deep optimization knowledge of ClickHouse for sub-second analytics
Focus on production-grade systems (scalable, fault-tolerant, reliable)
Clean, modular, and well-documented implementation
Whether you're building real-time dashboards, tracking systems, or event-driven applications, I deliver solutions that are efficient, scalable, and ready for growth.
Database Type
MySQL, MS SQL, PostgreSQL, MongoDB, Azure Cosmos DBWhat's included
| Service Tiers |
Starter
$5
|
Standard
$1,000
|
Advanced
$3,500
|
|---|---|---|---|
| Delivery Time | 3 days | 20 days | 60 days |
Number of Revisions | 2 | Unlimited | 3 |
Schema Diagram | |||
Permissions Setup | - | - | |
Import/Export Data | - | ||
Admin Panel Setup | - | - |
Optional add-ons
You can add these on the next page.
DevOps
+$20Frequently asked questions
1 review
(1)
(0)
(0)
(0)
(0)
This project doesn't have any reviews.
KB
Karandeep B.
May 1, 2017
URGENT 6 Data entry Operators needed to enter data from PDF to excel file
About Rahul
Data Engineer | Databricks | Azure/AWS | ETL/ELT | Agentic AI
Surat, India - 3:54 am local time
I design and deliver robust, scalable data solutions and AI-ready pipelines that turn noisy data into reliable insights. I focus on pragmatic engineering (Databricks, Microsoft Fabric, Delta Lake, PySpark) and ship production-grade solutions that support analytics, AI/ML applications.
⚙️𝐂𝐨𝐫𝐞 𝐞𝐱𝐩𝐞𝐫𝐭𝐢𝐬𝐞
----------------------
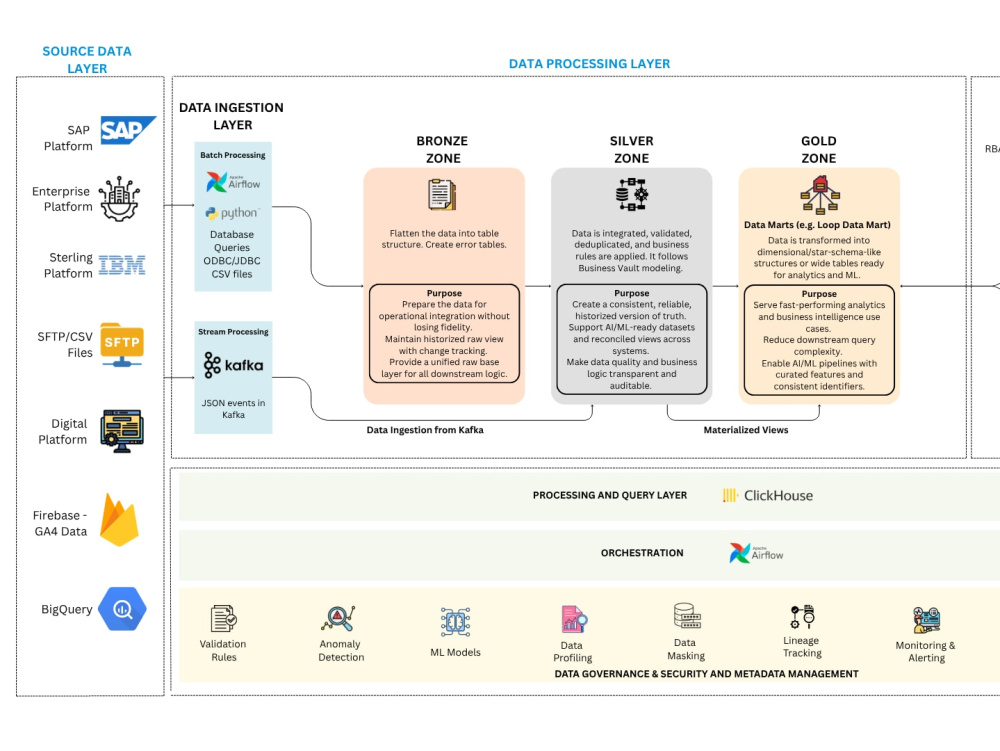
● A𝐫𝐜𝐡𝐢𝐭𝐞𝐜𝐭𝐮𝐫𝐞𝐬 (𝐁𝐫𝐨𝐧𝐳𝐞 → 𝐒𝐢𝐥𝐯𝐞𝐫 → 𝐆𝐨𝐥𝐝) – Databricks & Microsoft Fabric
● 𝐄𝐓𝐋/𝐄𝐋𝐓 – PySpark, Delta Lake, Delta Live Tables, Autoloader
● 𝐒𝐭𝐫𝐞𝐚𝐦𝐢𝐧𝐠 – Kafka, Event Hubs, Structured Streaming, exactly-once processing
● 𝐂𝐥𝐨𝐮𝐝 & 𝐎𝐫𝐜𝐡𝐞𝐬𝐭𝐫𝐚𝐭𝐢𝐨𝐧 – ADF, ADLS Gen2, Functions, S3, Lambda, GitHub Actions/Azure DevOps
● 𝐌𝐋𝐎𝐩𝐬 & 𝐅𝐞𝐚𝐭𝐮𝐫𝐞 𝐄𝐧𝐠𝐢𝐧𝐞𝐞𝐫𝐢𝐧𝐠 – MLflow, reproducible feature pipelines for RAG/ML
● 𝐒𝐞𝐦𝐚𝐧𝐭𝐢𝐜 𝐬𝐞𝐚𝐫𝐜𝐡 & 𝐑𝐀𝐆 – Embeddings, Qdrant, retrieval pipelines, LLM orchestration
● 𝐀𝐠𝐞𝐧𝐭𝐢𝐜 𝐀𝐈 𝐰𝐨𝐫𝐤𝐟𝐥𝐨𝐰𝐬 – LangChain, LangGraph, LangSmith
● 𝐎𝐛𝐬𝐞𝐫𝐯𝐚𝐛𝐢𝐥𝐢𝐭𝐲 & 𝐈𝐚𝐂 – Azure Monitor, alerts, Terraform-based deployments
🧰𝐓𝐞𝐜𝐡 𝐬𝐭𝐚𝐜𝐤
-----------------
● PySpark ● Python ● SQL ● Databricks ● Microsoft Fabric ● Delta Lake ● Kafka ● ADF ● MLflow ● Qdrant ● LangChain ● LangGraph ● Docker ● Terraform ● Power BI
🎯𝐒𝐨𝐦𝐞 𝐨𝐮𝐭𝐜𝐨𝐦𝐞𝐬 (𝐰𝐡𝐚𝐭 𝐈'𝐯𝐞 𝐝𝐞𝐥𝐢𝐯𝐞𝐫𝐞𝐝)
----------------------------------------------------
● Legacy ETL to Databricks + Delta, cutting runtime by ~30%.
● Agentic code-translation prototype (LLM + vector DB), cuts migration effort by ~60%.
● Delivered near-real-time financial dashboards using Structured Streaming + DLT.
🚀𝐖𝐡𝐚𝐭 𝐈 𝐜𝐚𝐧 𝐝𝐨 𝐟𝐨𝐫 𝐲𝐨𝐮
-----------------------------
● End-to-end Data Platforms
● Streaming & Batch Pipelines
● Migration & Modernization
● Feature Engineering & MLOps
● Semantic Search & RAG
● Agentic AI & Automation
● Observability & Automation
🤝𝐇𝐨𝐰 𝐈 𝐰𝐨𝐫𝐤
-----------------
● Fast discovery call → proposal with milestones → clean deliverables + handover docs.
● Communication: weekly checkpoints + Slack/email updates.
I value clear acceptance criteria and measurable outcomes.
If you need a migration plan, or an AI-assisted pipeline, send (problem + data size + timeline) - I'll reply with 𝐚 𝐩𝐫𝐨𝐩𝐨𝐬𝐞𝐝 𝐚𝐩𝐩𝐫𝐨𝐚𝐜𝐡 𝐚𝐧𝐝 𝐞𝐬𝐭𝐢𝐦𝐚𝐭𝐞𝐝 𝐦𝐢𝐥𝐞𝐬𝐭𝐨𝐧𝐞𝐬.
Steps for completing your project
After purchasing the project, send requirements so Rahul can start the project.
Delivery time starts when Rahul receives requirements from you.
Rahul works on your project following the steps below.
Revisions may occur after the delivery date.
Requirements & Use Case Understanding
Discuss data sources, use case, and expected outcomes. Define latency, scale, and architecture requirements
Architecture Design
Design streaming architecture (Kafka + Flink + ClickHouse). Define topics, schemas, and processing logic. Share architecture for approval