You will get Scalable Data Lakehouse & ETL Automation with Spark, Snowpark, or SQL
Project details
Multilingual Data Architect | End-to-End Pipelines & Scalable Lakehouse Solutions
With 4 years of experience as a Data Engineer, I specialize in building high-performance, platform-agnostic data systems that turn fragmented data into a competitive advantage. My approach is centered on architectural excellence: I don’t just write code; I design scalable infrastructures that grow with your business.
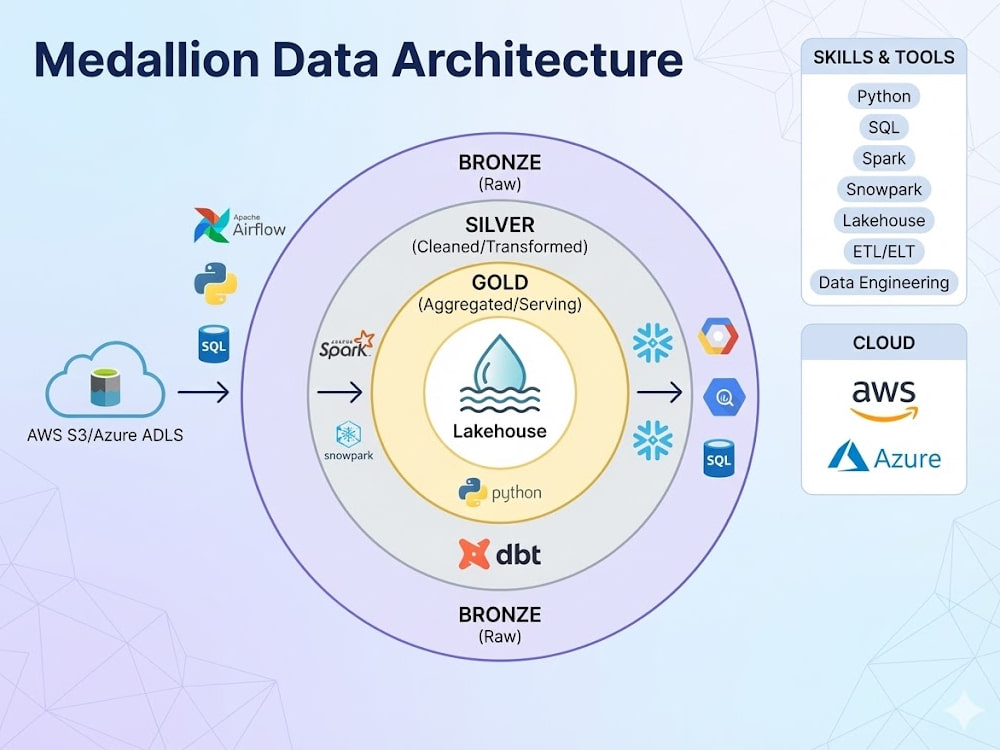
I bring a polyglot approach to data engineering. Whether your stack is built on Python, Spark, Snowpark, or SQL, and whether you use Snowflake, Databricks, AWS, or Azure, I implement robust Medallion Architectures (Bronze, Silver, Gold) tailored to your specific constraints. My focus is on creating a "single source of truth" that is automated, cost-optimized, and highly reliable.
I bridge the gap between complex engineering and actionable business value. Let’s build a flexible data foundation that serves your needs today and tomorrow.
With 4 years of experience as a Data Engineer, I specialize in building high-performance, platform-agnostic data systems that turn fragmented data into a competitive advantage. My approach is centered on architectural excellence: I don’t just write code; I design scalable infrastructures that grow with your business.
I bring a polyglot approach to data engineering. Whether your stack is built on Python, Spark, Snowpark, or SQL, and whether you use Snowflake, Databricks, AWS, or Azure, I implement robust Medallion Architectures (Bronze, Silver, Gold) tailored to your specific constraints. My focus is on creating a "single source of truth" that is automated, cost-optimized, and highly reliable.
I bridge the gap between complex engineering and actionable business value. Let’s build a flexible data foundation that serves your needs today and tomorrow.
Data Tool
PythonWhat's included
| Service Tiers |
Starter
$250
|
Standard
$2,000
|
Advanced
$4,000
|
|---|---|---|---|
| Delivery Time | 3 days | 14 days | 30 days |
Number of Revisions | 1 | 1 | 2 |
About Simao
Data Architect and Engineer
Lisbon, Portugal - 5:48 pm local time
With strong skills in Spark (Python and SQL), I design and build scalable, high-performance data pipelines that transform raw data into valuable insights.
Currently, I work in the football industry, building end-to-end data architectures for elite football clubs — integrating multiple data providers and ensuring data quality, governance, and performance at scale.
Previously, I worked in consultancy environments, developing and maintaining ETL pipelines for clients across different industries. This gave me both deep technical expertise and solid business understanding, allowing me to translate complex requirements into efficient, real-world data solutions.
I hold a Master’s in Data Science and Advanced Analytics and am passionate about continuous learning — always exploring new ways to improve data architecture, automation, and cloud efficiency.
If you need a data professional who can design, optimize, or troubleshoot your data pipelines and architecture — from ingestion to analytics — I’d be happy to help.
Steps for completing your project
After purchasing the project, send requirements so Simao can start the project.
Delivery time starts when Simao receives requirements from you.
Simao works on your project following the steps below.
Revisions may occur after the delivery date.
Documentation and knowledge handover
In the end a deliver to the client documentation of what I built and share all the know how involved in the making of the project