You will get Scalable dbt Transformations for Clean & Analytics-Ready Data
Project details
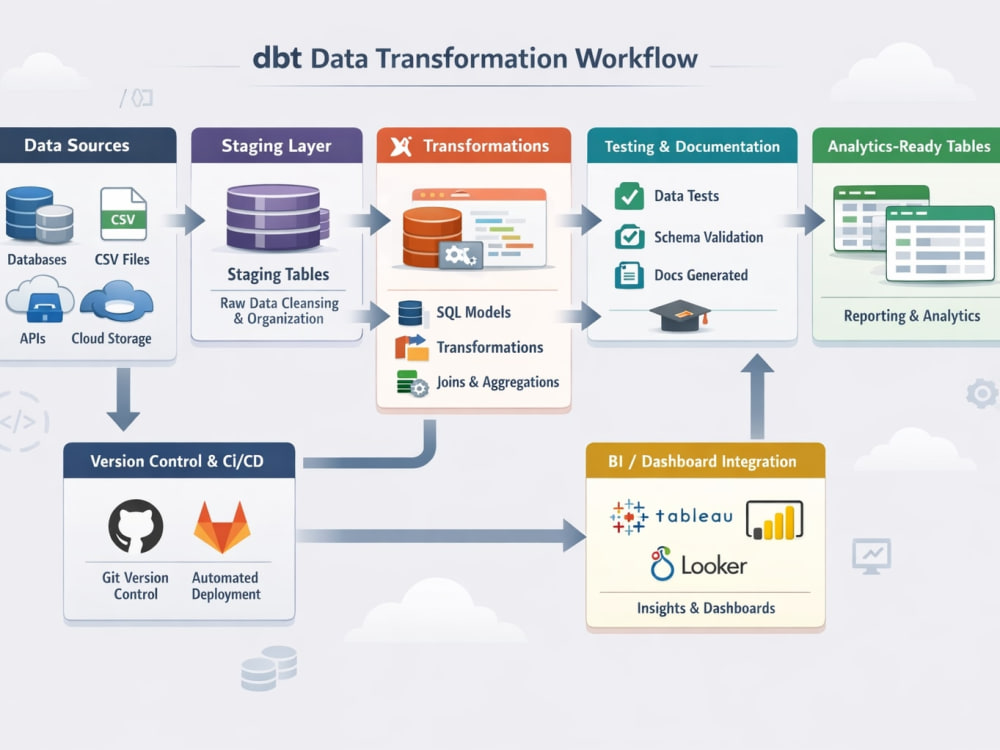
I build robust, scalable, and modular dbt (data build tool) pipelines that transform raw data into analytics-ready tables. My projects are designed for modern data warehouses like Snowflake, BigQuery, Redshift, or Databricks and include modular SQL models, automated testing, documentation, and CI/CD-ready deployment. I focus on clean, reliable, and maintainable data pipelines that help businesses streamline reporting, dashboards, and analytics. With this project, you will get high-quality, production-ready dbt transformations tailored to your business logic, enabling faster, data-driven decisions and scalable workflows.
Data Tool
SQLWhat's included
| Service Tiers |
Starter
$301
|
Standard
$601
|
Advanced
$901
|
|---|---|---|---|
| Delivery Time | 3 days | 5 days | 7 days |
Number of Revisions | 1 | 2 | 3 |
Optional add-ons
You can add these on the next page.
Fast Delivery
+$70 - $120
Additional Revision
+$80Frequently asked questions
About Rohit
AWS Data Engineer | ETL Pipelines | Glue, Redshift, PySpark, Airflow
Sambhaji Nagar, India - 11:03 am local time
My core expertise lies in designing and implementing Modern Data Stack architectures on AWS ☁️—helping organizations move from spreadsheets, siloed databases, and legacy systems to centralized data lakes, high-performance data warehouses, and self-service analytics.
Over the past 3+ years, I have worked on data engineering solutions across 20+ industries, including Logistics & Supply Chain, ERP, Finance & Banking, FinTech & Payments, Insurance, Healthcare & Life Sciences, Government & Public Sector, Telecom, IoT & Smart Devices, Energy & Utilities, Manufacturing, SaaS & Product Analytics, E-commerce & Retail, Marketing & AdTech, Media & Entertainment, Gaming, Education, Real Estate, Travel & Hospitality, and HR & People Analytics 🌍.
This multi-industry exposure allows me to quickly understand business context, design domain-aware data models, and deliver analytics platforms that stakeholders can trust.
🔹 What I Do Best 🚀
I help organizations at different stages of their data journey:
🗄️ Design AWS Data Lakes using Amazon S3, Glue, Athena, EMR
🔄 Build scalable ELT pipelines using Python, SQL, PySpark, Spark SQL
🏗️ Develop analytics-ready Data Warehouses on Amazon Redshift & Snowflake
🧩 Implement dbt transformation layers with clean, tested models
📐 Model business data (Fact-Dimension, Star Schema, SCD Type 2)
📊 Enable BI & executive dashboards with trusted datasets
🔍 Improve data quality, monitoring & governance for production systems
I focus not just on moving data—but on making data usable, understandable, and reliable.
🔹 Modern Data Stack Expertise 🧠
☁️ Cloud & Big Data
AWS (S3, Glue, EMR, Redshift, Athena, Lambda), Snowflake
⚙️ Data Engineering
Python, SQL, PySpark, Spark SQL, Apache Airflow, dbt
📐 Analytics & Modeling
Dimensional Modeling, Fact & Dimension Tables, SCD Type 2, KPI Design
🔁 DevOps & Delivery
Git, CI/CD Pipelines, Agile/Scrum, Jira, Automation
📈 BI & Reporting
Power BI, Executive Dashboards, Analytics Reporting
🔹 How I Approach Projects 🧩
My working style is structured, transparent, and business-driven:
🧱 Clear architecture before writing code
⚡ Performance, scalability, and cost efficiency
🧼 Clean, maintainable, well-documented pipelines
🧠 Business-friendly data models
📦 Handover-ready solutions (no vendor lock-in)
Whether it’s a greenfield data platform, legacy modernization, or analytics optimization, I focus on building solutions that scale with your business.
🔹 Who I Work With 🤝
🚀 Startups building their first analytics platform
🏢 Enterprises modernizing legacy systems
📱 Product teams needing reliable product insights
⚙️ Operations teams requiring real-time & historical analytics
🧑💼 Leadership teams needing trusted executive reporting
🔹 Why Clients Choose Me ⭐
Strong balance of technical depth & business understanding
Ability to work across multiple industries and data domains
Focus on long-term stability, not quick fixes
Clear communication & realistic delivery timelines
Enterprise-grade mindset—even for small teams
If you’re looking for a dependable AWS Data Engineer who can design, build, and scale data platforms the right way, I’d be happy to discuss your requirements 💬.
📩 Let’s turn your data into a reliable asset—not a bottleneck.
Steps for completing your project
After purchasing the project, send requirements so Rohit can start the project.
Delivery time starts when Rohit receives requirements from you.
Rohit works on your project following the steps below.
Revisions may occur after the delivery date.
Client sends project requirements
Provide data source access, transformation rules, and analytics goals.
Setup dbt environment:
Setup dbt environment: Configure your warehouse and initialize dbt project.