You will get Seamless Migration of On-Premises Data Infrastructure to the Cloud
Top Rated

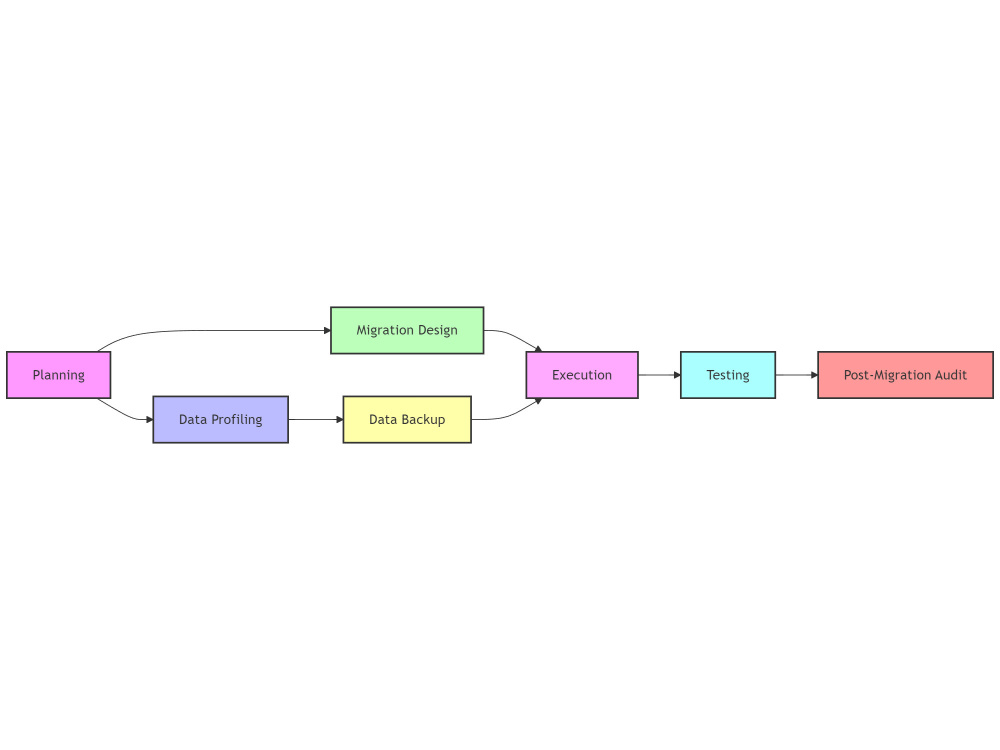
Project details
You will receive a seamless and efficient migration of your on-premises data infrastructure to the cloud, tailored to your specific business needs. With over 5 of experience in building and migrating complex data pipelines, I help businesses optimize their data workflows and reduce operational costs. I specialize in AWS, Azure, and GCP cloud environments, ensuring a smooth transition with minimal disruption to your business operations.
Database Type
MySQL, MS SQL, Oracle, PostgreSQL, MongoDB, Teradata, Azure Cosmos DBWhat's included
| Service Tiers |
Starter
$150
|
Standard
$600
|
Advanced
$1,000
|
|---|---|---|---|
| Delivery Time | 1 day | 5 days | 10 days |
Number of Revisions | 1 | 2 | 3 |
Source Code | - | - | - |
Optional add-ons
You can add these on the next page.
Fast Delivery
+$100 - $200
Additional Revision
+$50
Extended Post-Migration Support
(+ 10 Days)
+$250
Performance Optimization
(+ 1 Day)
+$150Frequently asked questions
22 reviews
(22)
(0)
(0)
(0)
(0)
This project doesn't have any reviews.
DT
David T.
Dec 12, 2025
Python/Postgres SQL-to-Excel job with links, change tracking, and multi-sheet output
Fantastic vibe coding by Dmitry. He understood the requirements and was able to generate well written code. When asked to make changes or to implement changes he was able to provide suggestions on different approaches. This demonstrated he knew best practices in software engieneering. I'll gladly work with Dmitry on a future project.
VM
Vansh M.
Sep 18, 2025
Python Developer Needed for Proxy Optimization, PostgreSQL Database, and PDF Generation
Dmitry is perfect for all kind of job he says yes. always on point and on time. always uses logics that i missed. lobve to work with him,
RW
Russell W.
Apr 7, 2025
Data Analysis, Programming, and Reporting
Dmitry is a great and dedicated worker! If you have a data project and want someone to really dig into it, he is your man!
BH
Brian H.
Mar 13, 2021
File Scrapper - Resume
MU
Maxim U.
Dec 29, 2020
Implement Reverse RSI indicator in Python
About Dmitry
AI Data Engineer, Database Architect | SQL dbt Databricks RAG Agents
100%
Job Success
Almaty, Kazakhstan - 2:01 pm local time
With 7 years of experience, I help companies:
• Transform messy data into automated, reliable, and scalable ETL pipelines for complex financial data that save 100+ hours monthly
• Architect distributed database systems: Design multi-tier data architectures for massive-scale record management
• Build advanced ETL pipelines with intelligent change detection to process only what's changed, reducing unnecessary processing
• Architect cloud-native data solutions and scale data infrastructure across multiple clouds
• Automate data workflows to eliminate manual processing and escape Excel Hell
• Build Information Retrieval (IR), semantic search, OpenSearch, and Retrieval-Augmented Generation (RAG) systems that make massive datasets, documents, and knowledge bases searchable and actionable
• Develop AI-powered data applications, including document intelligence, chatbot, and agent-based solutions integrated with existing business workflows
• Modernize legacy data systems with cloud & AI solutions
• Optimize data infrastructure to reduce costs and improve performance
• Design parallel execution frameworks: Implement isolation patterns enabling concurrent pipeline runs without conflicts
• Build data foundations for AI initiatives, including vector search, knowledge retrieval, document processing, and AI automation workflows
I have been providing a wide range of services in the realm of data analytics and data engineering such as:
• ETL/ELT pipeline orchestration: Prefect, Databricks Workflows & Asset Bundles
• Lakehouse & distributed database architecture: Databricks/Delta, YugabyteDB (distributed PostgreSQL), Neo4j, OpenSearch
• Custom dbt materializations and incremental models: SCD-2, temporal tables
• Database optimization and storage compression
• Data validation, quality quarantine & reconciliation frameworks
• Per-run schema isolation and parallel pipeline execution
• Google Sheets automation and dashboard generation
• Excel-to-database migration and formula translation
• Multi-source data integration: CSV, Parquet, S3, APIs, databases
• Data Cleaning & Transformation at scale
• Operational Efficiency Analysis
• Financial metrics calculation systems
• Multi-cloud architecture design
• Infrastructure as Code
• Cloud services integration: AWS, GCP, Azure
• RAG & LLM data applications: grounded citations, document extraction, NL-to-SQL semantic layers
• Automated reporting solutions (Python-Excel integration)
• Data Visualization & Dashboarding
While the above services encapsulate my core offerings, I am inherently adaptable and thrive on diving into new challenges and expanding my skill set. Seeking great, enthusiastic projects that will provide me with challenging, interesting work that I can learn from and contribute to.
My stack:
Data Engineering:
✅ Python
✅ SQL (PostgreSQL, MySQL, SQL Server, YugabyteDB, DuckDB)
✅ Prefect
✅ dbt
✅ PySpark
✅ Delta Lake
✅ Databricks
Cloud & Infrastructure:
✅ AWS (EC2, S3, Glue, RDS, Lambda, EKS, DynamoDB, ECR, Bedrock)
✅ Google Cloud Platform (BigQuery, GKE, Bigtable, Cloud Functions)
✅ Azure (ADF, Synapse, AKS, Cosmos DB, Azure Functions, ACR, Text Analytics)
✅ Terraform
✅ Docker
✅ Kubernetes
✅ Prometheus
Data Storages:
✅ RDBMS (PostgreSQL, MySQL, SQL Server, DuckDB)
✅ Object Storage (S3, Wasabi)
✅ Graph Database (Neo4j)
✅ Key-Value Database (Redis, DynamoDB)
✅ Document Database + Search Engine (OpenSearch)
ETL & Data Processing:
✅ Pandas
✅ NumPy
✅ Selenium
✅ BeautifulSoup
Spreadsheet Automation:
✅ Google Sheets API (gspread)
✅ Excel automation (openpyxl, xlwings)
✅ Automated dashboard generation
Data Visualization:
✅ Matplotlib
✅ Seaborn
✅ Plotly
✅ Power BI
✅ Grafana
Backend Development:
✅ FastAPI
✅ Flask
✅ RESTful APIs
✅ GraphQL
✅ Redis
✅ Nginx
✅ Gunicorn
✅ WebSocket
AI/LLM & Agent Systems:
✅ OpenAI API
✅ Anthropic API
✅ Gemini API
✅ AWS Bedrock
✅ Agent Development
✅ AI Chatbots
✅ RAG
✅ NL-to-SQL semantic layers
✅ Semantic search
Steps for completing your project
After purchasing the project, send requirements so Dmitry can start the project.
Delivery time starts when Dmitry receives requirements from you.
Dmitry works on your project following the steps below.
Revisions may occur after the delivery date.
Initial Consultation and Requirement Gathering
We will discuss your current data infrastructure and migration goals to develop a migration strategy.
Assessment and Migration Plan
I will evaluate your current on-prem infrastructure and create a detailed migration plan, including timelines and any potential risks.