You will get Support for Your Python Scikit-Learn Machine Learning Project

Project details
I am a skilled Data Scientist and Machine Learning Engineer with experience in Python, Pandas, NumPy, Matplotlib, Seaborn, and Sci-kit Learn. I offer a comprehensive range of services to tackle your data needs. Whether dealing with small or big data, I can help you extract meaningful insights, build predictive models, and provide actionable results.
📌**What you can expect from this gig:**📌
✅Regression and Classification Predictive Modeling:
👉Simple Linear Regression
👉Multiple Linear Regression
👉Polynomial Regression
👉Ridge Regression (L2 Regularization)
👉Lasso Regression (L1 Regularization)
👉Logistic Regression
👉Decision Tree
👉Support Vector Regression (SVR)
👉Support Vector Machine (SVM)
👉Kernel SVM
👉K-Nearest Neighbors
👉Naive Bayes
✅Bagging and Boosting Ensemble Learning:
👉Random Forest
👉AdaBoost
👉CatBoost
👉LightGBM
👉Gradient Boosting
👉XGBoost
✅Clustering:
👉K-Means Clustering
👉Hierarchical clustering
✨Make data-driven decisions and gain a competitive edge with my data science and machine learning service. Contact me before placing the order today to discuss your project, and let's turn your data into actionable insights.
📌**What you can expect from this gig:**📌
✅Regression and Classification Predictive Modeling:
👉Simple Linear Regression
👉Multiple Linear Regression
👉Polynomial Regression
👉Ridge Regression (L2 Regularization)
👉Lasso Regression (L1 Regularization)
👉Logistic Regression
👉Decision Tree
👉Support Vector Regression (SVR)
👉Support Vector Machine (SVM)
👉Kernel SVM
👉K-Nearest Neighbors
👉Naive Bayes
✅Bagging and Boosting Ensemble Learning:
👉Random Forest
👉AdaBoost
👉CatBoost
👉LightGBM
👉Gradient Boosting
👉XGBoost
✅Clustering:
👉K-Means Clustering
👉Hierarchical clustering
✨Make data-driven decisions and gain a competitive edge with my data science and machine learning service. Contact me before placing the order today to discuss your project, and let's turn your data into actionable insights.
Machine Learning Tools
Azure Machine Learning, Google Sheets, Keras, Microsoft Excel, MLflow, NumPy, pandas, Python, Python Scikit-Learn, scikit-learn, SciPy, SQL, TensorFlow, XGBoostWhat's included
| Service Tiers |
Starter
$50
|
Standard
$100
|
Advanced
$300
|
|---|---|---|---|
| Delivery Time | 1 day | 3 days | 7 days |
Number of Revisions | 1 | Unlimited | Unlimited |
Number of Model Variations | 2 | 5 | 7 |
Number of Scenarios | 1 | ||
Number of Graphs/Charts | 1 | 3 | 5 |
Model Validation/Testing | |||
Model Documentation | - | ||
Data Source Connectivity | |||
Source Code |
Optional add-ons
You can add these on the next page.
Fast Delivery
+$20 - $30Frequently asked questions
About Sivanujan
Statistical Data Analyst || Data Scientist || Machine Learning
Colombo, Sri Lanka - 1:33 am local time
✅Strengths & Skills:
⚡Advanced proficiency in Python, Pandas, NumPy, and Scikit-learn.
⚡Expertise in data preprocessing, feature engineering, and exploratory data analysis.
⚡Development of machine learning models for classification, regression, and forecasting.
⚡Strong visualization skills using Seaborn, Matplotlib, and Plotly.
✅Key Projects & Accomplishments:
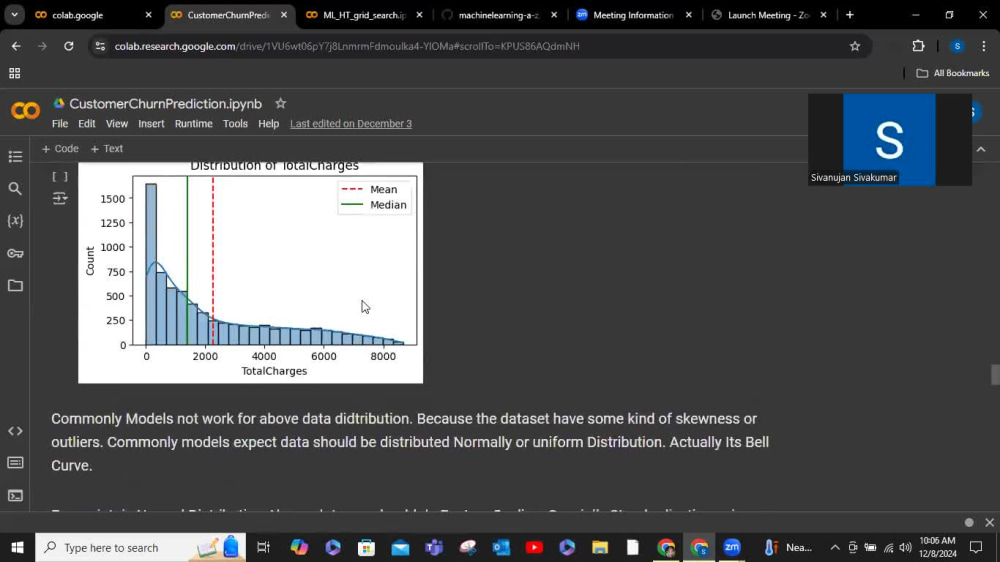
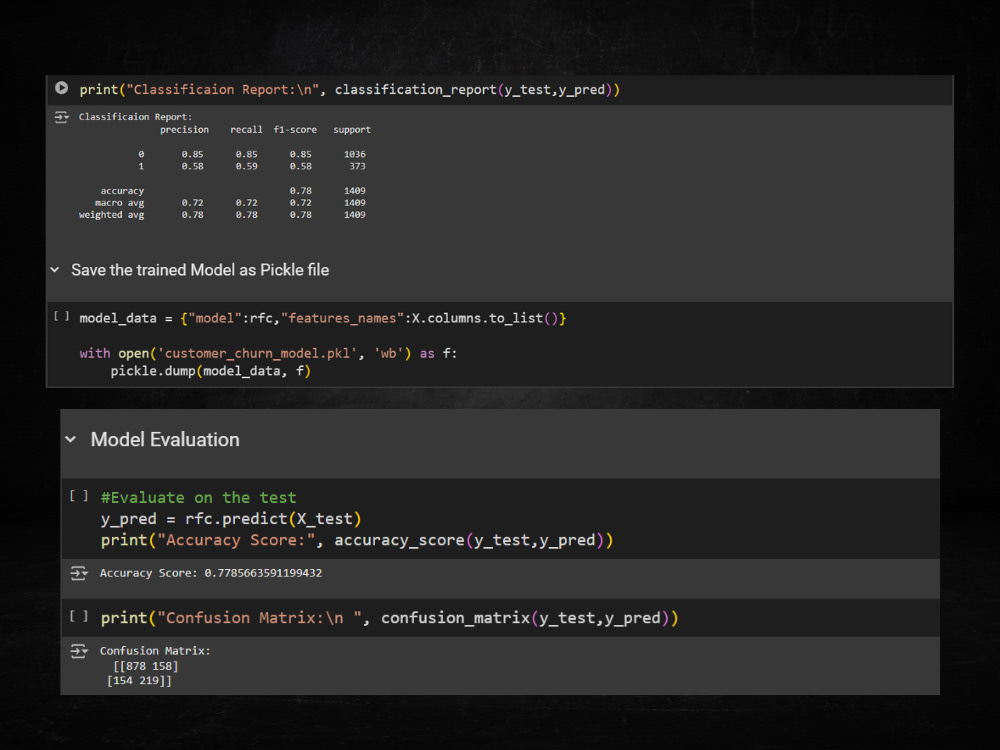
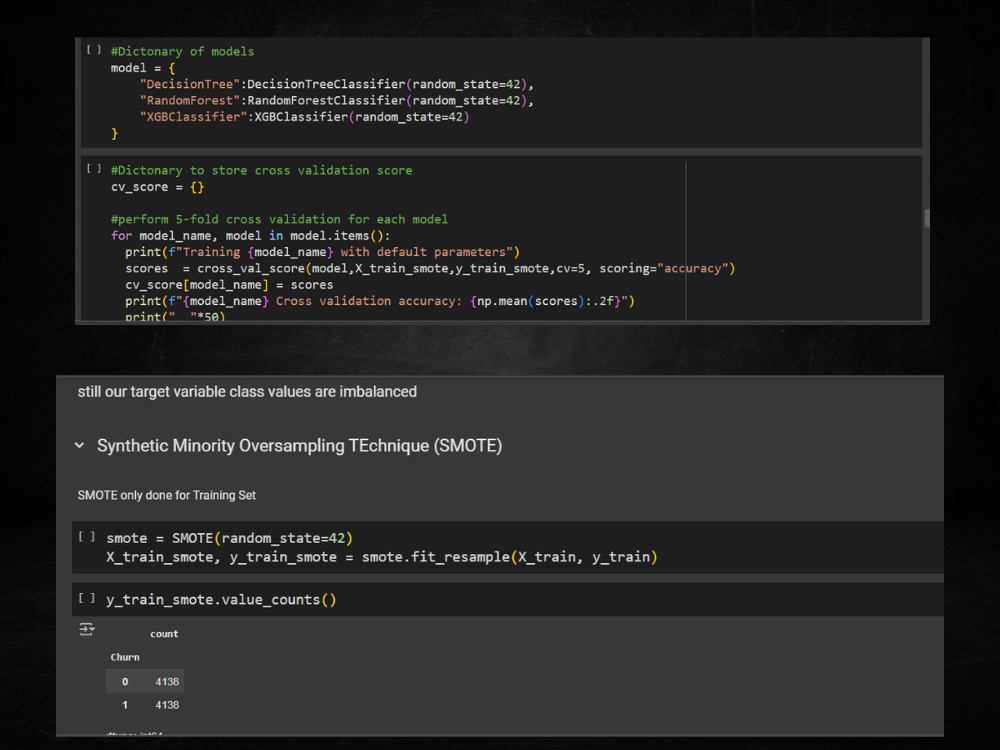
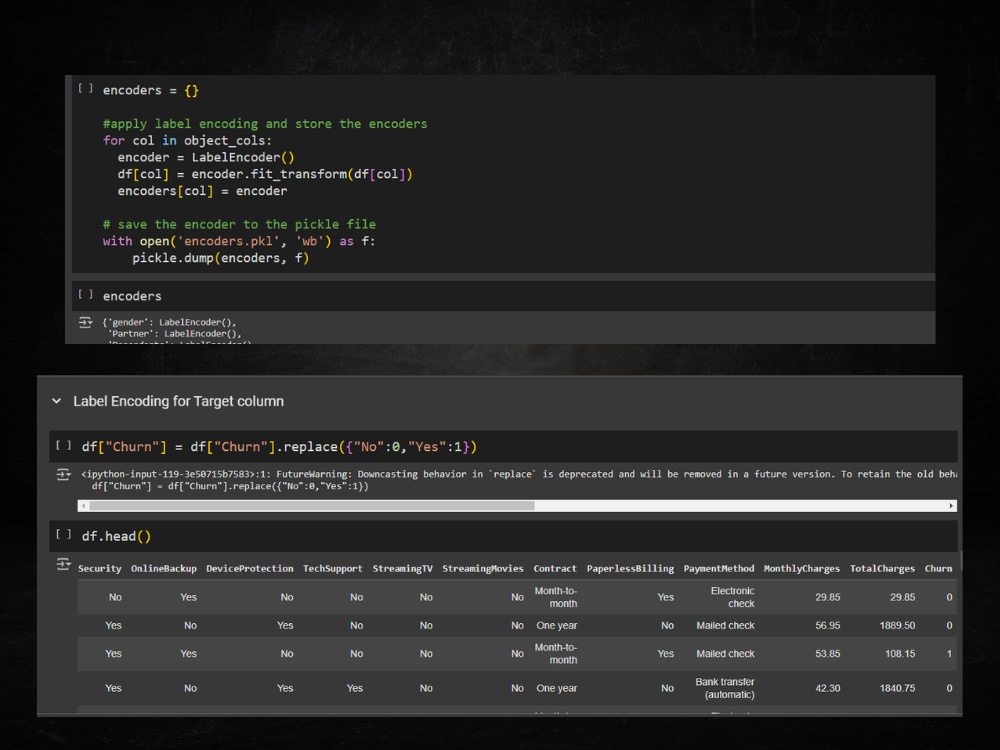
⚡Customer Churn Prediction: Built a Random Forest model to predict customer churn, addressing class imbalance with SMOTE and achieving high accuracy through robust cross-validation. Successfully deployed the model for real-time predictions using serialized pipelines.
⚡Delivered custom analytics solutions, dashboards, and predictive insights for various industries, driving data-informed decisions.
📌Please explore my portfolio to see examples of my work, including data science and machine learning projects across various domains. If you have any questions about how I can assist with your project, feel free to reach out—I’d be happy to help!
Steps for completing your project
After purchasing the project, send requirements so Sivanujan can start the project.
Delivery time starts when Sivanujan receives requirements from you.
Sivanujan works on your project following the steps below.
Revisions may occur after the delivery date.
Initial Review and Consultation.
Review the provided data and requirements. Communicate with the client to clarify any doubts and finalize the scope of work.
Data Preprocessing.
Clean and preprocess the dataset (e.g., handle missing values, normalize data, encode categorical variables).