You will get trained reinforcement learning, deep reinforcement learning agent


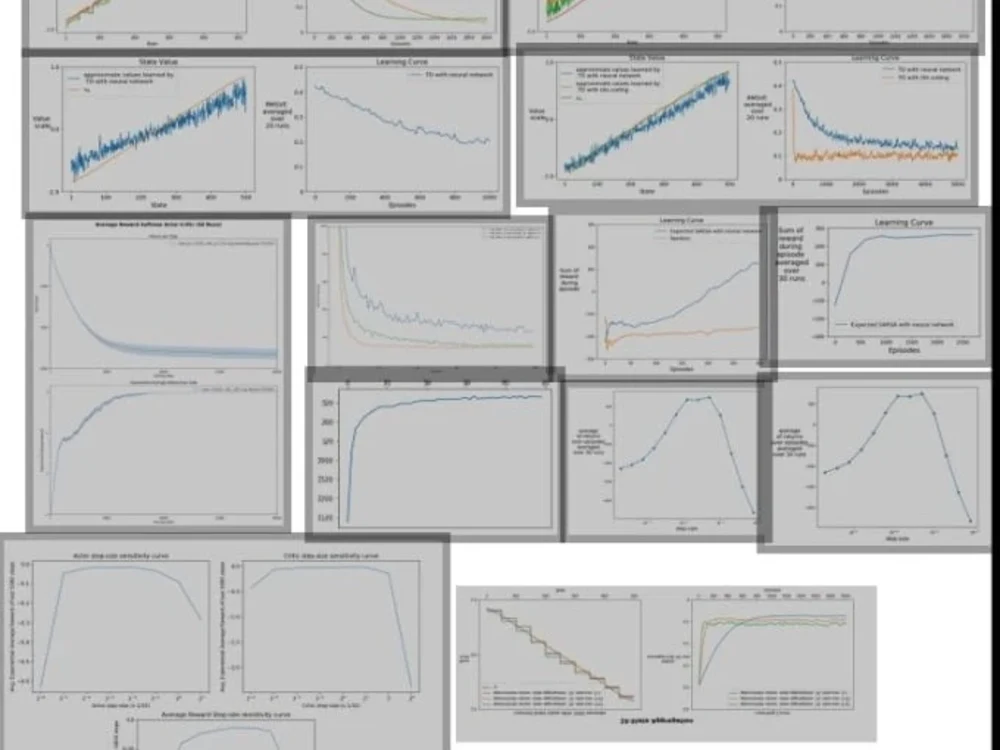
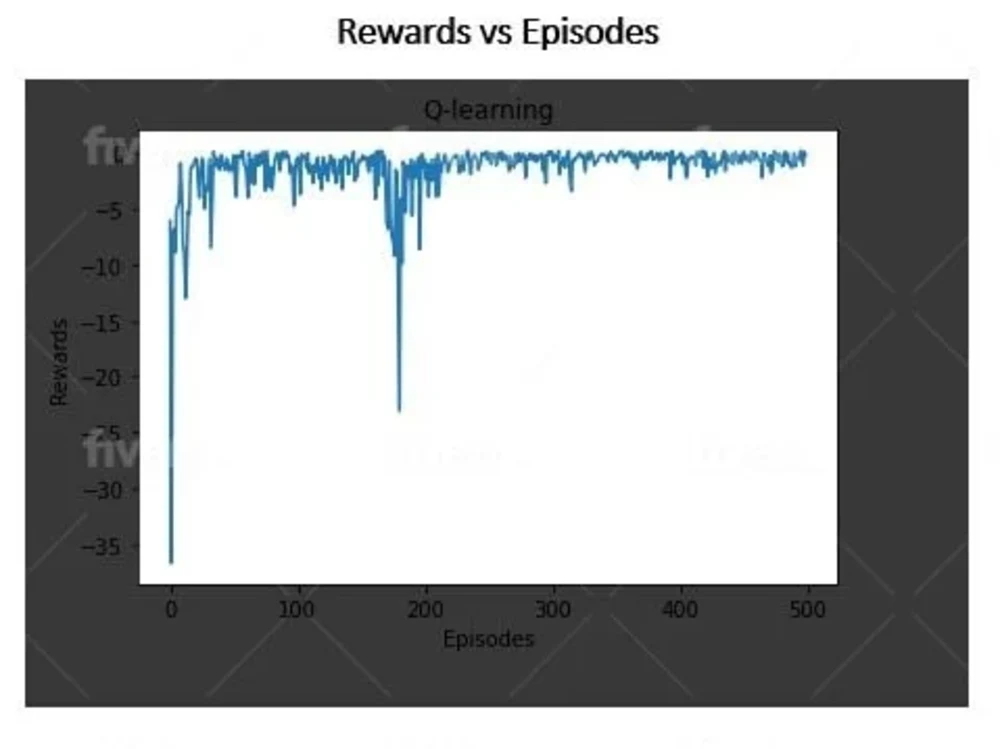
Project details
I am PhD deep learning, reinforcement learning and optimization. I have completed masters in robotics and control. I am managing a team of mathematicians and machine learning engineers.
I will train and optimize your GYM agent. GYM environment should be provided in working condition, along with the reward function. I will train agent in python and optimize agent performance. The algorithms included
SARSA, expected SARSA, SARSA lambda
Temporal difference (TD-0), semi gradient TD, TD-3
Q learning, Q learning lambda,
DYNA, DYNA Q, DYNA Q+
Gaussian policy parameterization (DPP)
deep Q networks (DQN), Double deep Q networks (DDQN)
policy gradient, soft actor critic (SAC)
neural fitted Q (NFQ),
trust region policy optimization (TRPO),
proximal policy optimization (PPO1, PPO2),
deep deterministic policy gradients (DDPO),
Actor-Critic Algorithm (A2C)
Q-Learning with Normalized Advantage Functions (NAF)
Twin Delayed Deep Deterministic Policy Gradient (TD3)
ACER, ACKTR, DDPG, GAIL, HER (3)
Feel free to discuss problem.
Regards
I will train and optimize your GYM agent. GYM environment should be provided in working condition, along with the reward function. I will train agent in python and optimize agent performance. The algorithms included
SARSA, expected SARSA, SARSA lambda
Temporal difference (TD-0), semi gradient TD, TD-3
Q learning, Q learning lambda,
DYNA, DYNA Q, DYNA Q+
Gaussian policy parameterization (DPP)
deep Q networks (DQN), Double deep Q networks (DDQN)
policy gradient, soft actor critic (SAC)
neural fitted Q (NFQ),
trust region policy optimization (TRPO),
proximal policy optimization (PPO1, PPO2),
deep deterministic policy gradients (DDPO),
Actor-Critic Algorithm (A2C)
Q-Learning with Normalized Advantage Functions (NAF)
Twin Delayed Deep Deterministic Policy Gradient (TD3)
ACER, ACKTR, DDPG, GAIL, HER (3)
Feel free to discuss problem.
Regards
What's included
| Service Tiers |
Starter
$150
|
Standard
$300
|
Advanced
$500
|
|---|---|---|---|
| Delivery Time | 7 days | 14 days | 20 days |
Number of Revisions | 1 | 2 | 2 |
Number of Model Variations | 1 | 2 | 3 |
Number of Scenarios | 1 | 1 | 1 |
Number of Graphs/Charts | 10 | 10 | 10 |
Model Validation/Testing | |||
Model Documentation | - | - | - |
Data Source Connectivity | - | - | - |
Source Code |
Optional add-ons
You can add these on the next page.
Additional Model Variation
(+ 5 Days)
+$150About Haris
Machine learning, Deep learning, Reinforcement learning, NLP, CV
London, United Kingdom - 7:04 am local time
******Deep learning specialization,
******Natural language processing specialization,
******Generative adversarial networks specialization,
******AI for medicine specialization,
******Reinforcement learning in finance specialization
******Reinforcement learning specialization.
********Reinforcement learning expertise************
Meta reinforcement learning, feature learning or representation learning, soft evolutionary methods (genetic algorithm, ant colony optimization etc.), dynamic programming, game theory, minmax, value iteration, policy iteration, inverse reinforcement learning and imitation game, MDP, MC, SARSA, expected SARSA, SARSA lambda, (TD-0,1,2,3), Q learning, DYNA, DQN, DDQN, SAC, TRPO, PPO, DDPO, A2C, A3C
Software: MATLAB, Python, c, c++
********NLP expertise************
sequence models, LSTM, open AI GPT-2 GPT-3, git, transformer networks, attention networks, chatbots, word2vec, GloVe, one shot learning, few shots learning, sequence to vector, vector to sequence and sequence to sequence models, Pytorch, Keras and Tensorflow.
********CV expertise************
CNN, YOLO V3, faster R-CNN, Transfer leaning, multi task learning, end to end deep learning, data augmentation.
Feel Free to discuss your project
Regards
Haris Mansoor
Steps for completing your project
After purchasing the project, send requirements so Haris can start the project.
Delivery time starts when Haris receives requirements from you.
Haris works on your project following the steps below.
Revisions may occur after the delivery date.
RL Agent Train and hyper parameters Tune
Will train RL agent and tune its hyper parameters.