You will get a production-grade AI engine that extracts structured data from your PDFs
Rising Talent



Project details
Every invoice, contract, and CV your team retypes by hand is a paid hour converted into latency and transcription error.
At scale, manual document entry quietly costs thousands per month in salary, introduces silent data errors into your accounting and CRM, and caps how fast you can actually operate. Worse, the backlog compounds — the documents never stop arriving, and every "we'll catch up next week" becomes another week of avoidable cost. You need this handled once, permanently, by infrastructure rather than people.
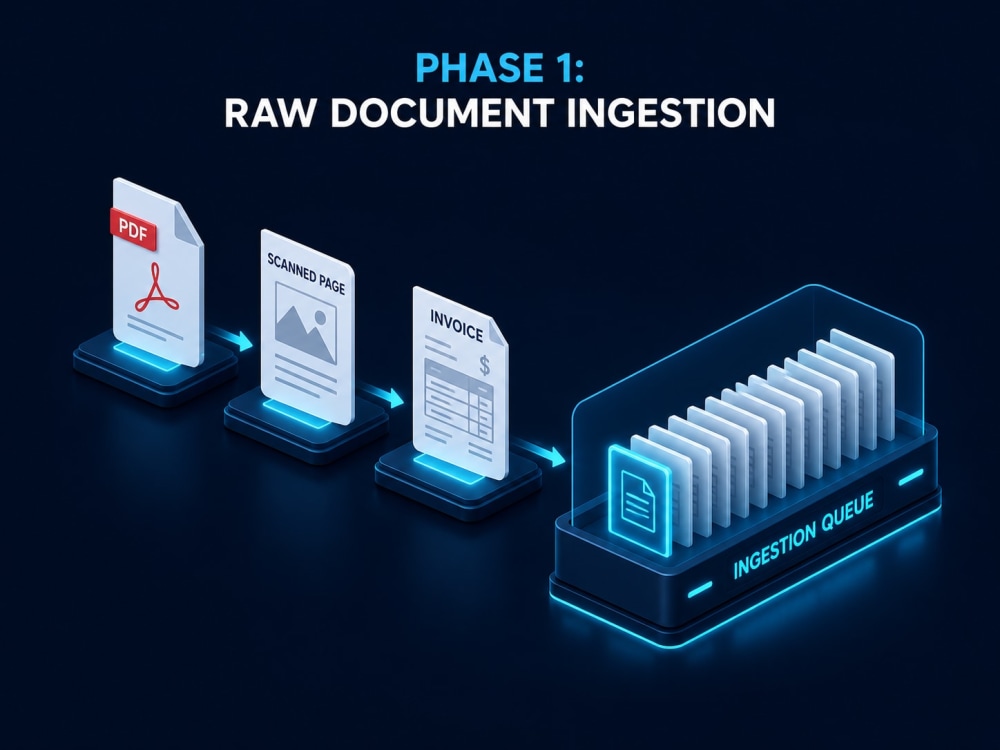
I build a production-grade AI document-processing engine: an asynchronous FastAPI service that combines layout-aware parsing (PyMuPDF/PDFPlumber) with a Tesseract OCR fallback for scans, then extracts your exact fields via LLM, validating every output against a strict Pydantic schema before it is returned. Malformed or low-confidence fields are rejected and re-queued, never silently delivered.
Security is non-negotiable: documents are processed in-memory with zero retention, GDPR/HIPAA-ready, and the engine runs on your own API keys — you own and see every cost. Output: clean JSON or Google Sheets, Dockerised for your infrastructure.
At scale, manual document entry quietly costs thousands per month in salary, introduces silent data errors into your accounting and CRM, and caps how fast you can actually operate. Worse, the backlog compounds — the documents never stop arriving, and every "we'll catch up next week" becomes another week of avoidable cost. You need this handled once, permanently, by infrastructure rather than people.
I build a production-grade AI document-processing engine: an asynchronous FastAPI service that combines layout-aware parsing (PyMuPDF/PDFPlumber) with a Tesseract OCR fallback for scans, then extracts your exact fields via LLM, validating every output against a strict Pydantic schema before it is returned. Malformed or low-confidence fields are rejected and re-queued, never silently delivered.
Security is non-negotiable: documents are processed in-memory with zero retention, GDPR/HIPAA-ready, and the engine runs on your own API keys — you own and see every cost. Output: clean JSON or Google Sheets, Dockerised for your infrastructure.
AI Development Type
Knowledge Representation, Software MaintenanceAI Tools
Google AutoMLAI Development Language
PythonWhat's included
| Service Tiers |
Starter
$190
|
Standard
$590
|
Advanced
$980
|
|---|---|---|---|
| Delivery Time | 2 days | 4 days | 7 days |
Number of Revisions | 1 | 2 | 3 |
AI Model Integration | |||
Detailed Code Comments | - | ||
Knowledge Graph | - | - | |
Model Documentation | - | ||
Ontology | - | - | |
Source Code | |||
Taxonomy | - | - |
Optional add-ons
You can add these on the next page.
Fast Delivery
+$60 - $300Frequently asked questions
About Leon
I build AI agents that generate results.
Paris, France - 5:27 pm local time
I don’t build generic chatbots. I architect high-performance, automated systems that turn raw data into qualified leads, eliminate manual operations, and drive revenue.
If your team is spending hours scraping data, manually scoring leads, or moving info between tools—I automate it.
What I Do Best:
• End-to-End Automation: Python, robust APIs, and custom workflows.
• Advanced Claude API Integration: Daily production-level deployment of Anthropic’s models for complex reasoning, classification, and extraction.
• Intelligent Lead Gen Pipelines: Automated discovery, enrichment, and predictive scoring.
• Rapid Prototyping: Turning a manual business process into a functional AI-driven prototype in 7–14 days.
Recent Production Work:
• Autonomous Lead Generation System: Integrated Firecrawl, Claude API, and Notion to extract, filter, and enrich high-value prospects automatically.
• Multi-Agent Automation Framework: Developed a scalable architecture (OpenClaw) for parallel task execution.
• AI Scoring & Filtering Pipelines: Built semantic filtering systems to eliminate low-quality data before it hits the CRM.
Why Clients Hire Me:
• Business-First Focus: I don't write code for the sake of code. I build to save you hours and generate revenue.
• Claude API Specialization: Deep operational knowledge of prompt caching, system prompts, and context window optimization.
• High Velocity: I ship production-ready solutions in days, not months.
Availability:
Summer 2026 Focus (June–August). I am taking on 1 to 3-month contracts where I can deeply focus on your architecture and deliver immediate velocity.
Let’s transform your manual bottlenecks into automated revenue. Click "Invite to Job" to discuss your workflow.
Steps for completing your project
After purchasing the project, send requirements so Leon can start the project.
Delivery time starts when Leon receives requirements from you.
Leon works on your project following the steps below.
Revisions may occur after the delivery date.
Schema Alignment & Sample Review
You share 5–10 representative documents and your target field list. I confirm the exact output schema, edge cases, and OCR needs, then lock a validated Pydantic model before any build begins.
Extraction Engine Build & Validation Layer
I build the async FastAPI pipeline: layout-aware parsing plus OCR fallback, the LLM extraction prompt, and the Pydantic validation gate that rejects and re-queues any field failing type, format, or confidence checks.